go-tilde-operator
 go-tilde-operator copied to clipboard
go-tilde-operator copied to clipboard
PoC: How to make ~ work on Go Compiler
Auto-generated by mediumexporter
Contributing the Go Compiler: Adding New Tilde (~) Operator
Compilers have always had challenges to be solved, even today. Go is not so different too. There are so many things to do, so many problems to solve, so many features to implement… That’s why there is no such thing as “OK, this compiler is fully completed.”. It is almost impossible to say. In these years, we are actually so lucky that we have the opportunity to witness how legacy compiler structures are being restructured, improved, and increased efficiently together with the applying of modern approaches and solutions.
My obsession with compilers began while trying to write a simple memory reader with AutoIt for Silkroad Online. Something was somehow working perfectly integrated with the grace of God. So, how do they do it? I knew it would take me years to answer this question. But, it shouldn’t have been left unanswered. There are so many things to learn before digging into compilers. Missing or not knowing any of this information may be a major obstacle to our learning process. From CPU scheduling to Memory management, from logic design to instruction set architecture… Remember that we are trying to climb an enormous tree with an infinite number of branches. The soil of this tree is physics, obviously. I have learned that I still have a lot to learn.
Especially in the last two years, I had the opportunity to think a lot about compilers due to the pandemic. I have read many articles, papers, took a lot of notes, lot of trying. Monkey, which is one of the sources that inspired me. Do you like Monkey? Thorsten Ball did. Somehow, I came across an excellent book called “Writing A Compiler In Go”. After implementing the whole book in Rust, I immediately found the opportunity to clone the Go source code to examine further and strengthen the knowledge. In this learning process, an idea came to my mind that could answer questions such as “What have I learned?, What will I learn?, What I would like to learn?” and that I would enjoy sharing what I learned with you. Then I tried to write this article as much as I could. Do not forget to bring your coffee and background music with you. It is going to be a bit long journey.
Abstract
This study conceptualizes, examines, and aims the implementation process for a bitwise complement operator ~ (pronounced as tilde) in Go. Even though this article does not follow any official Go proposal, it will provide a guideline for writing a technical proposal for this operator initially. This article will describe a set of specific instructions for the step-by-step learning of the full implementation process.* *The first chapters will provide a brief introduction about Compiler Front-Ends and Compiler Back-Ends and describe the Tokenizer, Abstract Syntax Tree (AST), Parser, Scanner and deep-dives to more Compiler Back-End parts of Op-Code, Intermediate Representation (IR), Static Single Assignment (SSA), architecture-based code generation, architecture based optimizer rules, and finally introduces a brand-new tilde operator. This background information lays the groundwork for the implementation of the operator in subsequent chapters.
Motivation
Currently, Go does not have support for the~ unary operator. Neither implemented in the original frontend. I could find neither an actively discussing issue nor a PR. If you would ask why humankind on Earth who writes Go code needs an ~ operator: Why not? It is a great opportunity to learn compiler theory and start contributing to Go.
I have never contributed to Go before. Together, we will learn how to contribute. In doing so, we will follow Go’s official documentation step by step. We will get feedback from the proposal that we are going to open up. Or maybe it will just be closed. But what we are aiming for is not whether the proposal we are doing got accepted or not. The point is to be able to do something educational and learn the process.
Actually, I do not know if we are going to do it correctly. But we can improve our implementation by getting feedback from the maintainers and the contributors.
**P.S.: **While I started writing this work, there is no such operator called Tilde. I just wanted to pull the latest commits from the master branch. What did I see? This operator has been added by griesemer. :( Yep, I couldn’t first :) So, I updated this post consequently.
Table of Contents
1.⠀Introduction ⠀1.1.⠀Becoming a Contributor ⠀1.2.⠀Preparing Environment ⠀1.3.⠀Writing Proposal 2.⠀Compiler Front-End ⠀2.1.⠀go/* (Legacy) ⠀⠀2.1.1.⠀Token ⠀⠀⠀2.1.1.1. Operator Precedence ⠀⠀2.1.2.⠀AST ⠀⠀2.1.3.⠀Scanner ⠀⠀2.1.4.⠀Parser ⠀⠀2.1.5.⠀Constant ⠀⠀2.1.6.⠀Math ⠀⠀2.1.6.1.⠀big.Int ⠀2.2.⠀cmd/compile ⠀⠀2.2.1.⠀Differences with go/* ⠀⠀2.2.2.⠀Creating Test Script ⠀⠀2.2.3.⠀Token ⠀⠀⠀2.2.3.1.⠀Operator String ⠀⠀⠀2.2.3.2.⠀Stringer ⠀⠀2.2.4.⠀Scanner ⠀⠀2.2.5.⠀Parser 3. Compiler Middle-End ⠀3.1.⠀Intermediate Representation ⠀⠀3.1.1.⠀Node ⠀⠀3.1.2.⠀Expr ⠀3.2.⠀Escape Analysis ⠀3.3.⠀Walk ⠀3.4.⠀Constant ⠀3.5.⠀Math ⠀⠀3.5.1.⠀big.Int 4.⠀Compiler Back-End ⠀4.1.⠀Introduction ⠀4.2.⠀Static Single Assignment (SSA) ⠀4.3.⠀Go’s SSA Backend ⠀4.3.1.⠀Generic OPs ⠀4.3.2.⠀Rewrite Rules 5.⠀Result ⠀5.1.⠀Trying New Operator ⠀5.2.⠀Test & Build Go Compiler 6.⠀Conclusion 7.⠀Furthermore 8.⠀References ⠀8.1.⠀Normative ⠀8.2.⠀Informative
1. Introduction
Programming languages are not magical. They were built by blood, sweat, and tears. We may do not know what kind of difficulties they had been going through. What we know about them is that every single language “just works”. Have you ever asked yourself “how”? Well, never mind, neither did I. But instead, I rather keep telling myself, “It is more important the know how something can be created from scratch” rather than “How it works?”. If we knew “How to create something”, it would be easier for us to understand *“How it works?”. *Moreover, we can have the skills and knowledge to answer this question ourselves. Let’s move on to what we’re going to do without too much noisy talk. We are not going to release a book at the end of the day, are we?
What we will be achieving in this article is such a brand-new tilde ~ operator in Go. So, first things first, we are going to write an educational proposal by opening an issue at GitHub. Then, we will prepare our build environment, and we follow the Go contribution guideline, open-source culture, and standards.
We can consider this article in two parts in general: Compiler Front-End and Compiler Back-End. In the Compiler Frond-End section, we will see what an Abstract Syntax Tree (AST) is, extract AST using Scanner, what Tokens are, how tokens are read by Parser and create meaningful statements… In the Compiler Back-End section, we will start implementing core logic, a.k.a. One’s Complement (bitwise not), Op-Code with auto code generation. Then, we will touch SSA a bit for creating architecture-based optimizer rules (i.e., RISCV64, Generic). Finally, we will deep dive into the Go Compiler universe for the final touches. Let the party begin!
1.1. Becoming a Contributor
The Go project welcomes all contributors. The first step is registering as a Go contributor and configuring your environment. Here is a checklist of the required steps to follow: [0]
-
Step 0: Decide on a single Google Account you will be using to contribute to Go. Use that account for all the following steps and make sure that git is configured to create commits with that account's e-mail address.
$ git config --global user.email [email protected]
-
Step 1: Sign and submit a CLA (Contributor License Agreement).
-
Step 2: Configure authentication credentials for the Go Git repository. Visit go.googlesource.com, click “Generate Password” in the page’s top-right menu bar, and follow the instructions.
-
Step 3: Register for Gerrit, the code review tool used by the Go team, by visiting this page. The CLA and the registration need to be done only once for your account.
-
Step 4: Install git-codereview by running go get -u golang.org/x/review/git-codereview
1.2. Preparing Environment
-
Step 1: Clone the source code
$ git clone https://go.googlesource.com/go $ cd go
Clone anywhere you want as long as it’s outside your $GOPATH . Clone from go.googlesource.com (not GitHub).
-
Step 2: Prepare changes in a new branch
$ git checkout -b feature/new-operator-tilde
We will work on the feature/new-operator-tilde branch that checked out from the default working branch.
-
Step 3: Verify the compilation succeed
$ cd ./src $ ./make.bash # use ./all.bash to run the all tests
Building Go cmd/dist using /usr/local/Cellar/go/1.16.3/libexec. (go1.16.3 darwin/amd64) Building Go toolchain1 using /usr/local/Cellar/go/1.16.3/libexec. Building Go bootstrap cmd/go (go_bootstrap) using Go toolchain1. Building Go toolchain2 using go_bootstrap and Go toolchain1. Building Go toolchain3 using go_bootstrap and Go toolchain2. Building packages and commands for darwin/amd64.
Installed Go for darwin/amd64 in /Users/furkan/src/public/go Installed commands in /Users/furkan/src/public/go/bin
gtime: 253.04user 40.64system 0:58.38elapsed 503%CPU
Make sure go is installed in your shell path so that the go toolchain uses the Go compiler itself.
The project welcomes code patches, but you should discuss any significant change before starting the work to ensure things are well coordinated. [1]
So, this is exactly what we will do as a next step.
1.3. Proposing
The crucial step is that before we start doing anything, we need to write down what we will achieve at the end of the day. It may not be right to work and make decisions alone. We can not do random walks on such a large company or community-driven big open-source projects, right?. We cannot just randomly write a sloppy proposal. Since the Go project’s development process is design-driven, we must follow the proposal design document standards.
We can create an issue to discuss the feature idea just before we start writing the actual proposal. Since we will not do compiler change but small implementation, it's OK to create the proposal as an issue by following the TEMPLATE.
Title: proposal: spec: add built-in tilde ~ (bitwise not) unary operator **Description: **TL;DR: I propose adding built-in support for ~(bitwise not) unary operator. **Abstract The ~ operator (pronounced as tilde) is complement (unary) operator, performs a *bitwise NOT operation. It takes one bit operand and returns its complement. If the operand is 1, it returns 0, and if it is 0, it returns 1. When applied on numbers, represented by *bitwise not, it changes the number’s sign and then subtracts one. [2] For example: 10101000 11101001 // Original (-22,295 in 16-bit one's complement) 01010111 00010110 // ~Original (22,294 in 16-bit one's complement) I propose the addition of a new built-in ~ operator. Motivation Currently, Go does not have support for ~ operator. I could find neither an actively discussing issue nor a PR. It is a great opportunity to learn compiler theory and get used to Go compiler internals. Backgroud Tilde ~ operator widely implemented and used by some programming languages. (i.e. Python, C/C++, Java, Rust (!), etc.). Can be used for different purposes in every programming language. We can start implementing this as a unary operator. In the some programming languages, the tilde character is used as bitwise NOT operator, following the notation in logic: ~p not means not p, where p is a proposition. **Proposal I propose that ~ should work like any other bitwise operator as described in the spec. We will only support *prefix notation usage on integers. i.e. ~EXPR . Following codes should compile successfully: ** *~1997 // returns -1998
- a := 7 and ~a // returns -8
- *~-15 *// returns 14
- *-~15 *// returns 16
- foo := func(x int) int { return ~x } and ~foo(707) // returns -708
- if ~7 < 5 { // true }
- ~3.1415 // INVALID
- x ~= y // INVALID
- ~bool // INVALID
- 5~7 // INVALID
- 7~ // INVALID Since the bitwise logical and shift operators apply to integers only, [3] I propose that we will support only integers.*
***Compatibility *This change is fully backwards compatible. ***Complexity *Since we will add just another single unary operator to the compiler, I think it will not cause even the tiny complexity. Tilde ~ just one of the unary operation standards in mathematics. The compiler already supports other bitwise operations. (i.e. &, | ,^, &^) *Implementation At a minimum this will impact:
- spec: add operator to relevant part
- compiler frontend: add new Token, update Scanner and Parser
- compiler backend: add OpCode, update SSA and GC
- optimization: i.e. ~(~7) = 7
- docs: the tour, all educational resources
*We will be implementing this operator on a [W.I.P] PR simultaneously by writing a “Contribution the Compiler Guide” on Medium.
***Furthermore **After implemented for integers, we may also add different features for this operator, in the future:
- *indicating type equality or lazy pattern match
- object comparison
- array concatenation
- … and so on.
2. Compiler Front-End
We all know that almost every website has a back-end service architecture. Compilers are not so different either, just like we humans read the texts with our eyes and send them back to the visual cortex in our brains. We are not going to go deep into technical details here. Let’s take a brief overview of some important parts. We will explain them all individually.
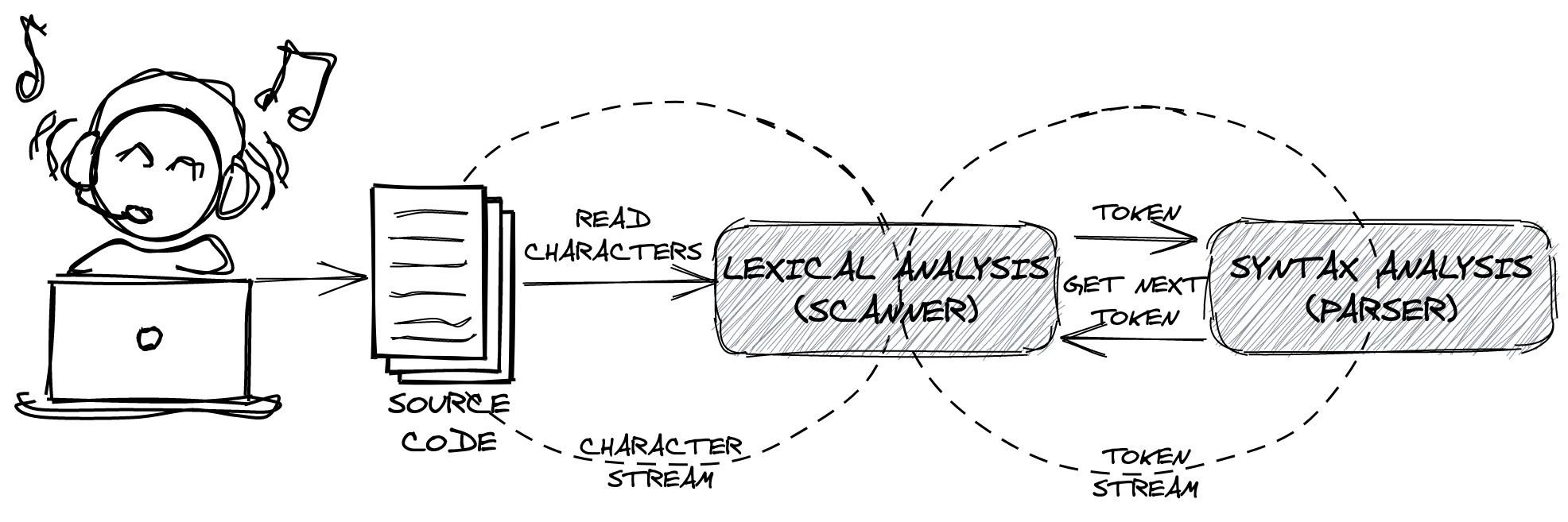 High-Level Overview of Compiler Front-End
High-Level Overview of Compiler Front-End
All front-end analyzers (i.e., lexical, syntax) analyze the source code to build an Intermediate Representation (IR) program. An Intermediate Representation is the data structure used internally by a compiler to represent source code, which is conducive to further processing, such as optimization and translation.
The frontend was originally developed at Google, and was released in November 2009. It was originally written for GCC. It was originally written by Ian Lance Taylor
Now we can choose our favorite Go editor (i.e., Vim, GoLand, etc.) to move forward. I will go with Emacs in this demo.
Find the Go spec packages under ./src/go. We will start implementing the token package.
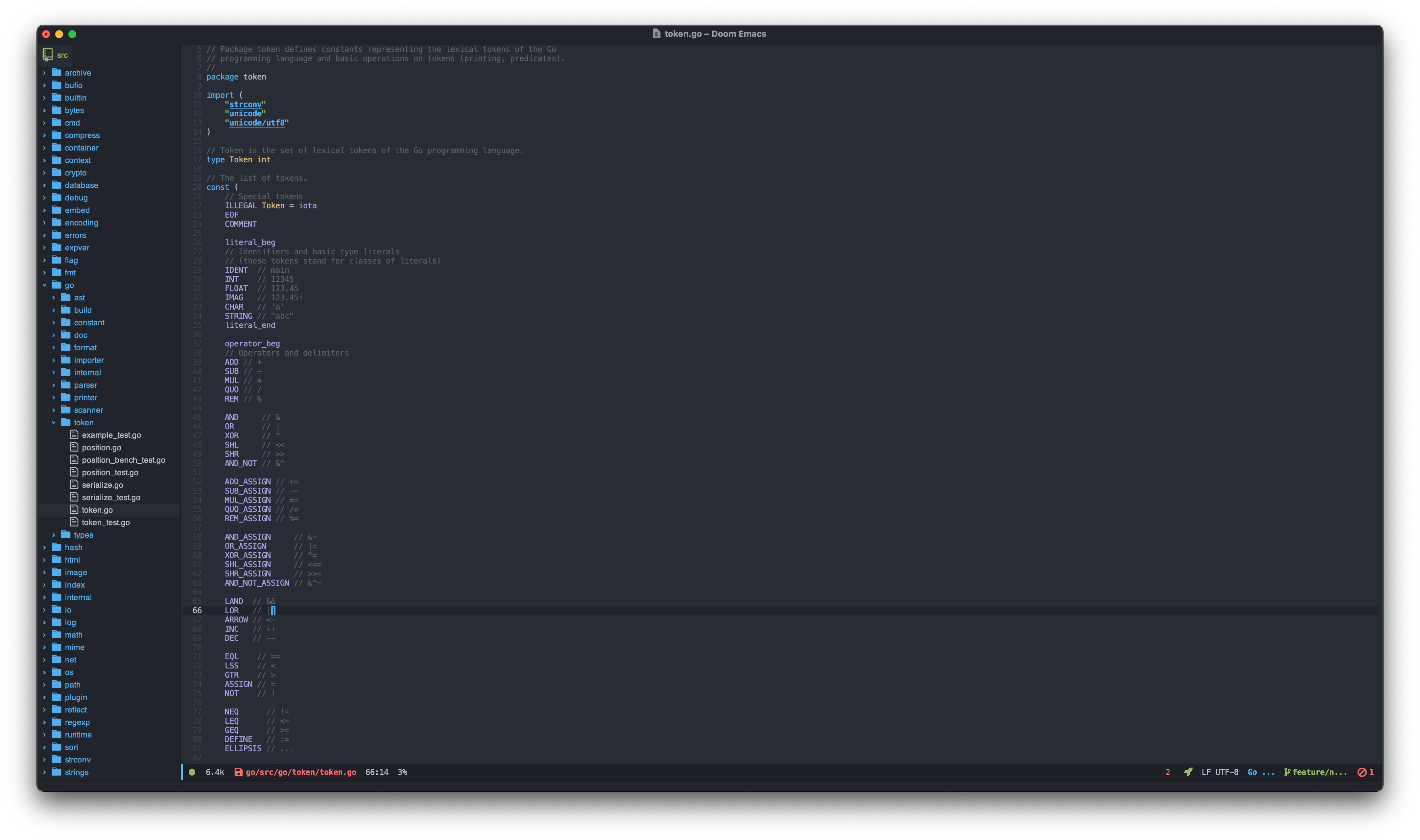 Editor Overview in Package of token
Editor Overview in Package of token
2.1.⠀go/* (Legacy)
2.1.1. Token
ELI5: Tokens are the smallest cornerstone in the compiler design. Those units add meaning to the source code that we are writing. This is the most important difference that distinguishes programming languages from our daily speaking languages.
Speaking Language:

Programming Language:

Tokens are highlighted in blue. Tokens themselves are small, easily categorizable data structures that are then fed to the parser.
Let’s suppose we replace these words with the Go correspondences:
The: func
quick: foo
brown: var1
fox: string
jumps: var2
over: int
the: error
lazy: bool
dog: true
Yes, just like you thought! We created meaning by using tokens in the sentence we wrote following the above. The tokens we use here are: “‘(‘, ‘,’, ‘)’, ‘{‘, ‘}’” , respectively.
OK, we are going to write our first code in this section. Let’s change the current directory to the token. In the token.go, we have to define our new token as a *const *variable:
We will define it as TILDE, as CPython did.
const (
// Special tokens
ILLEGAL Token = iota
...
SHR // >>
AND_NOT // &^
TILDE // ~
...
)
var tokens = [...]string{
ILLEGAL: "ILLEGAL",
...
SHR: ">>",
AND_NOT: "&^",
TILDE: "~",
...
}
2.1.1.1. Operator Precedence
Operator Precedence represents the order of operations, which should make clearer what operator precedence describes: which priority do different operators have.
A canonical example:
1 + 3 – 5 * 7 / ~9
Which will become:
1 + (3 — ((5 * 7) / (~9)))
That’s because the * and / operators have higher precedence (rank). It means that these are *more significant *than the + and — operators. These must get evaluated before the other operators do.
Operators that have the same precedence are bound to their arguments in the direction of their associativity. For example, the expression a = b = c is parsed as a = (b = c)And not as (a = b) = c because of right-to-left associativity of assignment, but a + b — c is parsed (a + b) — c and not a + (b — c) because of the left-to-right associativity of addition and subtraction. [5]
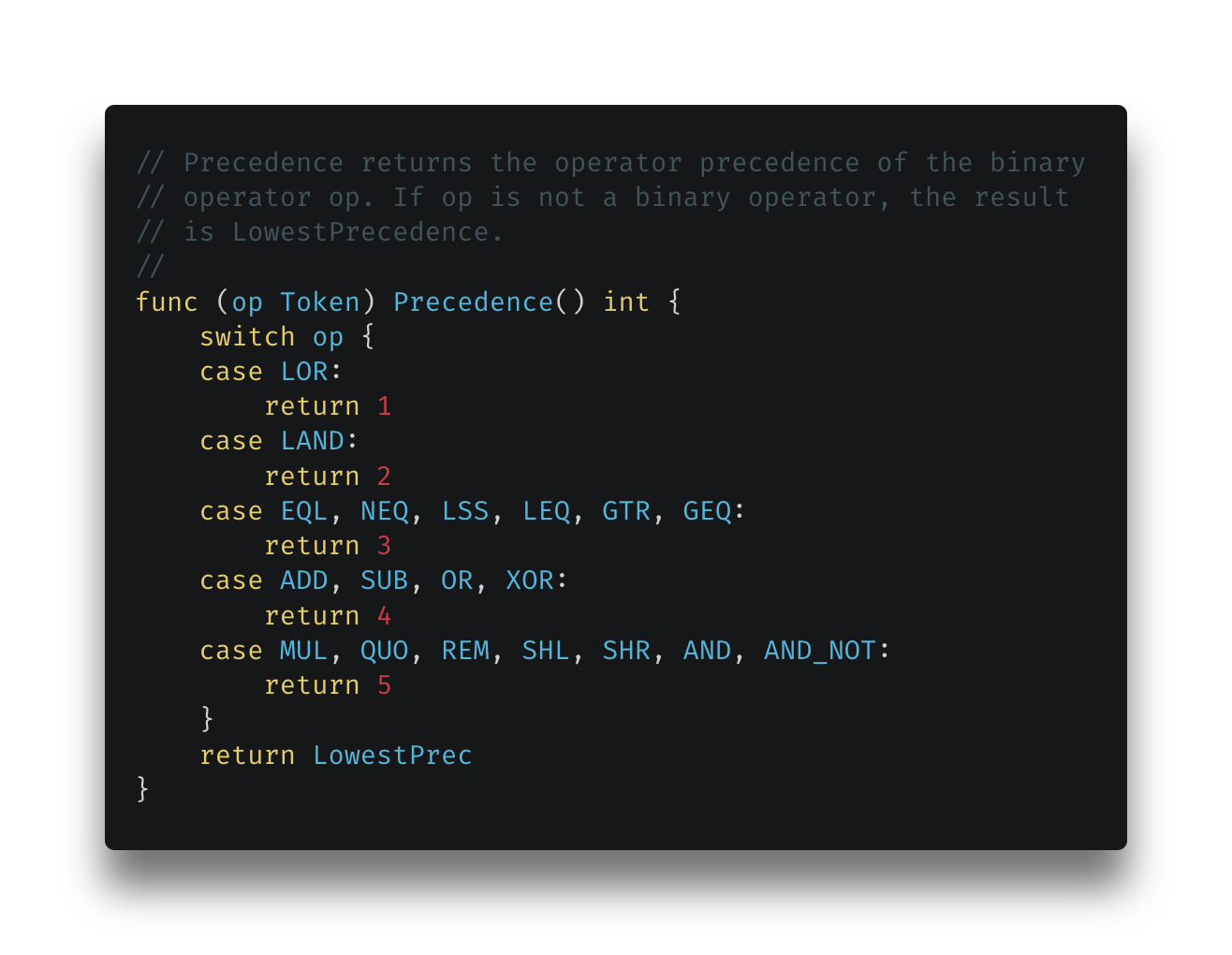
Python has defined at the FACTOR level in the *unary operator precedence table*. Unary FACTOR level simply means:
-7, +7, ~7
We can define TILDE at level 5:
func (op Token) Precedence() int {
switch op {
...
case MUL, QUO, REM, SHL, SHR, AND, AND_NOT, TILDE:
return 5
...
}
2.1.2. Abstract Syntax Tree (AST)
Abstract Syntax Tree (AST) is a tree that represents the syntactic structure of a language construct according to our grammar definition. It basically shows how your parser recognized the language construct, that said, it shows how the start symbol of your grammar derives a certain string in the programming language.
Let’s write a simple Go snippet:
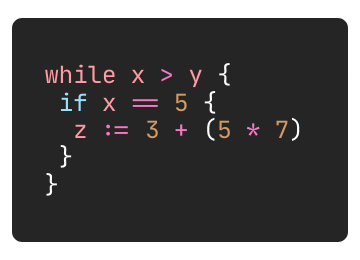 Go Code Snippet
Go Code Snippet
If we wanted to get the *AST *at high-level, we would get something like the following:
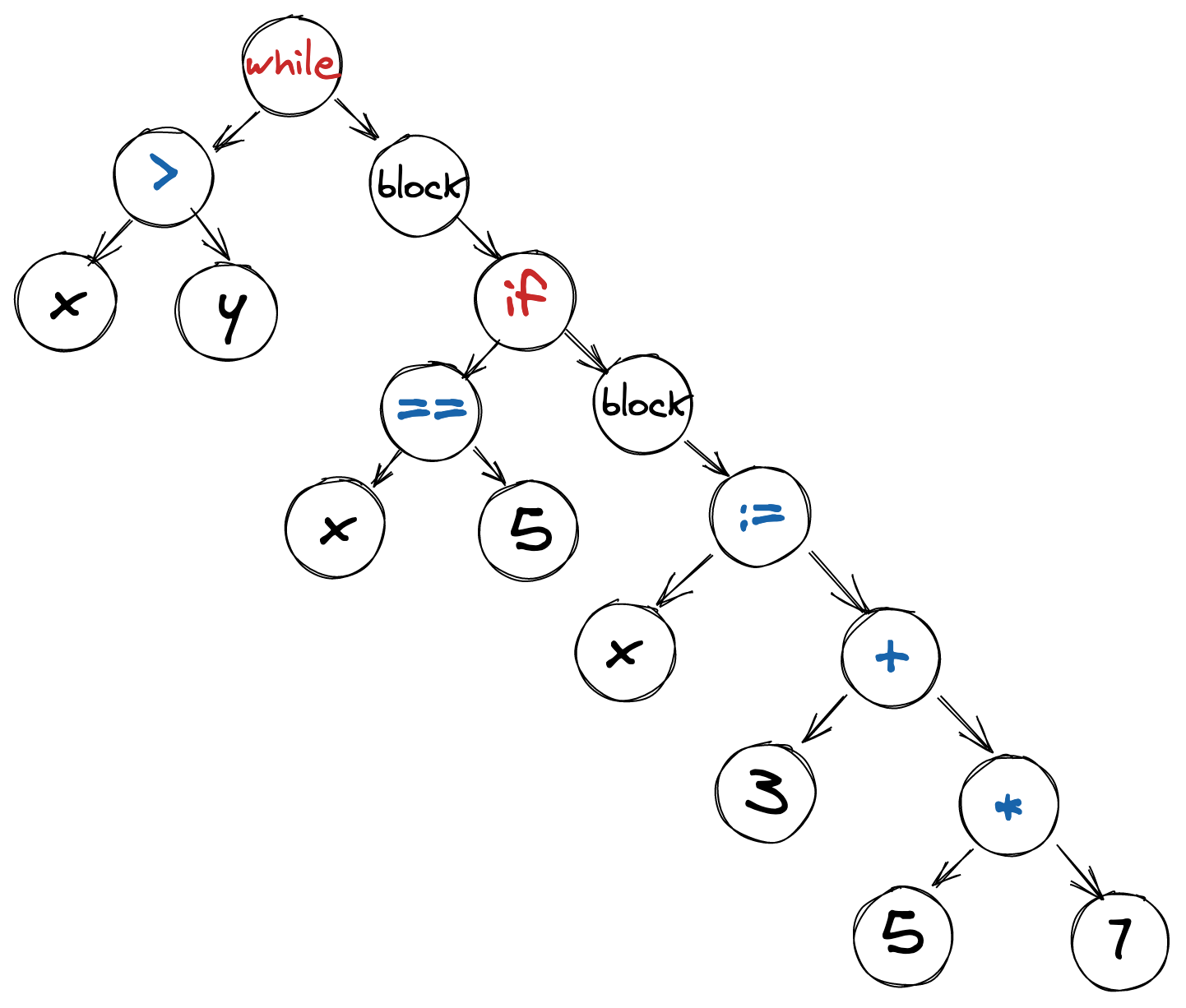 High-Level Overview of AST
High-Level Overview of AST
It is not the real world equivalent; we ignored and simplified many things in the tree. You can think of it as a pseudo-AST. If we wanted to get a real representation of AST for this code snippet:
*package *main
*func *main() {
x := 5
y := 3
*for *x > y {
*if *x == 5 {
z := 3 + (5 * 7)
}
}
}
Then you can use either an AST viewer (i.e., *goast-viewer*) or Go’s official parser package (in the next section, we will see what the parser is) to dump the whole AST into stdout manually:
package main
import (
"go/ast"
"go/parser"
"go/token"
"os"
)
func main() {
fset := new(token.FileSet)
f, _ := parser.ParseFile(fset, "your_source_code.go", nil, 0)
ast.Print(fset, f)
}
This code will print out approximately ~170 lines of AST. I wrapped some object references and positions in the following picture:
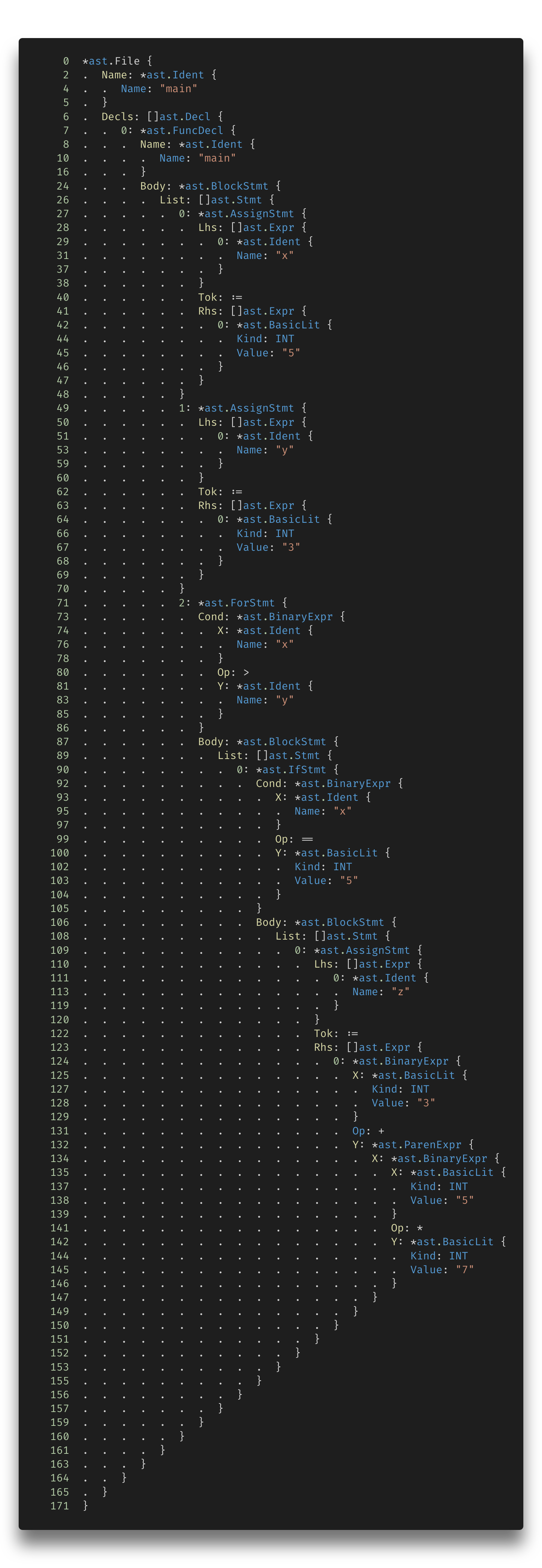 Output of GoAst Viewer
Output of GoAst Viewer
2.1.3. Scanner
This is where your syntax error messages throwing from. Scanner, scans the next token and returns the token position, the token, and the literal string if applicable. The scanner initializes from the Parser. Scanner does not create any AST structure; all it does is read tokens and catch any semantic (syntax) errors.
Let’s jump to ./scanner/scanner.go file:
func (s *Scanner) Scan() (pos token.Pos, tok token.Token, lit string) {
...
switch ch := s.ch; {
...
default:
...
case '|':
tok = s.switch3(token.OR, token.OR_ASSIGN, '|', token.LOR)
case '~':
tok = token.TILDE
default:
...
}
}
}
The swtich2, swtich3, and swtich4 functions are for scanning multi-byte tokens such as >> , += , >> , = . Different routines recognize different length tokens based on matches of the n-th character.
-
% is a swtich2 , because only allowed: %, %=
-
- is a swtich3 , because only allowed: +, +=, ++
-
is a swtich4 , because only allowed: >, ≥, >>, >≥
Adding only two lines completes our work here. Let’s write some test in ./scanner/scanner_test.go to test our new token.
Update the tokens:
var tokens = […]elt {
...
// Operators and delimiters
{token.SHR, ">>", operator},
{token.AND_NOT, "&^", operator},
{token.TILDE, "~", operator},
...
}
Update the lines:
var lines = []string {
"",
"\ufeff#;", // first BOM is ignored
...
">>\n",
"&^\n",
"~\n",
...
}
Run the tests:
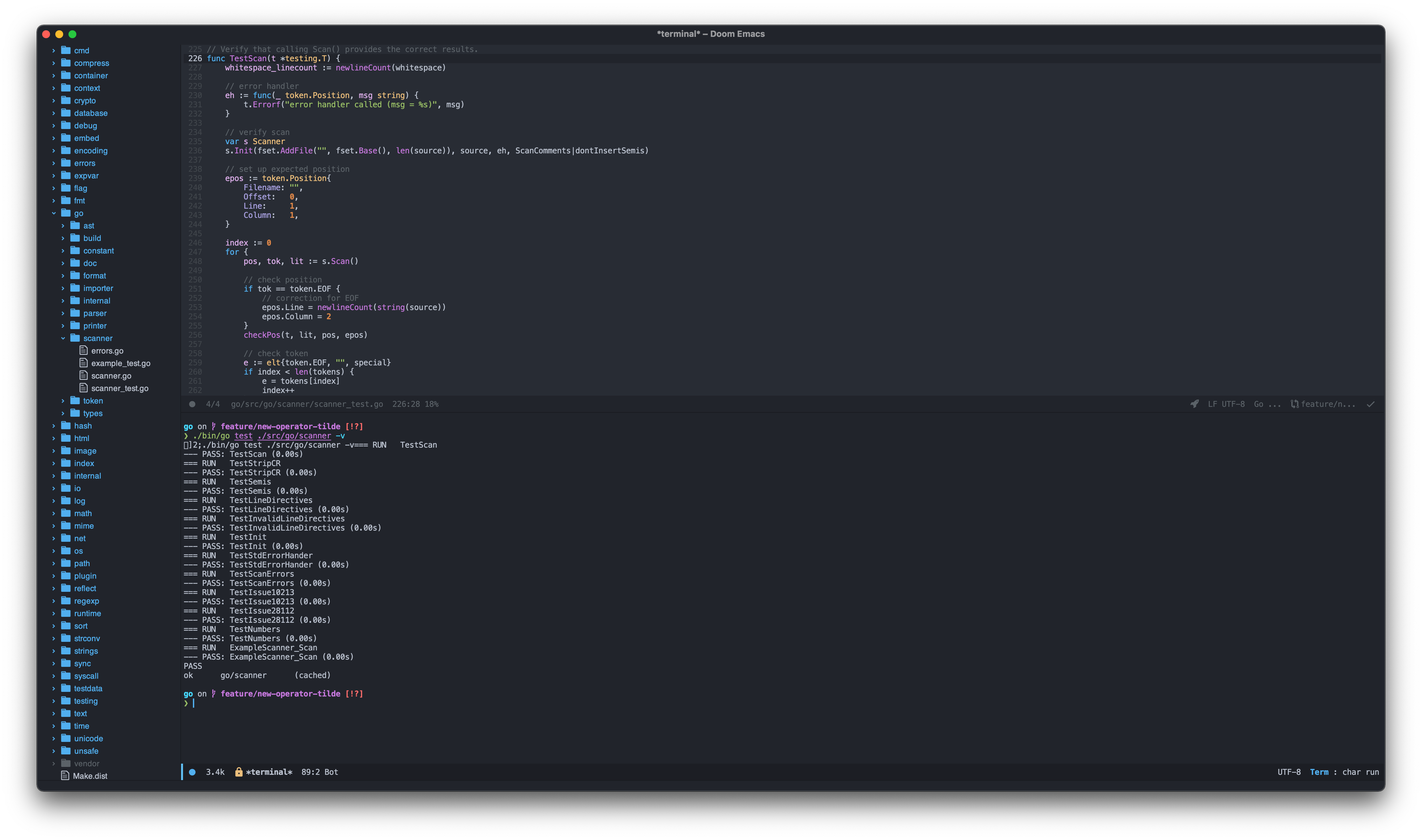 Scanner Tests
Scanner Tests
Yay! Our tests are passing!
2.1.4. Parser
Go parser converts this list of tokens into a Tree-like object to represent how the tokens fit together to form a cohesive whole. Input may be provided in various forms; the output is an Abstract Syntax Tree (AST) representing the Go source.
A parser is a software component that takes input data (frequently text) and builds a data structure — often some kind of Parse Tree, Abstract Syntax Tree or other hierarchical structure, giving a structural representation of the input while checking for correct syntax. The parsing may be preceded or followed by other steps, or these may be combined into a single step. The parser is often preceded by a separate lexical analyser, which creates tokens from the sequence of input characters; alternatively, these can be combined in scannerless parsing. [4]
Wait… The last sentence may a bit important for us.
Scannerless parsing performs tokenization (breaking a stream of characters into words) and parsing (arranging the words into phrases) in a single step, rather than breaking it up into a pipeline of a lexer followed by a parser, executing concurrently.
Go does use a built-in scanner, which means that Go does a separate lexical analysis already.
Let’s assume that we have the necessary compiler front-end components that somehow communicate with each other. Usually, the basic overall structure will look something like the following:
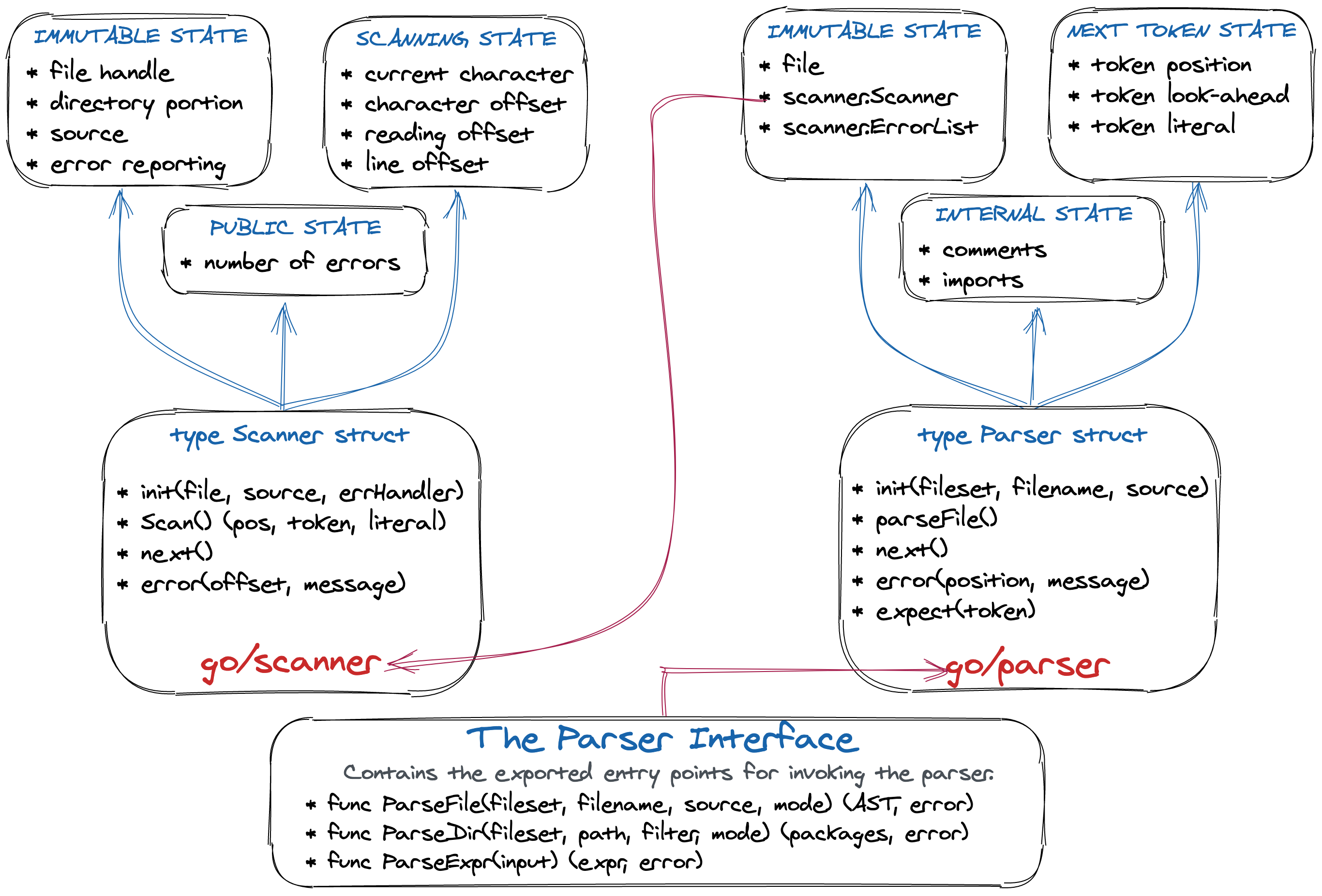 Medium Level Overview of The Parser Interface
Medium Level Overview of The Parser Interface
At the beginning of this section, we have drawn a high-level overview of Compiler Front-End flow, as you remember. But this… is a medium-level overview of the Parser Interface that describes how Scanner and Parser communicate through exported functions. Parser Interface contains the exported entry points for invoking the parser. We shall not dwell in detail since this is a good topic for deep-diving in the source code.
Let’s jump to parseUnaryExpr function in the ./parser/parser.go:
func (p *parser) parseUnaryExpr() ast.Expr {
...
switch p.tok {
case token.ADD, token.SUB, token.NOT, token.XOR, token.AND, token.TILDE:
pos, op := p.pos, p.tok
p.next()
x := p.parseUnaryExpr()
return &ast.UnaryExpr{OpPos: pos, Op: op, X: p.checkExpr(x)}
...
}
}
Jump to parseStmt function to define the new operator:
func (p *parser) parseStmt() (s ast.Stmt) {
...
switch p.tok {
...
case
// tokens that may start an expression
token.IDENT, ..., token.NOT, token.TILDE // unary operators
}
Out of context, I noticed that a function called TestParse included in parser_test.go file. I like the idea of how the parser tester using itself as a test case scenario. I could not go forward without mentioning this detail. It’s cool, isn’t it:
*var *validFiles = []string{
"parser.go",
"parser_test.go"
}
*func TestParse*(t *testing.T) {
*for *_, filename := *range *validFiles {
_, err := ParseFile(token.NewFileSet(), filename, nil, *DeclarationErrors*)
...
}
}
2.1.5. Constant
Package constant implements Values representing untyped Go constants and their corresponding operations.
Jump to constant/value.go file
// UnaryOp returns the result of the unary expression op y.
// The operation must be defined for the operand.
// If prec > 0 it specifies the ^ (xor) result size in bits.
// If y is Unknown, the result is Unknown.
//
func UnaryOp(op token.Token, y Value, prec uint) Value {
switch op {
case token.ADD:
...
...
case token.NOT:
...
case token.TILDE:
switch y := y.(type) {
case unknownVal:
return y
case intVal:
return makeInt(newInt().Com(y.val))
case int64Val:
return makeInt(newInt().Com(big.NewInt(int64(y))))
default:
goto Error
}
}
NEG reserved for negative operation and stands for sets z to -x and returns z. We can go with COM for now.
Find the constant/value_test.go file and jump to opTests table:
var opTests = []string{
// unary operations
`+ 0 = 0`,
...
`^ ? = ?`,
`~ 2 = -3`,
`~ 60 = -61`,
...
}
One more step to define in optab struct.
var optab = map[string]token.Token{
"!": token.NOT,
...
"&^": token.AND_NOT,
"~": token.TILDE,
...
}
By doing this, we will ensure the operation that we stored in opTest is also defined in theoptab table. Find this function:
func TestOps(t *testing.T) {
for _, test := range opTests {
a := strings.Split(test, “ “)
i := 0 // operator index
...
op, ok := optab[a[i]]
if !ok {
panic(“missing optab entry for “ + a[i])
}
...
got := doOp(x, op, y)
...
}
We know that unary operators only work with one value. So cannot be used between two values, but others can be. (Such as: ||, >>, !=, ≥, etc.).
func doOp(x Value, op token.Token, y Value) (z Value) {
...
if x == nil {
return UnaryOp(op, y, 0)
}
...
}
As you noticed, we called theUnaryOp function here, which we want to write the test for.
It is NOT OK to run the test since we do not implement brand-new Com function in themath/big.Int package, yet.
2.1.6 Math
Match package implements a collection of common math functions. It provides a suite of arithmetic, geometric, complex, and so on functionalities to perform basic math operations for the compiler itself. In addition, you can see some platform-based assembly instructions. Some of the algorithms just implemented a simplified version from the C sources. Especially most are adopted from C implementations from Netlib Repository, which is a collection of mathematical software, papers, and databases. If you want to implement a mathematical function, then this package is where your address.
2.1.6.1. big.Int
big.Int package implements signed multi-precision integers. Find the math/big/int.go file. We will write our COM function here.COM will replace the value of a register or memory operand with its one*’s complement*. We can define it bysets z to ~x and returns z*. *Simply, we want to implement the mathematical equivalent of the *bitwise not *algorithm.
So, easy peasy:
*// Com sets z to ~x and returns z.
func *(z *Int) *Com*(x *Int) *Int {
z.Set(x)
z.neg = !z.neg
*if *z.neg {
z.abs = z.abs.add(x.abs, natOne)
} *else *{
z.abs = z.abs.sub(x.abs, natOne)
}
*return *z
}
We could have traversed binary bits from least significant to most significant and reverse every bit. Still, adding an unnecessary loop here may complicate things since we already got the correct results.
Let’s write some tests for that in the int_test.go file:
*func TestCom*(t *testing.T) {
*var *z Int
*for *_, test := *range *[]*struct *{
n int64
want string
}{
{-7, "6"},
{-2, "1"},
{-1, "0"},
{0, "-1"},
{4, "-5"},
{5, "-6"},
{6, "-7"},
{7, "-8"},
{8, "-9"},
{15, "-16"},
{-15, "14"},
} {
v := NewInt(test.n)
*if *got := z.Com(v).String(); got != test.want {
t.Errorf("Com(%+v) = %s; want %s", v, got, test.want)
}
}
}
Wow! Our tests are passing! We just implemented thebitwise not operator. (You can try to reverse bits by walking each bit in a for loop!) Now let’s run the all of math tests:
$ go test ./big/.. -v
...
=== RUN TestCom
--- PASS: TestCom (0.00s)
...
PASS
ok math/big 2.647s
Cool! Now we can able to compile the Go! Jump the root directory and just run:
$ ./all.bash
Building Go cmd/dist using /usr/local/go. (go1.16.3 darwin/amd64)
Building Go toolchain1 using /usr/local/go.
# bootstrap/go/constant
/Users/furkan.turkal/src/public/go/src/go/constant/value.go:1003: undefined: token.TILDE
go tool dist: FAILED: /usr/local/go/bin/go install -gcflags=-l -tags=math_big_pure_go compiler_bootstrap bootstrap/cmd/...: exit status 2
**WAIT, WHAT!? **We just got undefined: token.TILDE error? 😱 But… We have defined it? How is this even possible? OK, let me explain the reason why the toolchain threw this error:
The problem is that go/constant is a bootstrap package. From /src/cmd/dist/buildtool.go .
bootstrapDirs is a list of directories holding code that must be compiled with a Go 1.4 toolchain to produce the bootstrapTargets. Names beginning with cmd/ no other slashes, which are commands, and other paths, which are packages supporting the commands.
*var *bootstrapDirs = []string{
...
"cmd/compile",
"cmd/compile/internal/...",
...
"go/constant",
...
"math/big",
"math/bits",
"sort",
"strconv",
}
This means that go/constant needs to be compilable by the bootstrapping toolchain (but we need to support down to go1.4). But since we added a case token.TILDE: to value.go, go/constant is no longer compilable with an older toolchain, and the bootstrapping process fails. [15]
This is the side effect of commit 742c05e. And mdempsky said:
Some packages support build tags for building simplified variants during bootstrap. E.g., math/big has math_big_pure_go and strconv and math/bits have compiler_bootstrap. It might be possible to do something similar for go/constant, if you're particularly pressed for this to work today. But I think like @ianlancetaylor points out, waiting for #44505 seems like the simplest/surest solution. [16]
So, 🤷♂️. There is nothing to do except waiting. We can save the stash and wait for the fix for that issue:
$ git stash save go_tilde_issue_44505
$ git stash show "stash@{0}" -p > go_tilde_issue_44505.patch
It’s time to move on to the NEWcmd/compiler package, which is including the real compiler internals.
2.2. cmd/compile
cmd/compilecontains the main packages that form the Go compiler. The compiler may be logically split in four phases, which we will briefly describe alongside the list of packages that contain their code. You may sometimes hear the terms front-end and back-end when referring to the compiler. Roughly speaking, these translate to the first two and last two phases we are going to list here. A third term, middle-end, often refers to much of the work that happens in the second phase. It should be clarified that the name gc stands for Go compiler, and has little to do with uppercase GC, which stands for garbage collection.
2.2.1.⠀Differences with go/*
Note that the go/* family of packages, such as go/parser and go/types, have no relation to the compiler. Since the compiler was initially written in C, the go/* packages were developed to enable writing tools working with Go code, such as gofmt and vet. [6]
We learned what should we do during implementation for go/* package, same as here…
2.2.2. Creating Test Script
…Before going forward, what we need to do is create a minimal neg.go file to make some test for our new~ token. What we want to achieve is that simply make this minimal code run:
package main
func main() {
println(~15)
}
Now compile and run:
$ cd ./src
$ ./make.bash
$ cd ..
$ ./bin/go run neg.go
./neg.go:4:13: syntax error: unexpected ~, expecting expression
NIT: To avoid run in order these 4 lines of code every time, we can create simple test.sh script at parent directory to handle this process easily:
#!/bin/bash
pushd ./src
./make.bash
popd
./bin/go run neg.go
*Do not forget to give executable access: *$ chmod +x ./test.sh
Now let’s jump to ./cmd/compile/internal/snytax folder.
2.2.3. Token
We are going to make this Tilde token part to the const of tokens.go:
*const *(
_ Operator = iota
*...
Recv // <-
Tilde // ~
...
)*
2.2.3.1. Operator String
As you noticed, there is a statement top of the operator_string.go file that says:
// Code generated by “stringer -type Operator -linecomment tokens.go”; DO NOT EDIT.
func _() {
var x [1]struct{}
_ = x[Def-1]
_ = x[Not-2]
_ = x[Recv-3]
_ = x[OrOr-4]
_ = x[AndAnd-5]
_ = x[Eql-6]
_ = x[Neq-7]
_ = x[Lss-8]
_ = x[Leq-9]
_ = x[Gtr-10]
_ = x[Geq-11]
_ = x[Add-12]
_ = x[Sub-13]
_ = x[Or-14]
_ = x[Xor-15]
_ = x[Mul-16]
_ = x[Div-17]
_ = x[Rem-18]
_ = x[And-19]
_ = x[AndNot-20]
_ = x[Shl-21]
_ = x[Shr-22]
}
There is a nameless function _() here that enforces every single constant is defined by order.
const _Operator_name = “:!<-||&&==!=<<=>>=+-|^*/%&&^<<>>”
var _Operator_index = […]uint8{0, 1, 2, 4, 6, 8, 10, 12, 13, 15, 16, 18, 19, 20, 21, 22, 23, 24, 25, 26, 28, 30, 32}
func (i Operator) String() string {
i -= 1
if i >= Operator(len(_Operator_index)-1) {
return “Operator(“ + strconv.FormatInt(int64(i+1), 10) + “)”
}
return _Operator_name[_Operator_index[i]:_Operator_index[i+1]]
}
This is how Go handles operator to string converts efficiently. We need to add our Tilde operator here. To do that, we need to fill index struct as compiler enforces us, by running $ go generate command, which it will call stringercommand in the background.
2.2.3.2. **Stringer**
Stringer is a tool to automate the creation of methods that satisfy the fmt.Stringer interface. Given the name of a (signed or unsigned) integer type T that has constants defined. Stringer will create a new self-contained Go source file implementing
Stringer works best with constants that are consecutive values such as created using iota, but creates good code regardless. In the future it might also provide custom support for constant sets that are bit patterns.
$ ./bin/go generate ./src/cmd/compile/internal/syntax
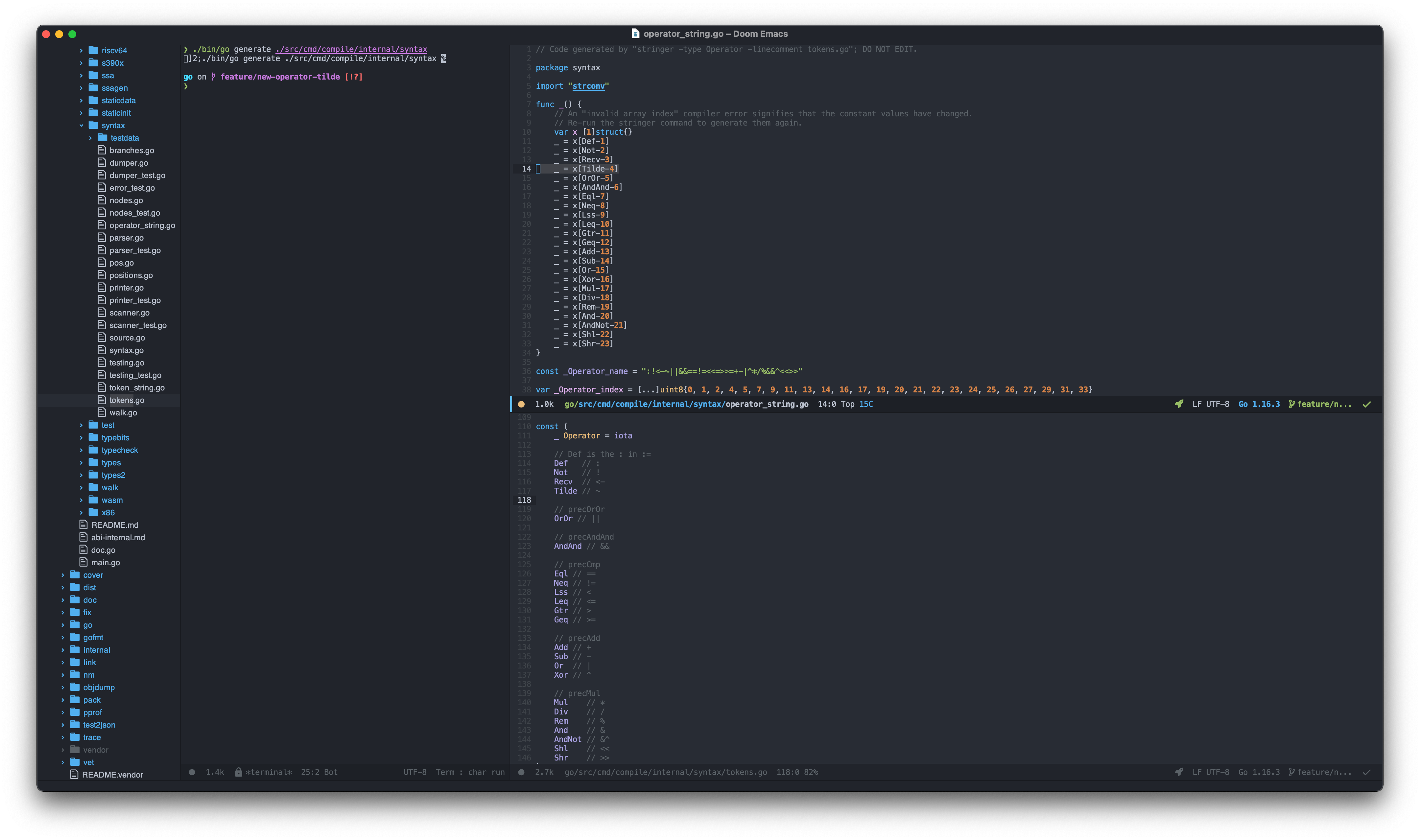 Code Generated by Stringer
Code Generated by Stringer
Our operator successfully placed at the 4th line.
2.2.4. Scanner
Same operations here like we already did in section 2.1.1.
Open ./scanner.go and jump to next() function:
*func *(s *scanner) next() {
...
*switch *s.ch {
...
*case *'!':
...
*case *'~':
s.nextch()
s.op, s.prec = *Tilde*, 0
s.tok = _Operator
...
}
}
Writing for the scanner is straightforward. We just added one line to sampleTokens struct.
*var *sampleTokens = [...]*struct *{
...
}{
...
{_Literal, "`\r`", 0, 0},
...
{_Operator, "~", *Tilde*, 0},
...
}
Run the tests:
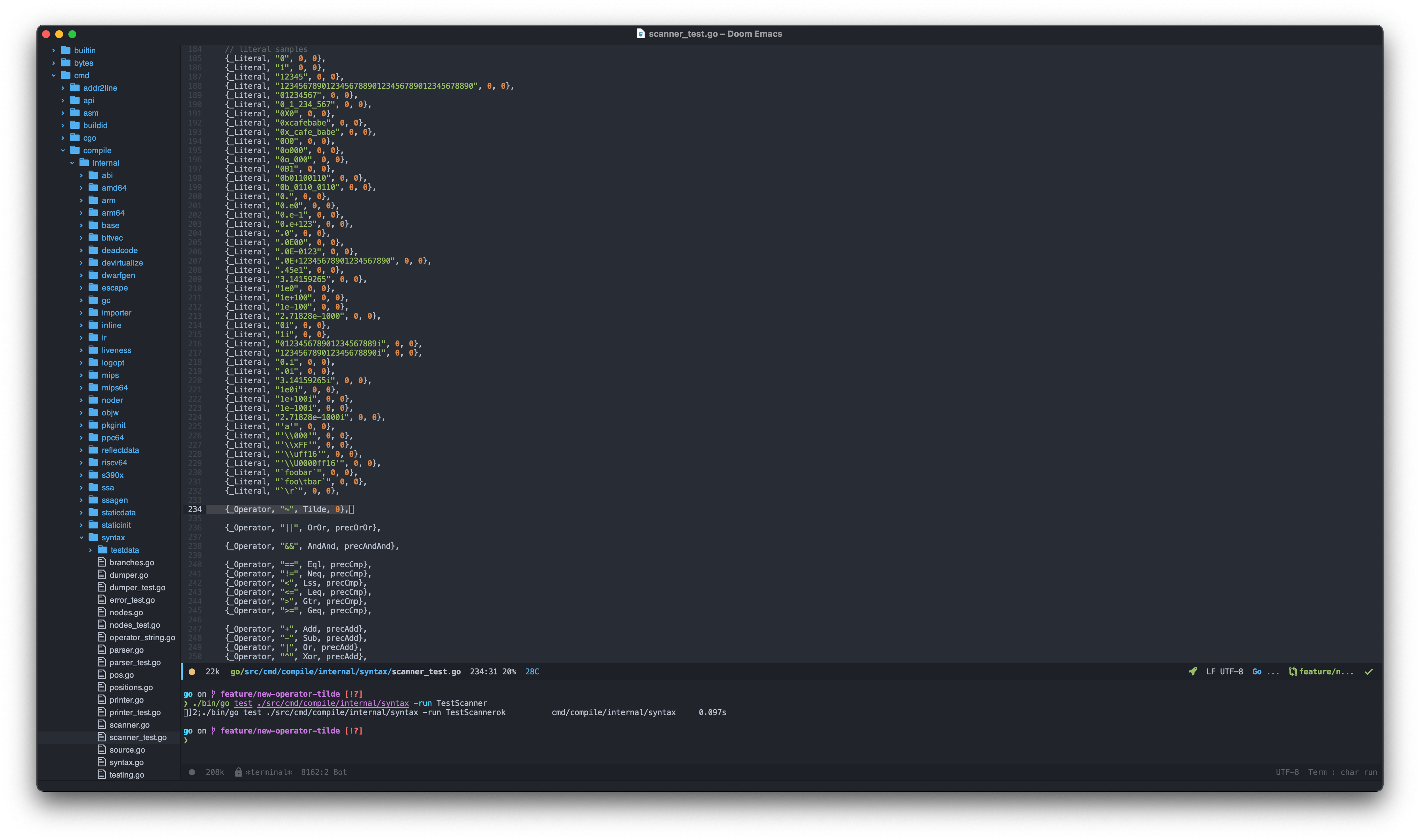 Running Scanner Tests
Running Scanner Tests
2.2.5. Parser
Find the ./parser.go file and jump to unaryExpr() function, and add Tilde token inside the_Operator, _Star case:
*func *(p *parser) unaryExpr() Expr {
...
*switch *p.tok {
*case *_Operator, _Star:
*switch *p.op {
*case Mul*, *Add*, *Sub*, *Not*, *Xor*, Tilde:
x := new(Operation)
x.pos = p.pos()
x.Op = p.op
p.next()
x.X = p.unaryExpr()
*return *x
...
...
}
}
OK, so far, so good. Go actually knows what the Tildeoperator is and how to parse by scanners, et does not know how to use it and operate it during the compile phase. So it will fail to compile in thegcpackage. So let’s build Go and see what error it throws.
Run the test.sh to see what would happen:
panic: invalid Operator
goroutine 1 [running]:
cmd/compile/internal/noder.(*noder).unOp(...)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/noder/noder.go:1383
cmd/compile/internal/noder.(*noder).expr(0x100cc5b, 0x1a71318, 0xc00039e0c0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/noder/noder.go:744 +0x1baa
cmd/compile/internal/noder.(*noder).exprs(0x2319400, 0xc000064030, 0x1, 0x203000)
Panic has thrown because compile did not know how to convert Tilde to Abstract syntax representation yet. Therefore, we need to declare an Intermediate Representation for the operator in the Middle-End section.
3. Compiler Middle-End
The middle-end, also known as an optimizer, performs optimizations on the Intermediate Representation to improve the performance and the quality of the produced machine code. The middle end contains those optimizations that are independent of the CPU architecture being targeted. [11]
The main phases of the middle end include the following:
-
Analysis: This gathers program information from the intermediate representation derived from the input; data-flow analysis is used to build use-define chains, together with dependence analysis, alias analysis, pointer analysis, escape analysis, etc.
-
Optimization: the intermediate language representation is transformed into functionally equivalent but faster or smaller forms. Popular optimizations are inline expansion, dead code elimination, constant propagation, loop transformation, and even automatic parallelization.
3.1. Intermediate Representation (IR)
![High-Level Overview of IR [8]](https://cdn-images-1.medium.com/max/4284/1*EgFEXbBGbouH6Og94CBSWw.png) High-Level Overview of IR [8]
High-Level Overview of IR [8]
^ Here’s the 30,000-foot view of how Machine Code is generating.
An intermediate representation is the data structure or code used internally by a compiler or virtual machine to represent source code. An IR is designed to be conducive for further processing, such as optimization and translation. An intermediate language is the language of an abstract machine designed to aid in the analysis of computer programs. The term comes from their use in compilers, where the source code of a program is translated into a form more suitable for code-improving transformations before being used to generate object or machine code for a target machine. Use of an intermediate representation allows compiler systems like the GNU Compiler Collection and LLVM to be used by many different source languages to generate code for many different target architectures. [7]
All *Abstract Syntax Representation *related stuff stored under ./src/cmd/compile/internal/ir/ as ir package.
3.1.1. Node
Node is the abstract interface to an IR node.
We need to define the new opcode as OCOM under consts:
*type *Op uint8
*// Node ops.
const *(
*OXXX *Op = iota
...
OPLUS // +X
ONEG // -X
OCOM // ~X
...
)
After we declared new Node here, we need to run $ stringer -type=Op -trimprefix=O node.go again to automatically generate OCOM OpCode and do update to ./ir/op_string.go file:
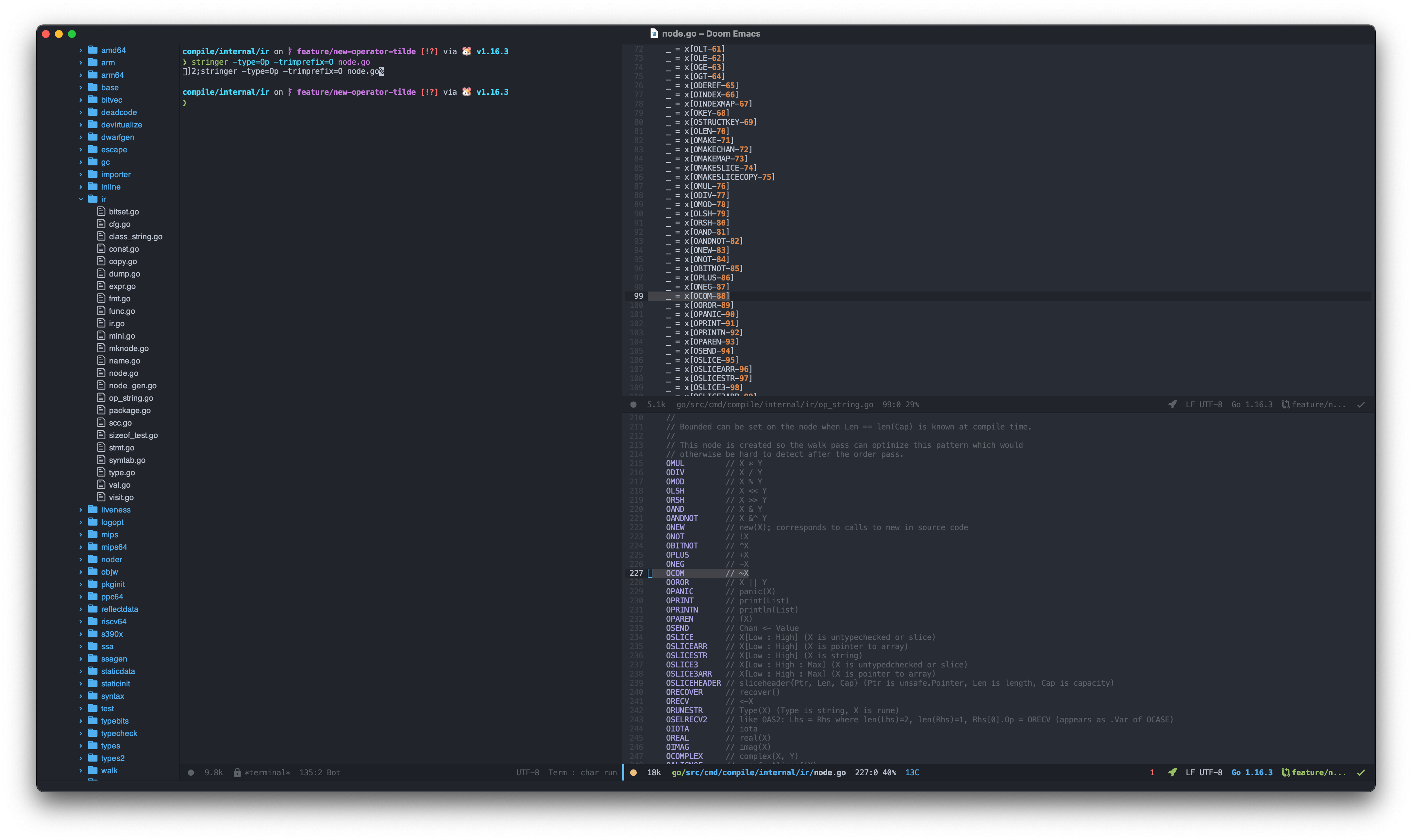 Stringer to ir/op_string.go
Stringer to ir/op_string.go
By doing so, now we can easily convert the OpCode to String using [1]struct{} map:
*func *(i Op) *String*() string {
*if *i >= Op(*len*(_Op_index)-1) {
*return *"Op(" + strconv.FormatInt(int64(i), 10) + ")"
}
*return *_Op_name[_Op_index[i]:_Op_index[i+1]]
}
Now what we need to do here is that we have to update the unary map table that declared under ./noder/noder.go.
Find the unOps table:
var unOps = [...]ir.Op {
syntax.Recv: ir.ORECV,
...
syntax.Tilde: ir.OCOM
}
We defined new a Syntax token here, and thus compiler will not throw invalid Operator panic anymore:
*func *(p *noder) unOp(op syntax.Operator) ir.Op {
*if *uint64(op) >= uint64(*len*(unOps)) || unOps[op] == 0 {
*panic*("invalid Operator")
}
*return *unOps[op]
}
I think it’s a good checkpoint to see how the error is changed after we implemented those. Run the ./test.sh file:
panic: cannot SetOp COM on XXX
goroutine 1 [running]:
cmd/compile/internal/ir.(*UnaryExpr).SetOp(0xc000076230, 0x1a682e0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/ir/expr.go:672 +0x10c
cmd/compile/internal/ir.NewUnaryExpr(…)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/ir/expr.go:665
cmd/compile/internal/noder.(*noder).expr(0x100cc5b, 0x1a71358, 0xc0004000c0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/noder/noder.go:751 +0x1887
cmd/compile/internal/noder.(*noder).exprs(0x231d000, 0xc000064030, 0x1, 0x203000)
Wow, the panic message is changed. Let’s investigate that where the error is coming from.
3.1.2. Expr
Expr is a Node that can appear as an expression.
*type Expr interface *{
Node
isExpr()
}
We initialize the unary operator at ./ir/expr.go in a function called NewUnaryExpr():
*// A UnaryExpr is a unary expression Op X,
// or Op(X) for a builtin function that does not end up being a call.
type *UnaryExpr *struct *{
miniExpr
X Node
}
*func NewUnaryExpr*(pos src.XPos, op Op, x Node) *UnaryExpr {
n := &UnaryExpr{X: x}
n.pos = pos
n.SetOp(op)
*return *n
}
But n.SetOp(op) function throw error here because it falls into the default case, which is throwing panic:
*func *(n *UnaryExpr) *SetOp*(op Op) {
*switch *op {
*default*:
*panic*(n.no("SetOp " + op.String()))
* case OBITNOT*, *ONEG*, *OCOM*, *...*, ..., *OVARLIVE*:
n.op = op
}
Adding OCOM to the just right of ONEG will fix the problem. Now jump to SameSafeExpr() function and add OCOMto UnaryExpr casting case.
*// SameSafeExpr checks whether it is safe to reuse one of l and r
// instead of computing both. SameSafeExpr assumes that l and r are
// used in the same statement or expression.
func SameSafeExpr*(l Node, r Node) bool {
*if *l.Op() != r.Op() || !types.Identical(l.Type(), r.Type()) {
*return *false
}
...
*case ONOT*, *OBITNOT*, *OPLUS*, *ONEG*, *OCOM*:
l := l.(*UnaryExpr)
r := r.(*UnaryExpr)
*return *SameSafeExpr(l.X, r.X)
...
}
Rerun the tests:
typecheck [0xc0001398b0]
. COM tc(2) # neg.go:4
. . LITERAL-15 untyped int # neg.go:4
./neg.go:4:13: internal compiler error: typecheck COM
goroutine 1 [running]:
runtime/debug.Stack()
/Users/furkan.turkal/src/public/go/src/runtime/debug/stack.go:24 +0x65
cmd/compile/internal/base.FatalfAt(0xc0001398b0, 0x191d86a, 0x1a7fb48, 0xc000146be0, 0x1824634, 0x188e860)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:227 +0x157
cmd/compile/internal/base.Fatalf(...)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:196
cmd/compile/internal/typecheck.typecheck1(0x1a7fb48, 0xc0001398b0, 0x12)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/typecheck/typecheck.go:484 +0x298a
cmd/compile/internal/typecheck.typecheck(0x1a7fb48, 0xc0001398b0, 0x12)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/typecheck/typecheck.go:371 +0x4b0
cmd/compile/internal/typecheck.typecheckslice(0xc0001028c0, 0x1, 0x11ab40a, 0x1a7eba8)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/typecheck/typecheck.go:177 +0x68
What we need to do here is simply define our new syntax token in the typecheck.go file. Then, find the typecheck1() function, and jump to theunaryExpr case.
*// typecheck1 should ONLY be called from typecheck.
func *typecheck1(n ir.Node, top int) ir.Node {
...
*case *ir.*OBITNOT*, ir.*ONEG*, ir.*ONOT*, ir.*OPLUS*, ir.*OCOM*:
n := n.(*ir.UnaryExpr)
*return *tcUnaryArith(n)
...
}
So we may want to know what happens in the function called tcUnaryArith(n). So let’s investigate it:
*// tcUnaryArith typechecks a unary arithmetic expression.
func *tcUnaryArith(n *ir.UnaryExpr) ir.Node {
...
*if *!okfor[n.Op()][defaultType(t).Kind()] {
base.Errorf("invalid operation: %v (operator %v not defined on %s)", n, n.Op(), typekind(t))
n.SetType(nil)
*return *n
}
...
}
If we’d rerun the test, we’d have panicked here due to this check:!okfor[n.Op()][defaultType(t).Kind()]
Jump to ./typecheck/universe.go file. You will see two vars at the top of the file:
*var *(
okfor [ir.*OEND*][]bool
iscmp [ir.*OEND*]bool
)
I was really impressed when I first saw this file. We are defining the OpCodes what operations they will do.
*var *(
okforeq [types.*NTYPE*]bool
okforadd [types.*NTYPE*]bool
okforand [types.*NTYPE*]bool
okfornone [types.*NTYPE*]bool
okforbool [types.*NTYPE*]bool
okforcap [types.*NTYPE*]bool
okforlen [types.*NTYPE*]bool
okforarith [types.*NTYPE*]bool
)
The OpCode we created OCOM should able to do some arithmetic operations as we mentioned in the proposal:
-
We should not allow ~ for bools. i.e. ~true (since Go already support this with !true) So, not okforbool
-
We should allow ~ for arithmetics. i.e. ~7. So, okforarith
-
There are no such things called !~, ~~, ~> or <~, So, eliminate all the others but okforarith
Let’s do a little operation on the InitUniverse() function as we mentioned above:
*// InitUniverse initializes the universe block.
func InitUniverse*() {
...
...
...
*// unary
*okfor[ir.*OBITNOT*] = okforand[:]
okfor[ir.*ONEG*] = okforarith[:]
okfor[ir.*OCOM*] = okforarith[:]
...
}
So, the okfor[n.Op()][defaultType(t).Kind()] function will never return false once we put the OCOM in okfor map.
Run the ./test.sh again:
./neg.go:4:12: internal compiler error: unexpected untyped expression: <node COM>
goroutine 1 [running]:
runtime/debug.Stack()
/Users/furkan.turkal/src/public/go/src/runtime/debug/stack.go:24 +0x65
cmd/compile/internal/base.FatalfAt(0xc0004101e0, 0x1930ce3, 0x9844128, 0xc00011eeb8, 0x12200e8, 0x1a7fb68)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:227 +0x157
cmd/compile/internal/base.Fatalf(…)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:196
cmd/compile/internal/typecheck.convlit1(0x1a7fb68, 0xc0004101e0, 0x8, 0x203000, 0x0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/typecheck/const.go:123 +0xb8c
Whops, we forgot the modify ./typecheck/const.go file.
We did not define the Token inside the tokenForOp map:
*var *tokenForOp = [...]token.Token {
...
}
Find the convlit1 function:
*// convlit1 converts an untyped expression n to type t. If n already
// has a type, convlit1 has no effect.
//
func *convlit1(n ir.Node, t *types.Type, explicit bool, context *func*() string) ir.Node {
...
...
...
*case *ir.*OPLUS*, ir.*ONEG*, ir.OCOM, ...:
...
...
...
}
Run the ./test.sh again:
./neg.go:4:13: internal compiler error: unexpected expr: COM <node COM>
goroutine 1 [running]:
runtime/debug.Stack()
/Users/furkan.turkal/src/public/go/src/runtime/debug/stack.go:24 +0x65
cmd/compile/internal/base.FatalfAt(0x1942672, 0x19273d4, 0x8, 0xc00011efa8, 0x100cc5b, 0x116fff9)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:227 +0x157
cmd/compile/internal/base.Fatalf(…)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:196
cmd/compile/internal/escape.(*escape).exprSkipInit(0xc0004101e0, 0xc0004181c0, 0x0, 0x0, 0xc000410000, 0x1a7fb68, 0xc0004101e0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/escape/escape.go:590 +0x2025
Wow, it looks like it’s time to move on to Escape Analysis.
3.2. Escape Analysis
Escape analysis, one of the phases of the Go compiler. It analyses the source code and determines what variables should be allocated on the stack and which ones should escape to the heap. Go statically defines what should be heap or stack-allocated during the compilation phase. This analysis is available via the flag -gcflags="-m" when compiling and/or running your code. [12]
Here we analyze functions to determine which Go variables can be allocated on the stack. The two key invariants we have to ensure are: (1) pointers to stack objects cannot be stored in the heap, and (2) pointers to a stack object cannot outlive that object (e.g., because the declaring function returned and destroyed the object’s stack frame or its space is reused across loop iterations for logically distinct variables). We implement this with static data-flow analysis of the AST. First, we construct a directed weighted graph where vertices (termed “locations”) represent variables allocated by statements and expressions, and edges represent assignments between variables (with weights representing addressing/dereference counts). Next, we walk the graph looking for assignment paths that might violate the invariants stated above. If a variable v’s address is stored in the heap or elsewhere that may outlive it, then v is marked as requiring heap allocation. To support interprocedural analysis, we also record data-flow from each function’s parameters to the heap and to its result parameters. This information is summarized as “parameter tags”, which are used at static call sites to improve escape analysis of function arguments. [13]
Find the exprSkipInit function:
*func *(e *escape) exprSkipInit(k hole, n ir.Node) {
...
*switch *n.Op() {
*default*:
base.Fatalf("unexpected expr: %s %v", n.Op().String(), n)
...
*case *ir.*OPLUS*, ir.*ONEG*, ir.*OCOM*, ir.*OBITNOT*:
n := n.(*ir.UnaryExpr)
e.unsafeValue(k, n.X)
...
}
Find the unsafeValue function:
*// unsafeValue evaluates a uintptr-typed arithmetic expression looking
// for conversions from an unsafe.Pointer.
func *(e *escape) unsafeValue(k hole, n ir.Node) {
...
*switch *n.Op() {
...
*case *ir.*OPLUS*, ir.*ONEG*, ir.*OCOM*, ir.*OBITNOT*:
n := n.(*ir.UnaryExpr)
e.unsafeValue(k, n.X)
...
}
Find the mayAffectMemory function:
*// mayAffectMemory reports whether evaluation of n may affect the program's
// memory state. If the expression can't affect memory state, then it can be
// safely ignored by the escape analysis.
func *mayAffectMemory(n ir.Node) bool {
...
*switch *n.Op() {
...
*case *ir.*OLEN*, *...*, ir.*ONEG*, ir.*OCOM*, ir.*OALIGNOF*, *...*:
n := n.(*ir.UnaryExpr)
*return *mayAffectMemory(n.X)
Run the ./test.sh again:
walk [0xc0004101e0]
. COM tc(1) int # neg.go:4 int
. . LITERAL-15 tc(1) int # neg.go:4
./neg.go:4:13: internal compiler error: walkExpr: switch 1 unknown op COM
goroutine 1 [running]:
runtime/debug.Stack()
/Users/furkan.turkal/src/public/go/src/runtime/debug/stack.go:24 +0x65
cmd/compile/internal/base.FatalfAt(0xc0004101e0, 0x1930e0c, 0x1a7fb68, 0xc0001272a0, 0xc00009d2b0, 0xc00009d2b0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:227 +0x157
cmd/compile/internal/base.Fatalf(…)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:196
cmd/compile/internal/walk.walkExpr1(0x1a7fb68, 0xc0004101e0, 0xc0004101e0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/walk/expr.go:82 +0xe9f
3.3. Walk
We walk the given ir.Func and their all statements here.
*func Walk*(fn *ir.Func) {
ir.CurFunc = fn
...
order(fn)
...
walkStmtList(ir.CurFunc.Body)
...
}
A Func corresponds to a single function in a Go program (and vice versa: each function is denoted by exactly one *Func). There are multiple nodes that represent a Func in the IR:
-
The ONAME node (Func.Nname) is used for plain references to it.
-
The ODCLFUNC node (the Func itself) is used for its declaration code. *The OCLOSURE node (Func.OClosure) is used for a reference to a function literal.
*type *Func *struct *{ miniNode Body Nodes
Nname *Name *// ONAME node *OClosure *ClosureExpr *// OCLOSURE node-
*// ONAME nodes for all params/locals for this func/closure, does NOT include closurevars until transforming closures during walk. *Dcl []*Name
*// ClosureVars lists the free variables that are used within a // function literal *ClosureVars []*Name
*// Enclosed functions that need to be compiled, populated during walk. *Closures []*Func ... *// Parents records the parent scope of each scope within a // function. Parents []ScopeID ... *Pragma PragmaFlag *// go:xxx function annotation. *... NumDefers int32 *// number of defer calls in the function *NumReturns int32 *// number of explicit returns in the function. ... *}
func NewFunc(pos src.XPos) *Func { f := new(Func) f.pos = pos f.op = *ODCLFUNC ... return *f }
-
Jump to ./walk/expr.go file and find walkExpr1 function:
*func *walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
*switch *n.Op() {
*default*:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
*panic*("unreachable")
...
*case *ir.*ONOT*, ir.*ONEG*, ir.*OCOM*, ir.*OPLUS*, ..., ir.*OIDATA*:
n := n.(*ir.UnaryExpr)
n.X = walkExpr(n.X, init)
*return *n
...
}
Just to ./walk/walk.go file and find mayCall function:
*// mayCall reports whether evaluating expression n may require
// function calls, which could clobber function call arguments/results
// currently on the stack.
func *mayCall(n ir.Node) bool {
...
*return *ir.Any(n, *func*(n ir.Node) bool {
...
*switch *n.Op() {
...
*// When using soft-float, these ops might be rewritten to function calls
// so we ensure they are evaluated first.
case *ir.*OADD*, ir.*OSUB*, ir.*OMUL*, ir.*ONEG*, ir.*OCOM*:
*return *ssagen.Arch.SoftFloat && isSoftFloat(n.Type())
...
...
}
Run the ./test.sh:
./neg.go:4:13: internal compiler error: ‘main’: unhandled expr COM
goroutine 9 [running]:
runtime/debug.Stack()
/Users/furkan.turkal/src/public/go/src/runtime/debug/stack.go:24 +0x65
cmd/compile/internal/base.FatalfAt(0xc00002414c, 0xc00009ef70, 0x10, 0xc0003cb780, 0x10, 0x2094108)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:227 +0x157
cmd/compile/internal/base.Fatalf(…)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/base/print.go:196
cmd/compile/internal/ssagen.(*ssafn).Fatalf(0xc00039c1e0, 0x0, 0x1922c8b, 0x0, 0xc000064570, 0x1, 0x0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/ssagen/ssa.go:7481 +0x187
cmd/compile/internal/ssagen.(*state).Fatalf(…)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/ssagen/ssa.go:976
cmd/compile/internal/ssagen.(*state).expr(0xc0003f8100, 0x1a7fb68, 0xc00039c1e0)
/Users/furkan.turkal/src/public/go/src/cmd/compile/internal/ssagen/ssa.go:3198 +0x8c44
Here we are. The SSA. Let’s see what SSA means exactly in the next section. It’s time to move on to Compiler Back-End.
4.⠀Compiler Back-End
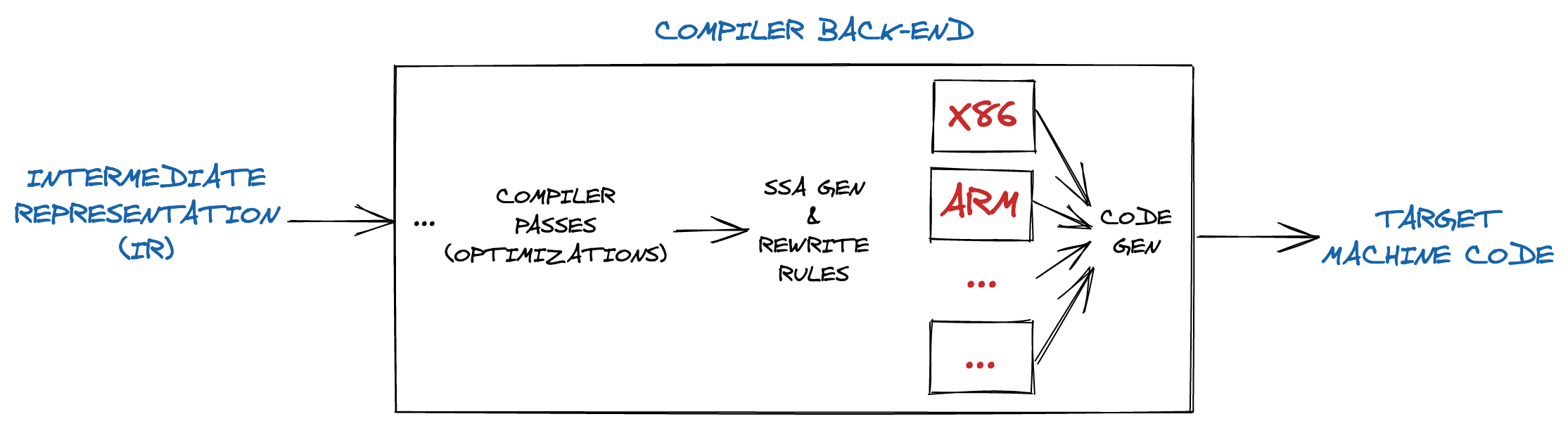 Medium-Level Overview of Compiler Back-End of Go
Medium-Level Overview of Compiler Back-End of Go
Compiler back-end is responsible for the CPU architecture-specific optimizations and code generation.
4.1. Introduction
The main phases of the back-end may include the following:
-
**Machine-dependent optimizations:** optimizations that depend on the details of the CPU architecture that the compiler targets.
-
**Code generation: **the transformed intermediate language is translated into the output language, usually the native machine language of the system.
There are several production compilers for Go: [14]
-
Gc is written in Go with a recursive descent parser and uses a custom loader, also written in Go but based on the Plan 9 loader, to generate ELF/Mach-O/PE binaries.
-
The Gccgo compiler is a front end written in C++ with a recursive descent parser coupled to the standard GCC back end.
You can find the compiler entry point here.
4.2. Static Single Assignment (SSA)
SSA is a property of an intermediate representation (IR), which requires that each variable be assigned exactly once, and every variable is defined before it is used. Existing variables in the original IR are split into versions, new variables typically indicated by the original name with a subscript in textbooks. Every definition gets its own version. In SSA form, use-def chains are explicit, and each contains a single element.
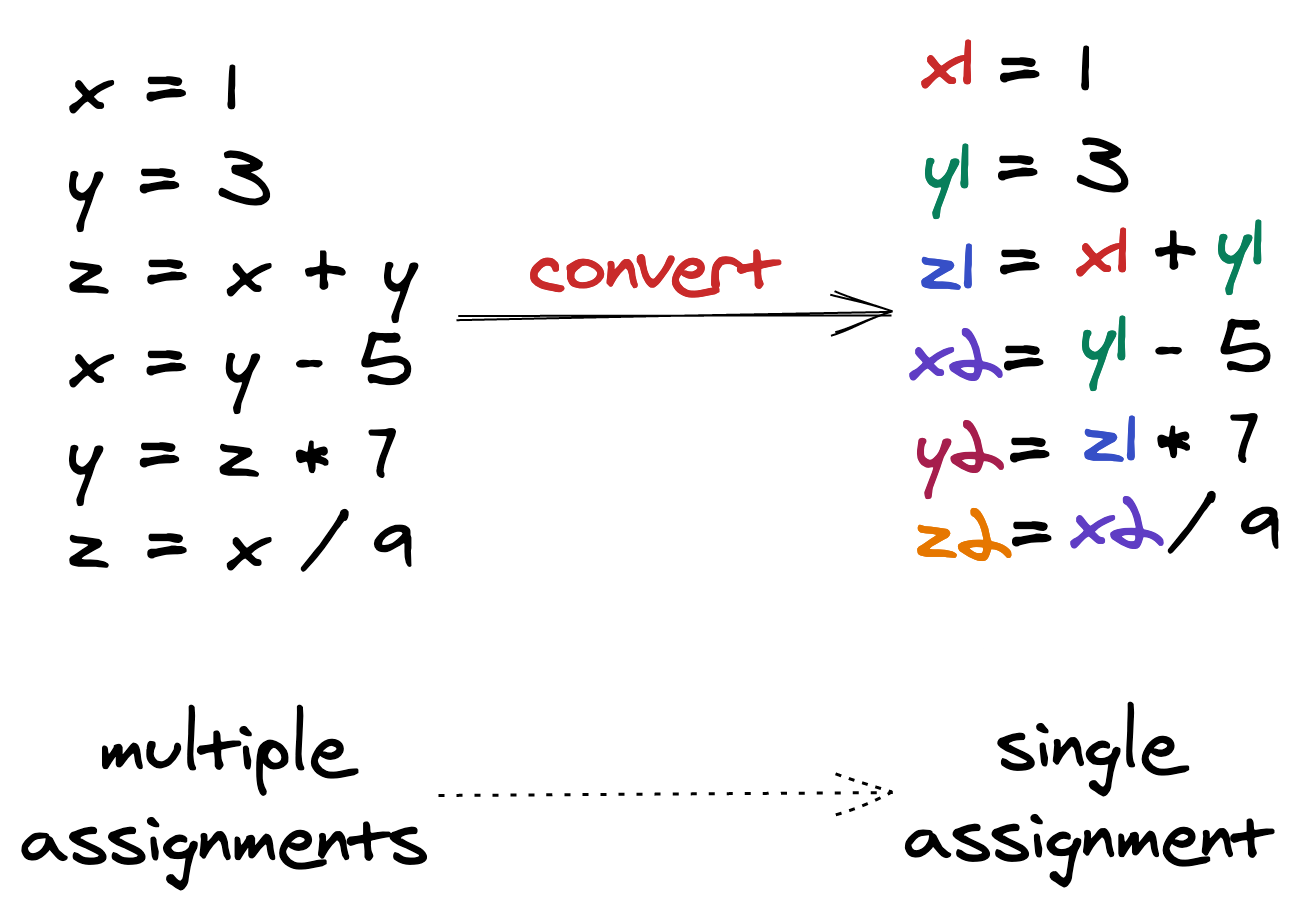 Simple SSA Conversation For Straight Line Code
Simple SSA Conversation For Straight Line Code
Essentially means that each register is assigned exactly once. This property simplifies data flow analysis. To handle variables that are assigned more than once in the source code, a notion of phi instructions are used:
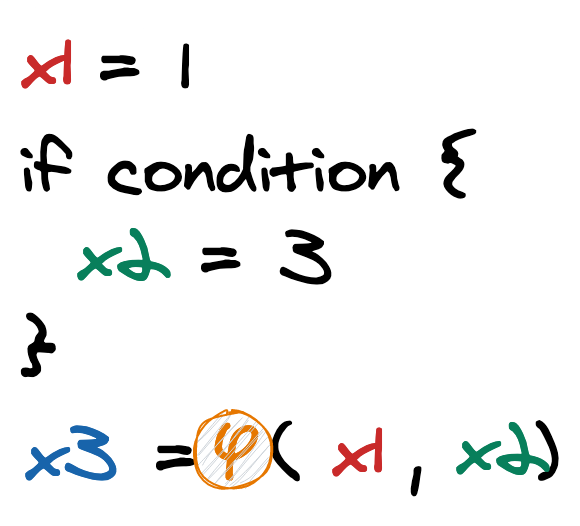 φ instruction
φ instruction
The phi instruction, which is an implicit merge point, is used to implement the φ node in the SSA graph representing the function and takes a list of pairs as arguments, with one pair for each predecessor basic block of the current block, and models the set of possible incoming values as distinct assignment statements. [9]
SSA enables fast, accurate optimization algorithms for: [10]
You can find the list of passes for the SSA compiler here.
You should able to dump your code to SSA using ssadump tool:
$ go get golang.org/x/tools/cmd/ssadump
To display and interpret the SSA form of your Go program:
package main
func main() {
x := 1
y := 2
y += x
x = x + y
println(x)
}
Set your BuilderMode, give a path, and run the following command:
$ ssadump -build=F main.go
It will generate something like:
# Name: command-line-arguments.main
func main():
0: entry P:0 S:0
t0 = 2:int + 1:int int
t1 = 1:int + t0 int
t2 = println(t1) ()
return
# Name: command-line-arguments.init
func init():
0: entry P:0 S:2
t0 = *init$guard bool
if t0 goto 2 else 1
1: init.start P:1 S:1
*init$guard = true:bool
jump 2
2: init.done P:2 S:0
return
P, stands for *predecessors. *How many blocks come into this block. S, stands for successors. How many blocks it flows out to.
When Go meets Assembly.*
Let’s create another example:
package main
func main() {
x := 1
y := 2
z := x
x = y + z
y = x + z
z = y + x
x = z
y = x
x = x + z
println(x)
}
Rerun the ssadump tool, and we will have the following kind of assembly:
 Output of ssadump
Output of ssadump
We can see how they start to flow, how certain variables turn into other variables and compose into other pieces. Which versions of which variables are used where. We can construct the flow through this graph of where our data is going.
4.3. Go’s SSA Backend
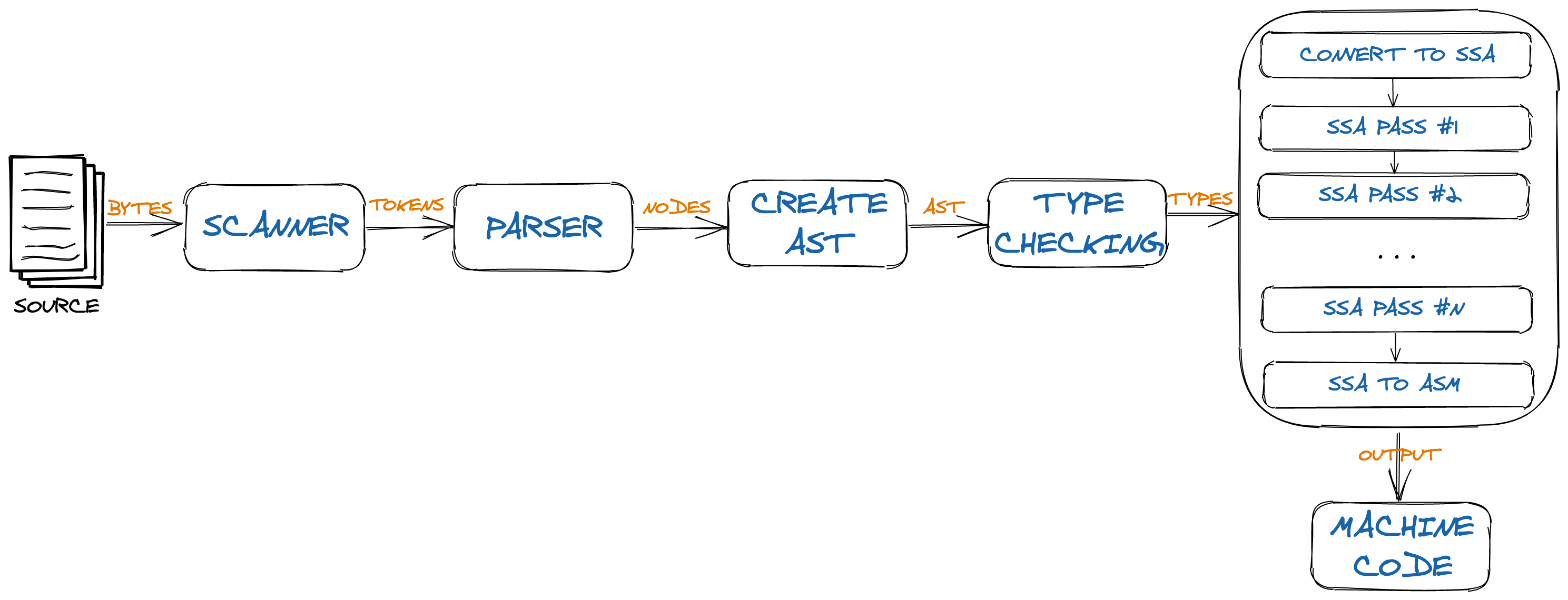 Picture of SSA Flow
Picture of SSA Flow
In this phase, the AST is converted into Static Single Assignment (SSA) form, a lower-level intermediate representation with specific properties that make it easier to implement optimizations and to eventually generate machine code from it.
During this conversion, function intrinsics are applied. These are special functions that the compiler has been taught to replace with heavily optimized code on a case-by-case basis.
Certain nodes are also lowered into simpler components during the AST to SSA conversion, so that the rest of the compiler can work with them. For instance, the copy builtin is replaced by memory moves, and range loops are rewritten into for loops. Some of these currently happen before the conversion to SSA due to historical reasons, but the long-term plan is to move all of them here.
Then, a series of machine-independent passes and rules are applied. These do not concern any single computer architecture, and thus run on all *GOARCH *variants.
Some examples of these generic passes include dead code elimination, removal of unneeded nil checks, and removal of unused branches. The generic rewrite rules mainly concern expressions, such as replacing some expressions with constant values, and optimizing multiplications and float operations.
SSA IR actually implemented at Go 1.17 version, proposed by Keith Randall at 2/10/2015, titled New SSA Backend for the Go Compiler.
I strongly recommend that you should watch *GopherCon 2017: Keith Randall — Generating Better Machine Code with SSA* before we move on next.
Find the ./internal/ssagen/ssa.go file and jump to the expr function:
*/ expr converts the expression n to ssa, adds it to s and returns the ssa result.
func *(s *state) expr(n ir.Node) *ssa.Value {
...
*switch *n.Op() {
...
...
...
*case *ir.*ONOT*, ir.*OBITNOT*, ir.*OCOM*:
n := n.(*ir.UnaryExpr)
a := s.expr(n.X)
*return *s.newValue1(s.ssaOp(n.Op(), n.Type()), a.Type, a)
...
...
...
*default*:
s.Fatalf("unhandled expr %v", n.Op())
*return *nil
}
}
Append the OCOM to ir, types: ssa mapping table:
*type *opAndType *struct *{
op ir.Op
etype types.Kind
}
*var *opToSSA = *map*[opAndType]ssa.Op {
...
opAndType{ir.*OBITNOT*, types.*TINT64*}: ssa.*OpCom64*,
opAndType{ir.*OBITNOT*, types.*TUINT64*}: ssa.*OpCom64*,
...
opAndType{ir.*OCOM*, types.*TINT8*}: ssa.*OpCom8*,
opAndType{ir.*OCOM*, types.*TUINT8*}: ssa.*OpCom8*,
opAndType{ir.*OCOM*, types.*TINT16*}: ssa.*OpCom16*,
opAndType{ir.*OCOM*, types.*TUINT16*}: ssa.*OpCom16*,
opAndType{ir.*OCOM*, types.*TINT32*}: ssa.*OpCom32*,
opAndType{ir.*OCOM*, types.*TUINT32*}: ssa.*OpCom32*,
opAndType{ir.*OCOM*, types.*TINT64*}: ssa.*OpCom64*,
opAndType{ir.*OCOM*, types.*TUINT64*}: ssa.*OpCom64*,
...
}
What! 😶 Did you see what I saw? 🥲 There was an operator that was defined as OpCom! 😱 This means that OBITNOT operator ^ exactly does what we want to implement. I genuinely did not know that even exist! 😞 Oh, man… I just realized it while writing this article along with the code. I decided to go with COM because NEG was reserved for the*- operator*. 🤔 It may be more accurate to use NEG instead of COM for ~. I thought that way because that’s how I saw on AVR Instruction Set Manual at the college (Microprocessors lecture). Thus, I wanted to go with OCOM (One’s [COM]plement) for now.🤷♂️
 Atmel AVR Instruction Set Manual — NEG
Atmel AVR Instruction Set Manual — NEG
Using ^x in languages such as Python, C, etc. causes an invalid compile and throws a syntax error. I should have implemented this myself first before I wrote this article. I have scolded myself already.
In this situation, we may have two things to do:
-
Changing the proposal slightly and propose the remove the use of ^x. We should no longer allow that usage. Not because of to complete our own job — to be more aligned with the usage of the unary syntax just like in other languages. (which will cause l*anguage change)*
-
How could we add a new operator to ssa package ourselves if there is no such thing ssa.OpCom? We will dive into Op generators and architecture rules.
-
It seemed more consistent to use NEG instead of COM for the ~ operator. But NEG was already reserved for - . We should mention that in the proposal to swap OpCodes.
No demoralizing! The important thing is to learn something here! We can easily change the title of our proposal to something like:
proposal: spec: add a built-in tilde ~ (bitwise not) unary operator (op: OCOM), deprecate ^x (XOR) usage
Yes, I know. We have to replace all the ^x usages with the ~x in the compiler itself. Sounds like a Ba Dum Tss!
4.3.1. Generic OPs
Generic opcodes typically specify a width. The inputs and outputs of that op are the given number of bits wide. There is no notion of sign, so Add32 can be used both for signed and unsigned 32-bit addition.
Signed/unsigned is explicit with the extension ops (SignExt*/ZeroExt*) and implicit as the arg to some opcodes (e.g., the second argument to shifts is unsigned). If not mentioned, all args take signed inputs or don’t care whether their inputs are signed or unsigned.
Find the ./ssa/gen/genericOps.go and jump to genericOps struct:
*var *genericOps = []opData {
*// 2-input arithmetic
// Types must be consistent with Go typing. Add, for example, must take two values of the same type and produces that same type.
*{name: "Add8", argLength: 2, commutative: true}, *// arg0 + arg1
*{name: "Add16", argLength: 2, commutative: true},
...
...
...
*// 1-input ops
*{name: "Neg8", argLength: 1}, *// -arg0
*{name: "Neg16", argLength: 1},
...
{name: "Com8", argLength: 1}, *// ^arg0
*{name: "Com16", argLength: 1},
...
{name: "Test8", argLength: 1}, *// ~arg0
*{name: "Test16", argLength: 1},
...
}
In this supposing, we created a new OpCode called Test . We will not use Test OpCode since Neg and Com already defined there. It’s just for educational purposes to wrap up this article.
Jump to ./ssa/opGen.go , we need to implement new Test OpCode by calling $ go generate as already described in the ./ssa/gen/README file. So, run the following command inside the ./ssa/gen directory:
$ ../../../../../../bin/go run *.go
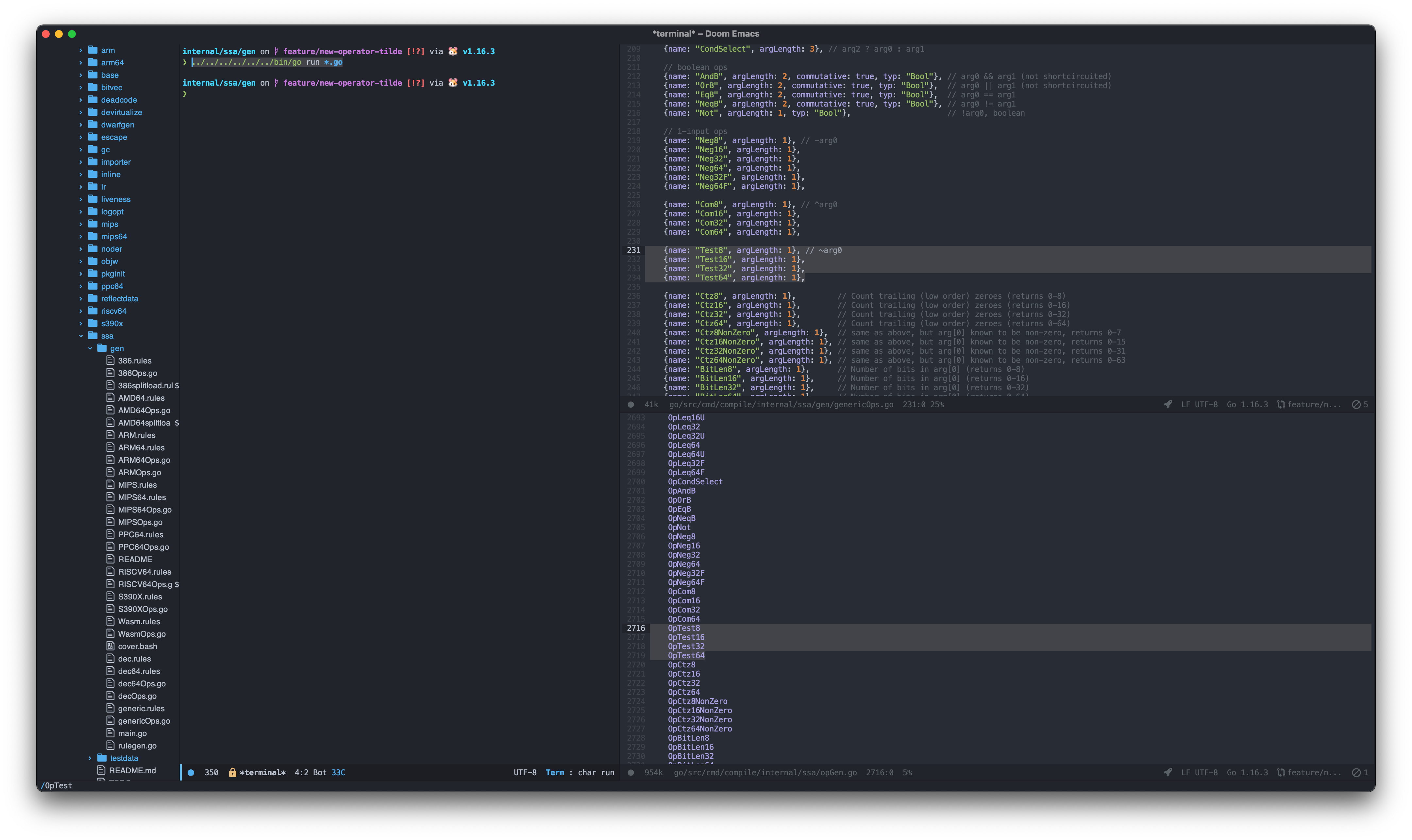
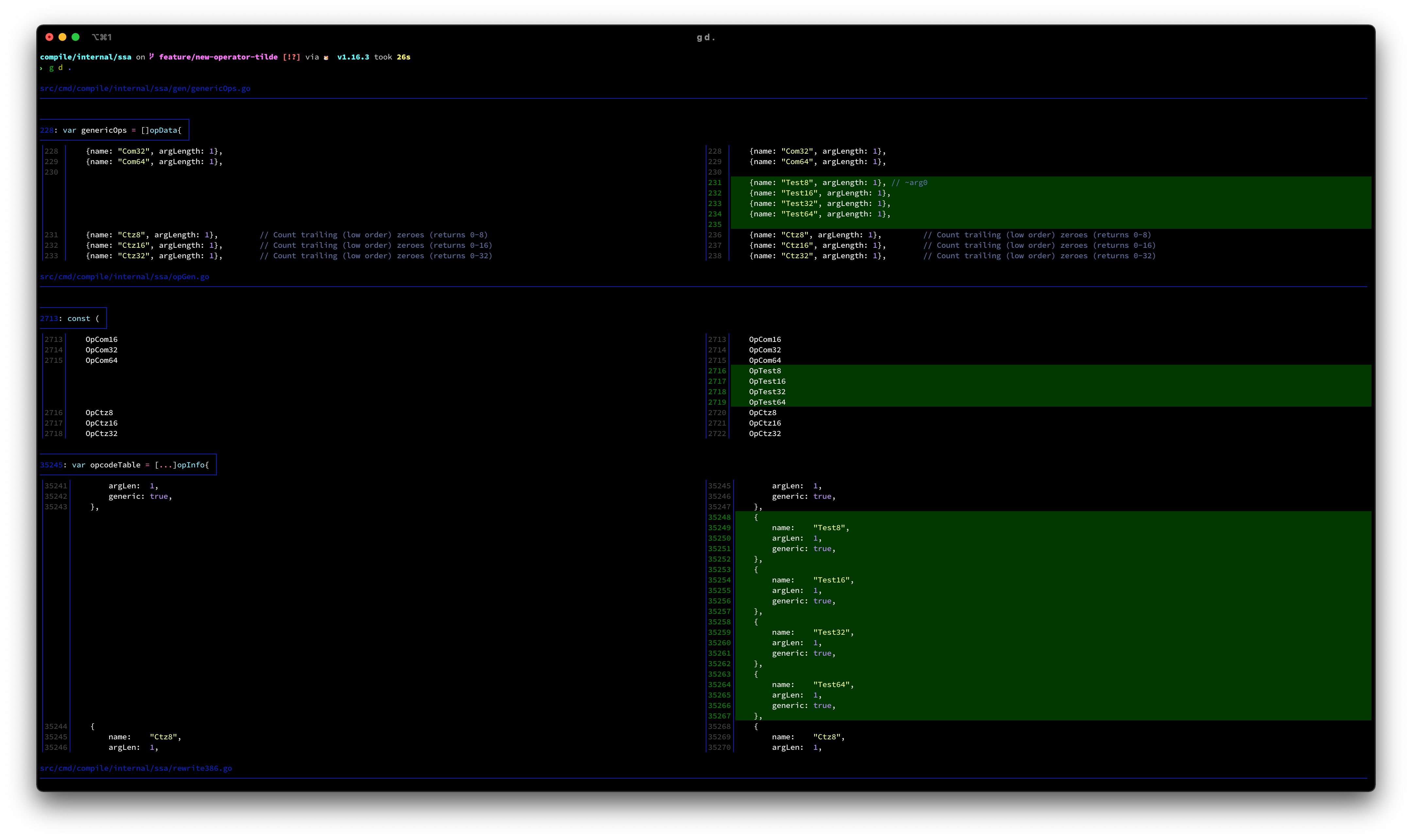
Here is the diff:
4.3.2. Rewrite Rules
Many optimizations can be specified using rewrite rules on the SSA form.
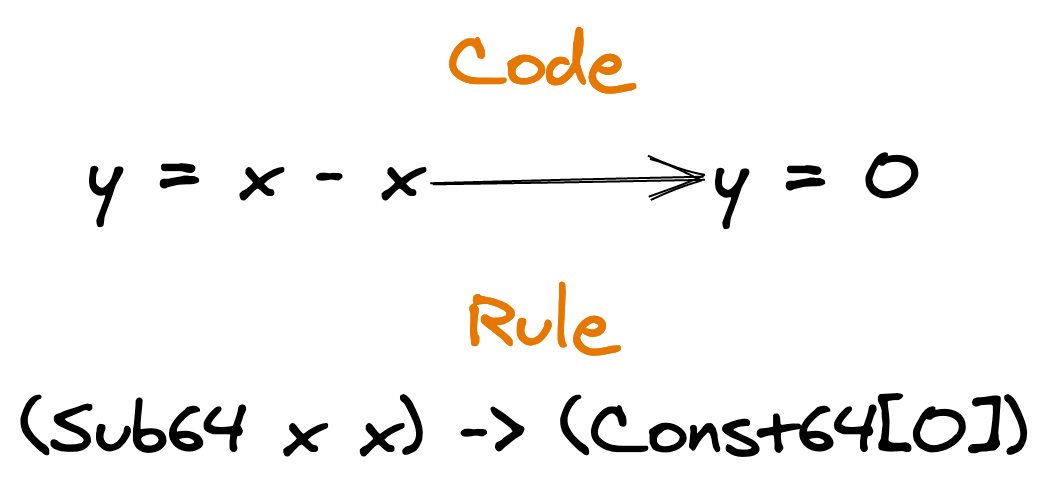 Simple Review Rule for x-x=0
Simple Review Rule for x-x=0
If we have a subtract 64-bit subtract of a value itself, we can just replace the with constant 0. Go has a bunch of optimizations in a big review rule file in the compiler.
 Rewrite Rule Example
Rewrite Rule Example
You can find more examples in the *generic.rules* file, or in the src/cmd/compile/internal/ssa/gen package:
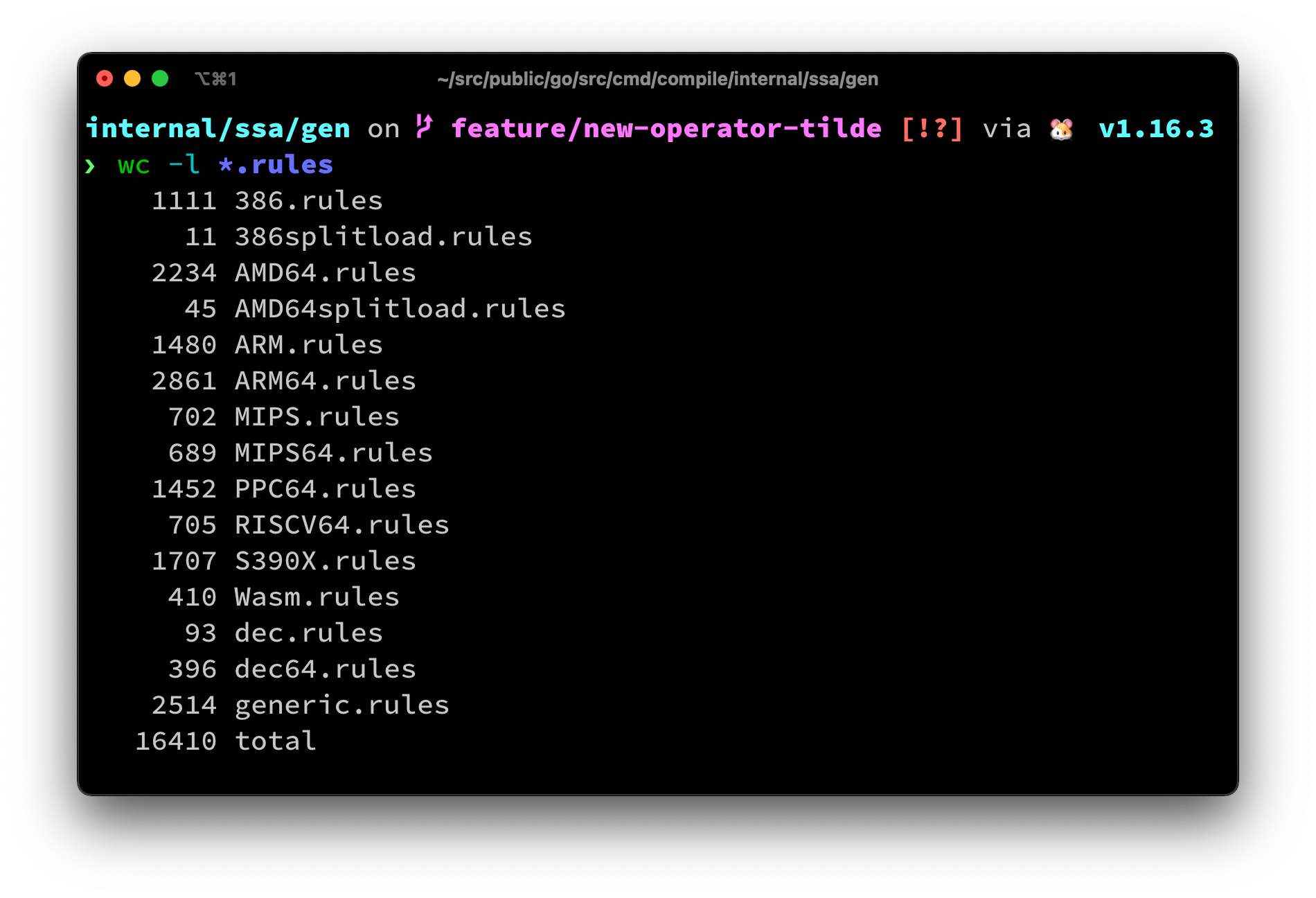 *CLOC of .rules
*CLOC of .rules
Rewrite rules are also used to lower machine-independent operations to machine-independent operations.
-
The OpCodes on the left are the **Go **OpCodes. (written in lowercase)
-
The OpCodes on the right are the ARCH OpCodes. (machine instructions)
(Neq64F x y) => (SETNEF (UCOMISD x y))
(Neq64 x y) => (SNEZ (SUB x y))
(Neq64 x y) => (NotEqual (CMP x y))
(Neq64 x y) => (SGTU (XOR x y) (MOVVconst [0]))
Review rules can get pretty complicated:
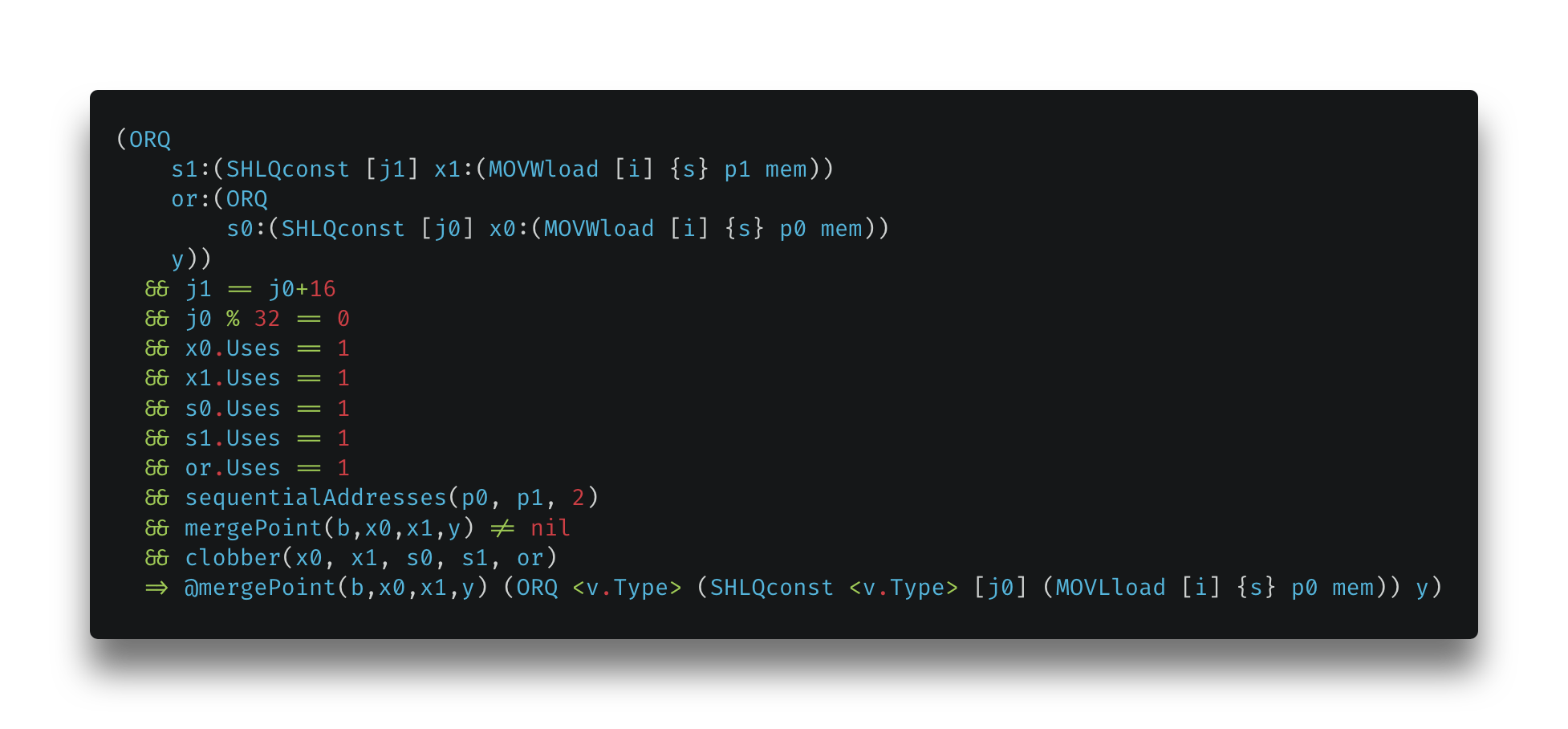
It takes two 8-bit loads and replaces them with one 16-bit load if it can. So, this rule sort of checks all possible conditions under which this rewrite rule can apply. If so, it does the rewrite; and uses one 16-bit load instead. [10]
Converting the compiler to use an SSA IR led to substantial improvements in the generated code:

We can write some optimizations for the~ operator like the following:
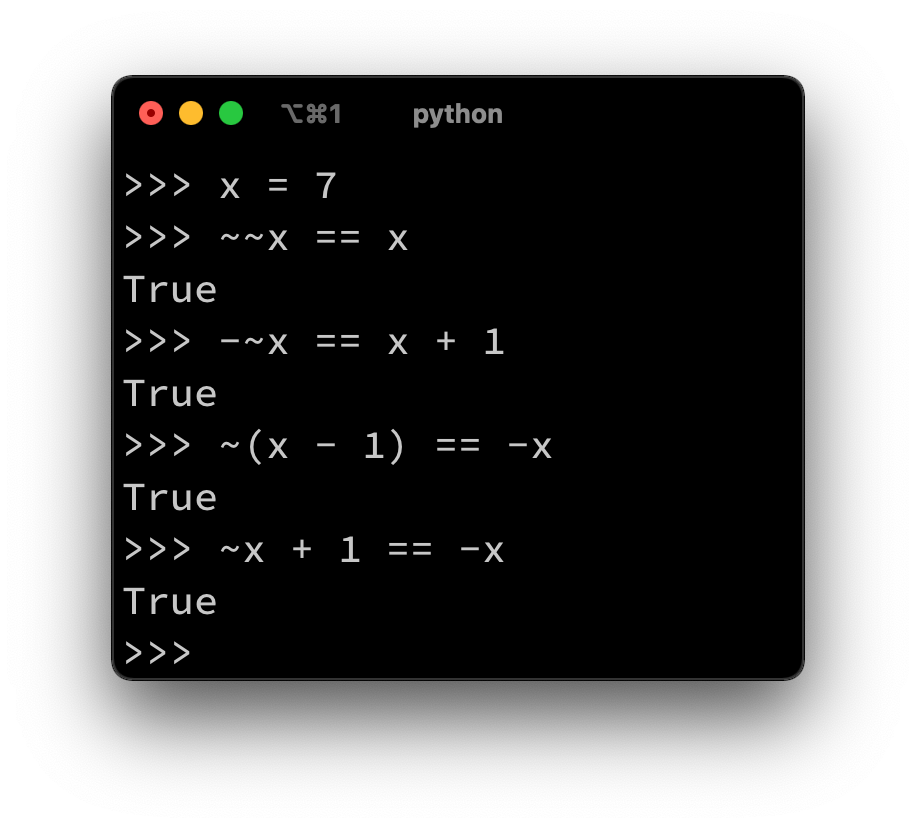 Python Interpreter
Python Interpreter
-
~~x == x
(Com(64) (Com(64) x)) => x
-
-~x == x+1
(Neg(64) (Com(64) x)) => (Add(64) (Const(64) [1]) x)
-
~(x-1) == -x
(Com(64) (Add(64) (Const(64) [-1]) x)) => (Neg(64)
-
~x+1 == -x
(Add(64) (Const(64) [1]) (Com(64) x)) => (Neg(64) x)
Find the generic.rules file and add these instructions to gain some optimizations. We may have to use all power of two values inside the OpCode. Use Com(64|32|16|8) instead Com(64) .
5. Result
The big moment has come. I think there is nothing left we have to do except testing. Have you tried this yet?
5.1. Trying New Operator
It is time to lift the curtain, run the ./test.sh script:
-16
And, boom! It just worked. That’s pretty amazing! Isn’t it?
Let’s do small modifications to the neg.go snippet:
package main
func main() {
x := -15
fn := func() int {
return x
}
println(~fn())
}
It prints 14, which means this works beautifully too. Our ~ operator is now fully functional.
5.2. Test & Build Go Compiler
One more thing before running the tests. Remember Griesemer added Tilde operator with this commit. So, we need to update the ./test/fixedbugs/issue23587.go file, which is no more a failing test case. We have to update the Issue 23587 test file like the following:
*// errorcheck
package *p
*func *_(x int) {
_ = ~x
_ = x~ *// ERROR "unexpected ~ at end of statement"
*}
*func *_(x int) {
_ = x ~ x *// ERROR "unexpected ~ at end of statement"
*}
We want to assert the error the compiler will throw. Thus, we used *errorcheck action here. *We can run the given test file:
$ ./bin/go run ./test/run.go — ./test/fixedbugs/issue23587.go
This test passes. Yay! Let’s see if we broke any functionality in the compiler. Jump to the ./src directory and simply run:
$ ./all.bash
Building Go cmd/dist using /usr/local/go. (go1.16.3 darwin/amd64)
Building Go toolchain1 using /usr/local/go.
Building Go bootstrap cmd/go (go_bootstrap) using Go toolchain1.
Building Go toolchain2 using go_bootstrap and Go toolchain1.
Building Go toolchain3 using go_bootstrap and Go toolchain2.
Building packages and commands for darwin/amd64.
##### Testing packages.
ok archive/tar 2.021s
ok archive/zip 1.937s
...
...
...
ok cmd/compile/internal/dwarfgen 6.948s
ok cmd/compile/internal/importer 1.919s
ok cmd/compile/internal/ir 0.424s
ok cmd/compile/internal/logopt 2.288s
ok cmd/compile/internal/noder 0.862s
ok cmd/compile/internal/ssa 1.226s
ok cmd/compile/internal/ssagen 0.801s
ok cmd/compile/internal/syntax 0.368s
ok cmd/compile/internal/test 25.796s
ok cmd/compile/internal/typecheck 13.242s
ok cmd/compile/internal/types 0.336s
ok cmd/compile/internal/types2 6.691s
...
...
...
ALL TESTS PASSED
---
Installed Go for darwin/amd64 in /Users/furkan.turkal/src/public/go
Installed commands in /Users/furkan.turkal/src/public/go/bin
...
They pass! So, that means… We did a great job! We are done.
You can find the full patch here:
6. Conclusion
I know less is more. Obviously, we do not like reading lots of text in a tutorial in general. I could have kept these brief and make our diagrams talk instead. I was furious at myself after I completed the article. If I was going to ask myself, “What could I do better?” I would definitely start writing this article after I implemented and tried it myself first. I really did not know that ^ is handling the ~ thing.
In this article, we tried to address many compiler subjects at the 201 level. That’s why some of the subjects remained open-ended. Although almost every subject is a completely different world, our goal here was to give a middle-level perspective to the compilers. I do not doubt that feedback will come from the maintainers and contributors for the issue and PR we have opened. Comments such as “we do the exact same thing with the ^ operator. Why we need this?” can be written, and both PR & issue may be closed; or, it can also be considered in terms of aligning with other languages.
I generally think I am a result-oriented person. But not for what we did here; not today at least… We have learned some good things today. I learned different new things about the technical details of the Go compiler while writing this article. Although I am not on the road to being a compiler expert, trying to learn the technical details of compilers gives me confidence. And I am inquisitive about these compiler habitats! Deep diving is beautiful. Much more logical, objective, and scientific. My love will never end! Maybe I will not be a compiler contributor, but I do not doubt that I will keep reading all of their changelogs one by one.
7. Furthermore
If we are on the way to becoming engineers* *of the future, and we just do not want to be consumers or end-users but creators, I think we also need to know how the products we use are created.
I am not sure that knowing a programming language down to its deepest details will teach anything to us. Technology changes all the time; our knowledge is becoming obsolete. We have to keep up with the latest technology changes and updates. So let’s understand instead of memorizing, let’s see instead of hearing, let’s learn instead of ignoring, let’s demonstrate instead of assuming.
If you are fascinated by compilers as I do, if you want to know how it works, you should definitely do not postpone it off. We are not talking about creating a compiler from scratch while sitting and writing code for long hours like zombies. We try to learn new perspectives and knowledge by understanding compiler concepts. There are some great resources out there that should not be missed.
Feature implementation to a compiler is not limited only to Go. Do give it a try on any compiler you want to! So, why not create a brand-new operator for Go, just as we did in this article? What about § operator?
8. References
8.1. Normative
[0] https://golang.org/doc/contribute#contributor [1] https://golang.org/doc/contribute#before_contributing [2] https://stackoverflow.com/a/3952128/5685796 [3] https://golang.org/ref/spec#Arithmetic_operators [4] https://en.wikipedia.org/wiki/Parsing#Parser [5] https://en.cppreference.com/w/cpp/language/operator_precedence [6] https://github.com/golang/go/tree/master/src/cmd/compile#introduction-to-the-go-compiler [7] https://en.wikipedia.org/wiki/Intermediate_representation [8] https://youtu.be/D2-gaMvWfQY?t=216 [9] https://llvm.org/docs/LangRef.html#phi-instruction [10] https://www.youtube.com/watch?v=uTMvKVma5ms [10] https://youtu.be/uTMvKVma5ms?t=1735 [11] https://en.wikipedia.org/wiki/Compiler#Middle_end [12] https://medium.com/a-journey-with-go/go-introduction-to-the-escape-analysis-f7610174e890 [13] https://github.com/golang/go/blob/15a374d5c1336e9cc2f8b615477d5917e9477440/src/cmd/compile/internal/escape/escape.go#L20-L46 [14] https://golang.org/doc/faq#What_compiler_technology_is_used_to_build_the_compilers [15] https://github.com/golang/go/issues/45673#issuecomment-824219940 [16] https://github.com/golang/go/issues/45673#issuecomment-824374682
8.2. Informative
If you spot a typo, find something wrong with the article, have a suggestion to make, or just a question, feel free to contact me: [email protected]
Also, feel free to ping me on Twitter or GitHub anytime.

“Thank you, and have a very safe and productive day!”