IMS-Toucan
 IMS-Toucan copied to clipboard
IMS-Toucan copied to clipboard
Fix for Hugging Face Spaces: PoeticTTS SpeechCloning doesn't work
@Flux9665
Hi, I tried to fix the two spaces that you have on hugging face:
https://huggingface.co/spaces/Flux9665/PoeticTTS https://huggingface.co/spaces/Flux9665/SpeechCloning
After trying to fix PoeticTTS, the output sound are bird / mikey mouse like: https://huggingface.co/spaces/trholding/PoeticTTS
The changes were: Unversioned requirements.txt. Updated packages.txt Updated app.py to clone master. Logs don't show errors.
Similarly Speech Cloning also outputs mikey mouse / bird like audio: https://huggingface.co/spaces/trholding/SpeechCloning
The changes were:
Unversioned requirements.txt. Updated packages.txt. Updated app.py that clones master changes: save_img_for_debug=None on line 208,
"alignment.png", \ to "Utility/toucan.png", \ on line 171
I did that to fix some errors related to mathplot, missing file, url lib etc. Logs don't show errors.
Update: Sort of fixed when I changed sample rate to 24khz. However the cloning output is a bit degraded towards the end of each sentence.
great, thank you for your help in fixing this! I noticed the spaces were down a while ago, but didn't have time to figure out a way to get them back up, especially since there was no apparrent reason why they ceased to work in the first place after working without problems for a very long time.
Yes that's a hugging face mystery. Locally it was working without problems. Thank you, for the awesome work on this. The best TTS I have tested so far.
I have an issue with voice cloning / run_prosody_override.py locally, it outputs very distorted and unrecognizable sound.
I should probably spend some time documenting this script, I think people are often confused about what the inputs are supposed to be. Maybe it's the same problem in your case? The reference audio should be an audio of a speaker that reads out the exact same text with a desired prosody (i.e. stuff like the intonation). The TTS will then read the text with the exact same intonation as the reference audio, but with the voice that is currently set as default. To do just voice-cloning without also cloning the prosody of a specific utterance, you can just instanciate a ToucanTTSInterface form the InferenceInterfaces and use the set_utterance_embedding method to change the voice of the TTS.
In case that this is not the issue, I would need some more details about what you want to clone to be able to help
I just made two changes to the utterance cloner and the associated example script, I hope this makes the expected inputs clearer
@Flux9665
I noticed the spaces were down a while ago, but didn't have time to figure out a way to get them back up, especially since there was no apparrent reason why they ceased to work in the first place after working without problems for a very long time.
Locally the figures wouldn't work. Gradio errors. My problems with the interface went away when I switched away from gradio to streamlit. And that meant also less code to type / more readable.
The reference audio should be an audio of a speaker that reads out the exact same text with a desired prosody I think this was my problem. I spoke something else and the text was something else.
Thank you for the update. I'll check it out.
I have built a any language to any language STT -> Translation -> TTS pipeline using whisper, NLLB and IMS-Toucan
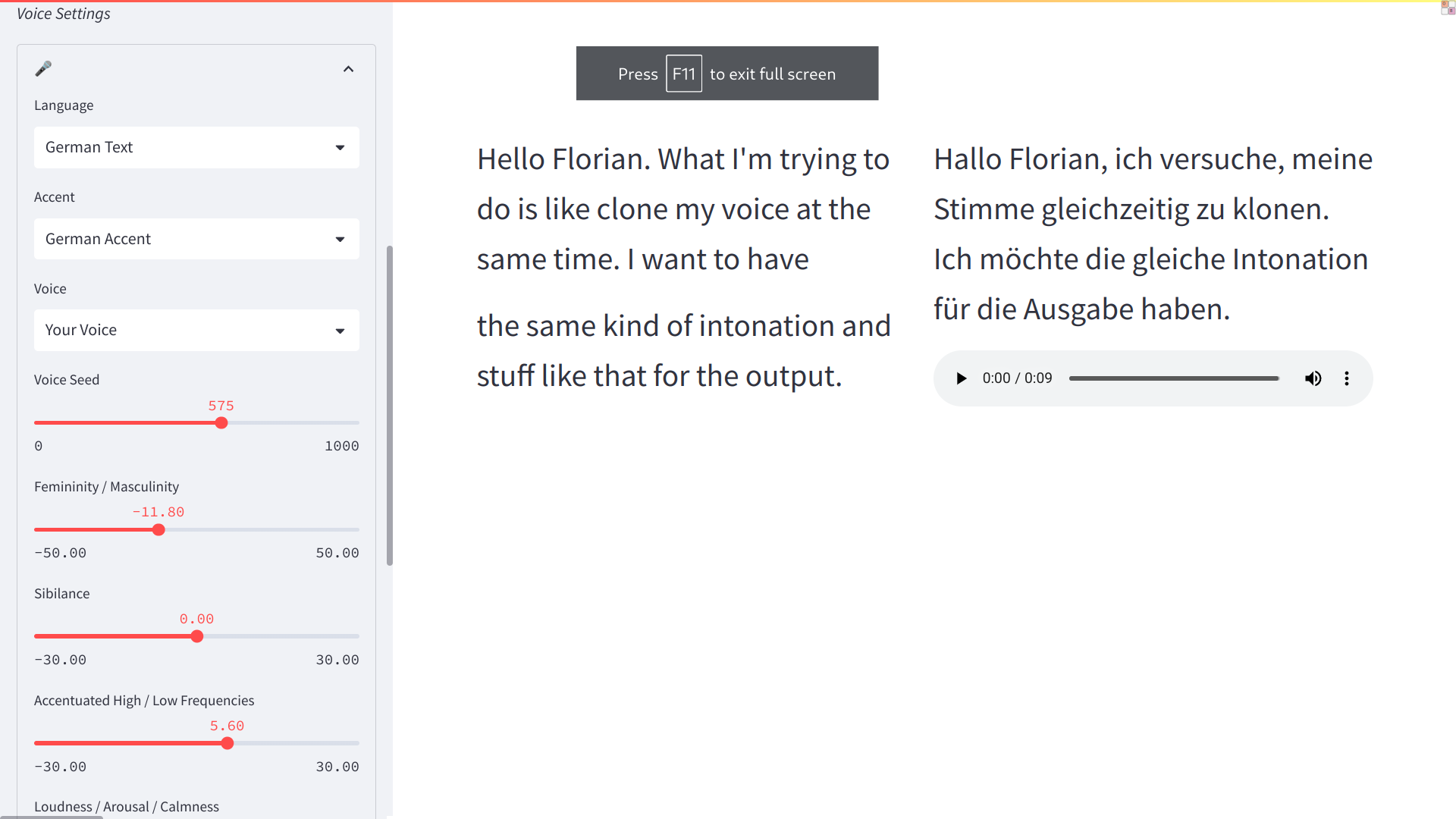
One problem, is that the voice is not an exact clone. I used 20s and 10s voice samples. The output that I have uploaded is the result of that clone. Sounds about 50% different from my voice. How do I get this right? Output sample: dddd5c0b72718374cdaa45221858e088d64ac3861f0f159a00cbd146.zip
One thing is clear from your clarification is that prosody override would not work because input audio is english, text is german.
I have further experimented with toucan. Surprisingly, gets stuff almost right when I use Asian and Indic languages by just changing accent to Spanish, Portuguese or Italian and playing with the knobs. Probably has to do because you use phonemes and espeak-ng does that part well.
https://github.com/snakers4/silero-models has a lot of models for many languages which sound good, maybe the same data could be used to add / train more languages to Toucan?
I recommend that you get research access to Google TPUs for faster training if you plan to add languages. I got access when I requested it.
There are some more use cases I've found for toucan which are research worthy. I have also ideas to speed up this on low resource devices. I'll add them as new issues/suggestions/feature requests.
A very late update on this: I'm currently trying to make the voice cloning / speaking style cloning much better, so this would hopefully also benefit your use case. Those changes are however still experimental and they don't work well at all yet. Once I manage to find a good setup, there will be a new release.