Failing jobs: status not instrumented with active_job, traces missing with resque
active_job not instrumenting error status
I created this test job:
class FailingJobToDebugDatadog < ActiveJob::Base
queue_as :background
def perform
raise "This is a debug job to test Datadog"
end
end
With this configuration:
config.tracing.instrument :active_job, service_name: "active_job"
In Datadog it doesn't register any error, the status of these traces is OK.

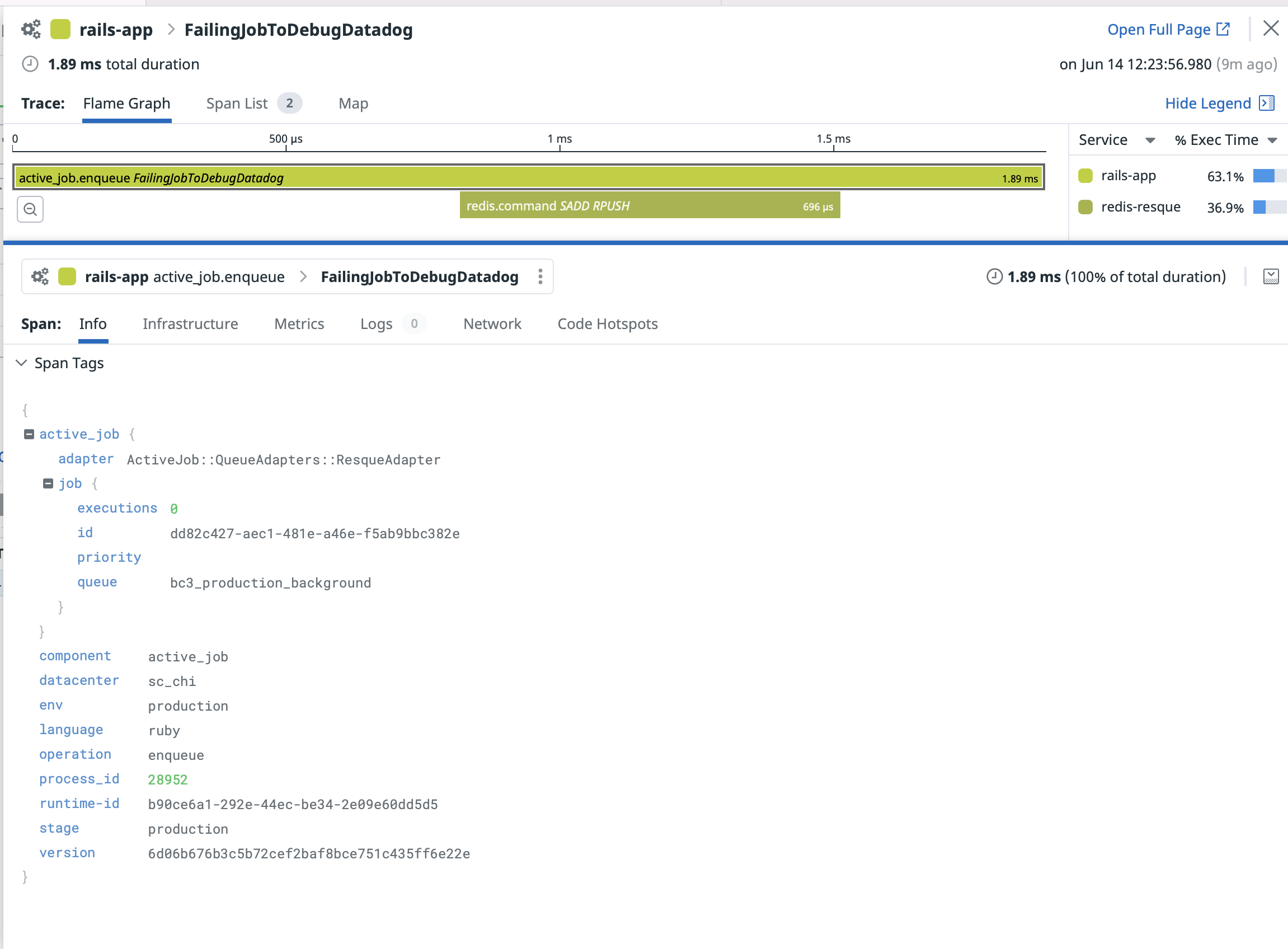
This makes it impossible to query for failed jobs.
resque missing jobs that fail
With resque I have other problem: these traces aren't even being collected. They are only collected by active_job with an ok status:
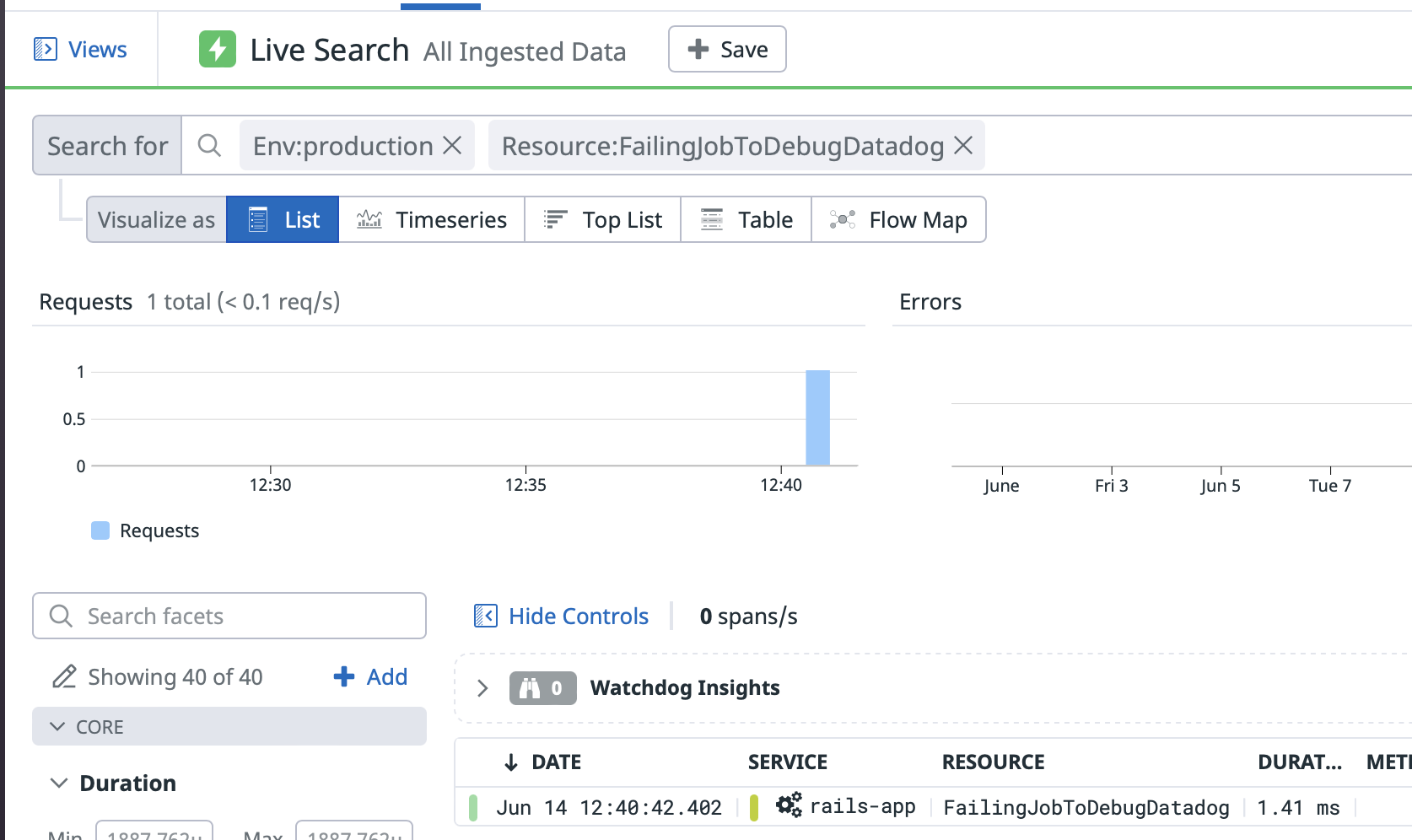
Other jobs traces are normally collected by resque (the instrumentation is working).
My resque config:
config.tracing.instrument :resque
I'm good with going with either active_job or resque, but none is working well. I have tried to remove the resque integration and the problem persists.
The missing error is an interesting case because spans have some degree of built in error-handling: they will catch, tag, then rethrow errors. Is it possible ActiveJob or the job running framework is handling the error before it bubbles up to the trace entry point?
One way to test this is to trace around the error, within the job itself. It should tag the error on the new span. If not, that would be concerning. If so, it's more likely the framework is intercepting the error before we do. If this is the case, we may have a means of mitigating this.
There may be a few reasons for missing job traces: if the instrumentation itself failed, or if the root span failed to transmit are possibilities. resque is interesting because of how it forks short living processes to handle jobs... this doesn't play nice with our background worker that submits traces. I think I'd need more details about how your Resque process is configured, so we can try to replicate this.
I patched this for active_job like this:
module DatadogSetErrorOnActiveJobPatch
def set_common_tags(span, payload)
super
report_if_exception(span, payload)
end
end
Datadog::Tracing::Contrib::ActiveJob::Event::ClassMethods.prepend DatadogSetErrorOnActiveJobPatch
Currently, active_job APM instrumentation relies on Rails instrumentation but it's not considering the errors flagged by it (normally collected in the perform event).
Thanks for sharing the patch. We'll experiment with this, may incorporate it if it produces desirable behavior.
Hi @jorgemanrubia, I have taken a look into this scenario and try to reproduce in https://github.com/DataDog/dd-trace-rb/pull/2186 . (with Ruby 2.7 and Rails 6)
In this PR, I could verified the jobs(ActiveJob/Resque) have been enqueued within the request/response cycle, hence the http request is considered successful without an error. This enqueue operation typically generate two spans, activejob.enqueue and redis.command(SADD RPUSH).
When a worker picks up the job in the background and executes the job. This would generate another two spans, resque.job and activejob.perform. The PR made the job execution randomly failed and I could verified the error has been recorded in the tab on Datadog.
Typically, my guess would be that your error from job is handled by ActiveJob callbacks or some error handler from the configuration to prevent the exception being propagated. However, from the snippet provided, it was not the case. Is there anything I possibly miss out?