Stats computation with DDSketch
Motivation
Currently, sending 100% of traces from the application to the Datadog Agent was hitting multiple limits:
- High cost of encoding traces in the application
- High cost of decoding & handling traces in the Datadog Agent
- Customer imposed CPU limits on trace agent to control ingestion costs
When the agent CPU limit is reached, the trace agent is unscheduled and temporarily unavailable (for example, on Kubernetes, the pod is killed) for multiple seconds. The tracers retry sending payloads if the agent can’t be reached, but if the situation is persistent, tracers will drop payloads. We have no control over this payload dropping, thus it leads to incomplete traces, and wrong stats.
The current solution is to drop a portion of the traffic in the tracer, and have the agent naively upscale stats. But this leads to incomplete traces, and inexact stats.
To solve this problem, we decided to compute stats directly in the tracer, and so being able to do sampling of traces directly in the application without affecting the fidelity of stats.
What does this PR do?
An simplified illustration of design
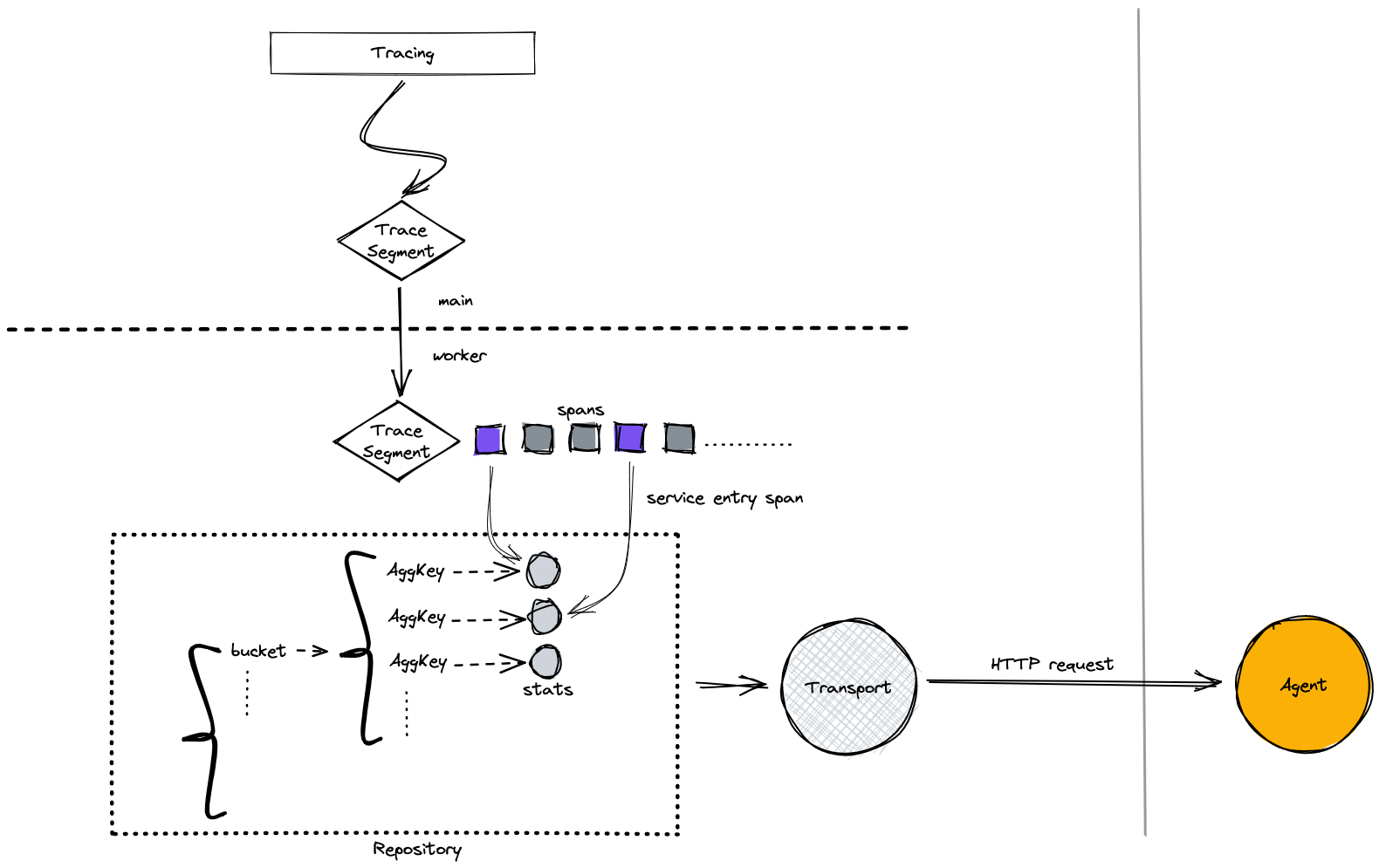
Configuration
- [x] Configure with environment variable
DD_TRACE_STATS_COMPUTATION_ENABLED, default isfalse - [x] Import DDSketch
- [ ] Check
google-protobufdependency
Collect data
- [x] Identify candidates(service_entry_span or
'_dd.measured' == 1) for stats computation - [x] Calculate bucket_time
- [x] Calculate aggregation key, see Obfuscation
- [x] Collect stats with
ddsketch
Transport data to agent
- [ ] Flush the data every 10 second
- [ ] Agent endpoint
v0.6/stats - [ ] Serialise
ddsketchobject into protobuf before encoded into message pack for stats request
Optimize resource
- [ ] Update request header for traces with
Datadog-Client-Computed-Stats: yes, to avoid duplicate stats computation in agent - [ ] Drop p0 trace
Additional Notes
Obfuscation
Obfuscation is recommended to apply for span.resource, in order to reduce the cardinality of data. However, currently, we have not reach consensus on its specification and implementation across different languages.
Question: Can stats computation in tracer work without obfuscating resource?
Answer: Yes, but the design is not efficient. It would prevent data being aggregated in the same bucket and defies the purpose of leveraging DDSketch. Eventually, Datadog agent would still obfuscate the resource and merge those sketches.
How to test the change?
TBD
@TonyCTHsu given that adding ddsketch has not been a priority, should we go ahead and close this PR?
We ended up not using this, so I'm going to go ahead and close this for now :)