paper_readings
 paper_readings copied to clipboard
paper_readings copied to clipboard
Published
20 hours ago •
 DwangoMediaVillage
DwangoMediaVillage
Voice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks
conditional VAEで音声embeddingを獲得し、転写することで音声変換を行う。更にWGANを使ってクリアな音声を目指す。
論文本体・著者
- Chin-Cheng Hsu, Hsin-Te Hwang, Yi-Chiao Wu, Yu Tsao, Hsin-Min Wang
- arXiv: https://arxiv.org/abs/1704.00849
- demo: https://jeremycchsu.github.io/vc-vawgan/
- Interspeech 2017 Poster
解きたい問題
- 対応関係のないデータを使っての音声変換
新規性
- この分野でWGAN(Wasserstein GAN)を使った点
実装
-
入力は2種類
- 過去文献と同じ音響特徴量x
- 話者のOneHotベクトルy
-
ネットワークは3種類
- 音響特徴量xから潜在変数zを推定するEncoder
- 話者ラベルyとzから音響特徴量を推定するGenerator(Synthesizer)
- xや推定されたx'からWasserstein距離を推定するDiscriminator
 |
|---|
| 論文 Algorithm. 1 より |
- パラメータは3種類
- Φ: Encoderのパラメータ
- φ: Discriminatorのパラメータ
- θ: Generatorのパラメータ
- ロスは3種類
- J_obs: xとx'の対数尤度(らしいけど実装は不明)
- J_lat: zとN(0,1)のKL距離
- J_wgan: WGANのロス
- WGANに入力するx'には、xから推定したzと、xに非対応のyから推定したものを用いる
実験・議論
- データ関連
- データセットはVoice Conversion Challenge 2016 dataset
- 入力音響特徴量xはスペクトル包絡512次元、非周期性指標512次元、基本周波数1次元
- 話者数は3人
- ネットワーク
- 全部CNN
- 詳細は書かれていないが、デモ用のgithubのファイルからなんとなく分かる
- 全部CNN
- デモサイトで実際に聞ける
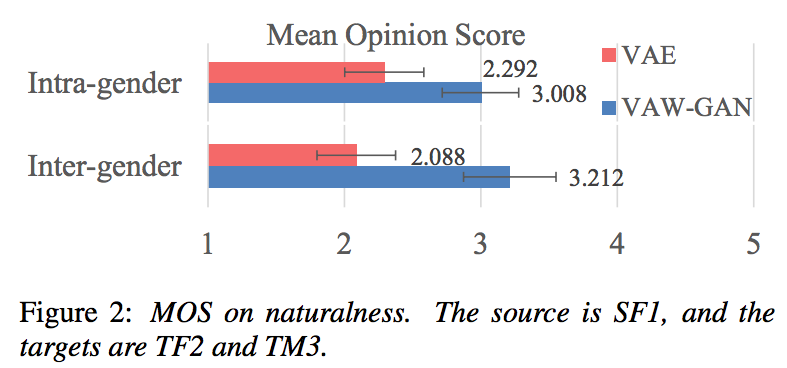 |
|---|
| 論文 Fig. 2 より |
- 5段階評価実験
- VAEに比べて良くなった
読んだ中での不明点などの感想
- 不明点
- ネットワーク構造が全く書かれておらず、追実験が不可能
- WGANを使った理由が不明瞭
- 文中の説明だと、WGANではなくGANを使っても解決できそうだった
- その他の感想
- 非対応の音声データを使った音声変換タスクを解決した論文を読んでみたかったが、今見れるものだと音響特徴量を変換するようなものしか見つからなかった
- Interspeech2017で発表予定のDeepLearing論文を探したが、arXivで読めるのがとても少ない
- 早く音声分野にもarXivに論文を投稿する文化が広まってほしい
- ネットワーク図がなくて読みづらい
- 早く他の論文も読みたい。Interspeech 2017の開催が待ち遠しい。
- 非対応の音声データを使った音声変換タスクを解決した論文を読んでみたかったが、今見れるものだと音響特徴量を変換するようなものしか見つからなかった
関連論文
このタスクは、ターゲット側の話者が1人であることを前提に組まれていると思います。 Jwganにはターゲット側の正解データと生成データのみが与えられるため、yの入力が不要になります。