integrations-core
 integrations-core copied to clipboard
integrations-core copied to clipboard
Redis latency measurement is impacted by agent load
The method used by the Redis integration to calculate latency can be influenced by the load of the agent since it counts the time it takes from the agent not only from the result of redis info command side.
This bug report is divided in 2 parts: facts from tests + theory why this is happening.
Reproducing
Steps to reproduce the issue:
- Start an agent with a few dozen integrations for Redis
- Leave it running and notice stable measurement levels for Redis latency (not many outliers)
- Add many more integrations for other non-Redis things (e.g.: Postgres, MySQL, ...)
- Notice the agent starts to show outliers for Redis latency measurements
Important:
- The number of Redis clusters did not change during the observed period
- The number of integrations did not change during the observed period
- Unifying the integrations into a single "agent host" was the only change performed during these "tests"
Describe the results you received:
Using the agent with Redis only:
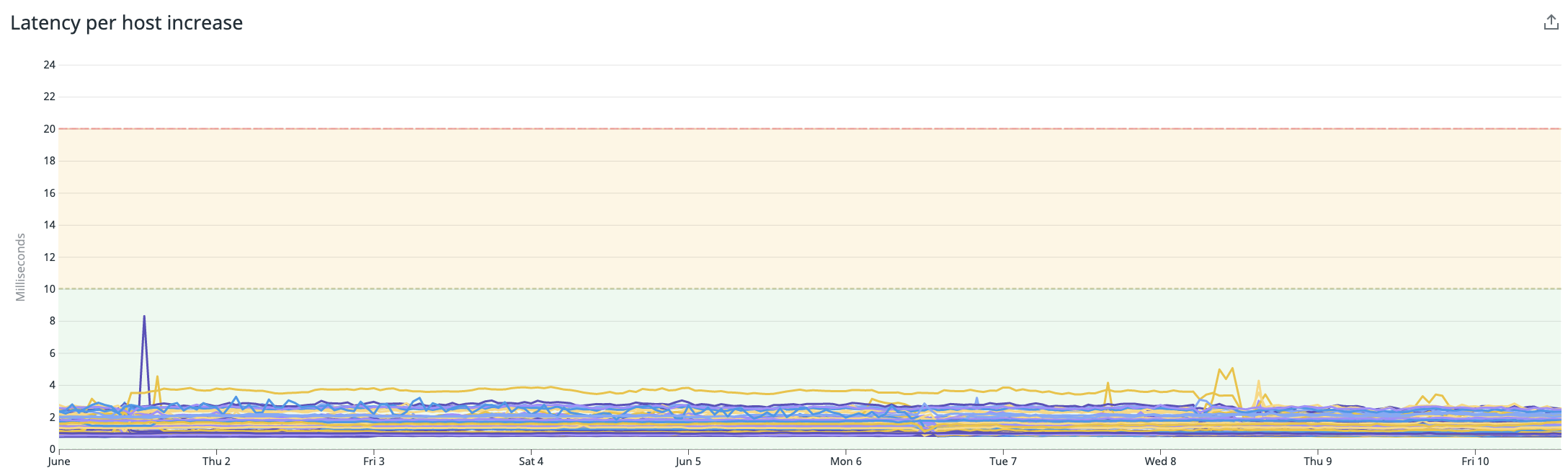
Notice that latency is stable under 10ms, mostly under 5ms for many instances.
Using the agent with Redis + Many other integrations (in the same host):
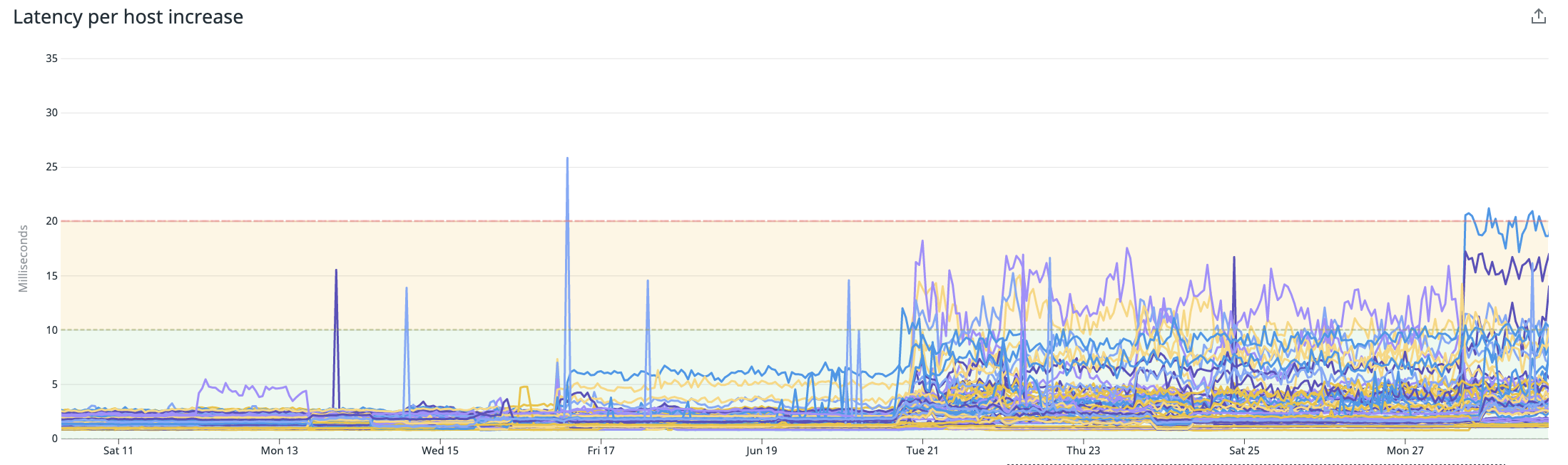
Notice the random increase in latency, nothing else was observed to change during this period. The change seems progressive because of the rollout as well, outliers can be easily perceived earlier in the process and become more and more common as more integrations were added to the same agent.
Splitting integrations the agent with Redis having its own "host" again:
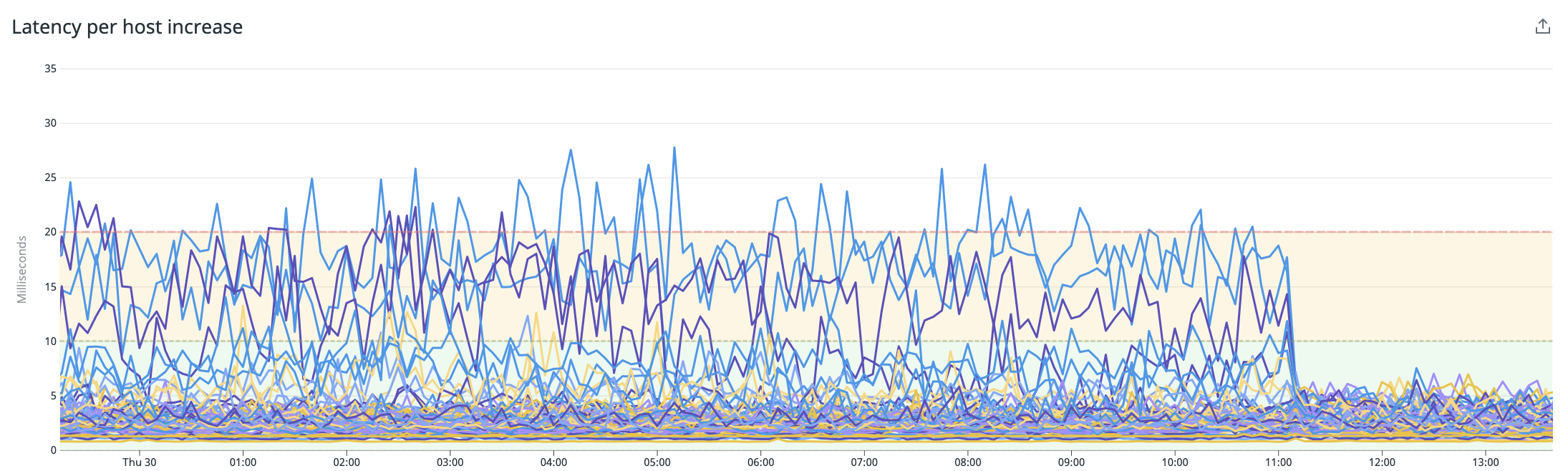
Reverting the changes, splitting the agents per integration likely reduce the load which caused latency levels to magically go back to normal.
I've tested going back and forward with this and it re-introduces the problem, so it can't be simple causality.
Describe the results you expected:
I expected latency to not be impacted by more/less clusters/integrations measured.
Theory
Additional information you deem important (e.g. issue happens only occasionally):
After checking the integration code, it seems that the way latency is measured is influenced by external factors, like thread context switch, IO interrupts / resource availability, and even Python's GIL.
https://github.com/DataDog/integrations-core/blob/master/redisdb/datadog_checks/redisdb/redisdb.py#L200-L204
start = time.time()
tags = list(self.tags)
try:
info = conn.info()
latency_ms = round_value((time.time() - start) * 1000, 2)
The theory I have is that:
- a thread is running
- the
start = time.time()runs and stores "now" - an IO event is triggered by
conn.info()to run the TCP command - context switch happens since thread context switch in python is IO-driven
- other integrations run and have their connections and IOs
- IO finishes (the info command results and it takes "5ms")
- NO resource is available for context switch during threads interruption so it WAITS
- eventually a resource is available and the context is back to this thread
- the thread took 10ms waiting
- the total latency is measured as
time now - time beforeresulting on 15ms
and this happens more and more frequently as one adds integrations to the agent since more context switches and IO interrupts will happen, making threads wait ...
The weirdest is that if any other integration consumes time this gets influenced too... I hope no other integration suffers from this but anywhere time is counted between IO operations in python you will have this behavior.
Hi @marceloboeira,
When you say “The number of integrations did not change during the observed period“, what do you mean exactly? I think you are actually adding integrations as part of your test.
In your theory you are right, it is adding latency as it occurs on the same server and depends on the disk, system configuration, priorities between processes, etc...
Sorry, that it was unclear.
The number of integrations did not change during the observed period
It should be:
The number of integrations of the same type did not change during the observed period - Meaning, we did not add more "redis" to notice the "Redis" latency increase, it was by adding integrations of other types (Postgres/MySQL...).
It looks like this has been fixed with https://github.com/DataDog/integrations-core/pull/12505
Is that correct?
Yes. This fix is available with the version 4.5.2 of this integration and bundled with the agent 7.39.0