chineseocr_lite
 chineseocr_lite copied to clipboard
chineseocr_lite copied to clipboard
超轻量级中文ocr,支持竖排文字识别, 支持ncnn、mnn、tnn推理 ( dbnet(1.8M) + crnn(2.5M) + anglenet(378KB)) 总模型仅4.7M

运行后出现如下报错,不知道是什么原因 2021-11-17 20:10:41.0305976 [W:onnxruntime:, graph.cc:3391 onnxruntime::Graph::CleanUnusedInitializers] Removing initializer '88'. It is not used by any node and should be removed from the model. 2021-11-17 20:10:41.0306080 [W:onnxruntime:, graph.cc:3391 onnxruntime::Graph::CleanUnusedInitializers] Removing initializer...
[web](https://github.com/DayBreak-u/chineseocr_lite/blob/3f0a6c40873b36c29c84223860d7807a6da77c43/backend/webInterface/tr_run.py#L51) 服务里的参数实际为`img`,所以示例参数里的`image`应该为`img`。

Who can share the APK installation package of the OCR demo generated by TNN, I want to test it.
程序在开发电脑上运行正常,拷贝到其他电脑时运行报错,请大神指导下,谢谢 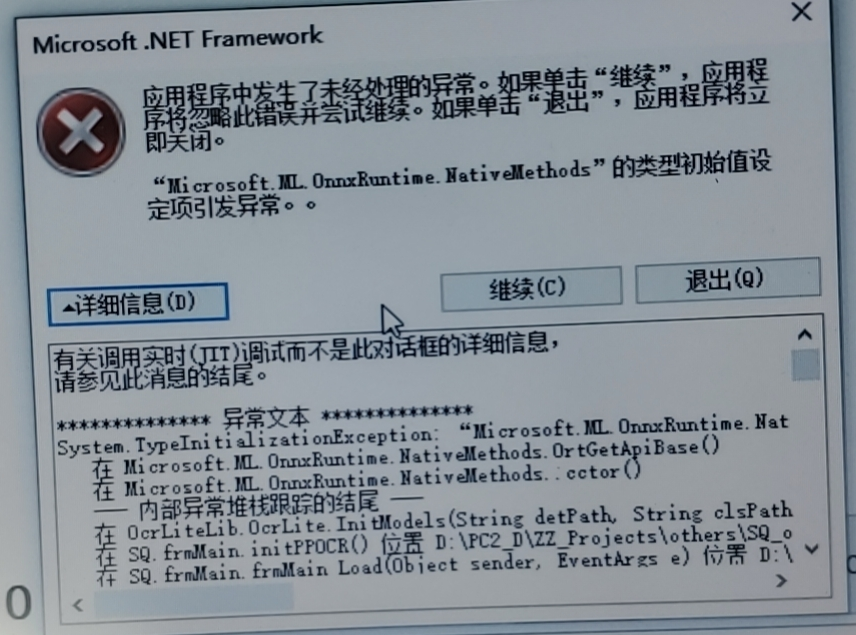
Metadata
Owner
Metadata
超轻量级中文ocr,支持竖排文字识别, 支持ncnn、mnn、tnn推理 ( dbnet(1.8M) + crnn(2.5M) + anglenet(378KB)) 总模型仅4.7M