ddtrace/tracer: use sync.Pool for payload to improve performance
I noticed when using pprof on a production server that the datadog tracer is doing a non-trivial amount of heap memory allocation (about 13% in our case while the rest of the code is not especially memory efficient).
Zooming in and following the code, you can see that pretty much all of those allocations are done in payload.buf when data accumulate there and the buffer need to grow:

Have you considered using sync.Pool to reuse those buffers instead of reallocating and growing the buffer for each trace? That would likely reduce the pressure on the GC and be more efficient.
Yes, to be clear the flamegraph I posted show the heap allocations during a time period, not the memory used at a specific time (that is, not the "permanent" allocations). Unit is in bytes, not in number of allocations.
This view is also zoomed in on the tracer part (~13%) and ignore all the application specific part (87%), including some other small allocations when doing tracing (those are minor though). This is why it looks like 100%.
My point is, using a sync.Pool would almost entirely remove those 13% of allocations and reduce the pressure on the GC.
Hi Michael!
Thanks for the analysis.
I see what you mean. I haven't worked on this part for a while, but as far as I remember, we've tried this and had some issue with a race condition. The difficulty lies within the fact that the payload is sent to the transport here, and then subsequently to the HTTP client here. This happens in a go routine while technically "in parallel" a new payload is prepared so that it can immediately be used while the flushing happens.
Now, if we were to place the "old" payload onto the pool after the HTTP send returns, it would present a risk because the HTTP client is known to potentially continue accessing the request body even after the (*http.Client).Do call returns. Granted, my memory of this event and attempt might be wrong. Also, since I've tried this last, we've added a wait-close mechanism to fix a similar race and that might ensure a payload is "done with".
Just some thoughts to keep in mind if we attempt this.
Yes, we've seen this issue from time to time. Reusing payload buffers is a great idea and would likely help the allocation issues.
I'm in support of investigating this and seeing if we can avoid the issues @gbbr mentioned.
We're running into an odd but similar problem here where the majority of our heap consists of objects from makeSlice that aren't garbage collected. I'm quite lost as to how this has happened.
We're using Datadog's Continuous Profiler, and we can see that the makeSlice method somehow has 400MiB, which is about 80% of our heap live objects.
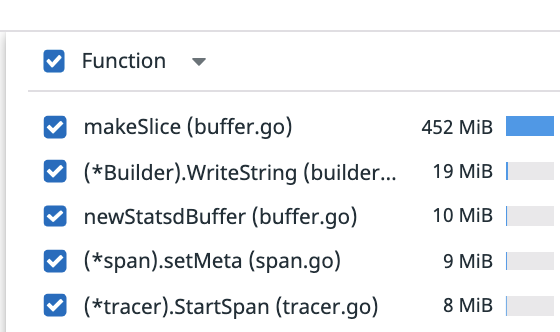
Situation is:
- We kick off a code path that spawns a lot of queries to our database, all of which are traced via Datadog's Gorm integration.
- We see spikes in our memory usage but then somehow the new steady state is significantly higher in memory usage and not being cleaned up by Golang's garbage collector.
- In the same time frame, we're seeing thousands of dropped traces from Datadog's Agent Trace Writer, and then we also see this from the Cluster agent: "2021-07-02 23:07:20 UTC | TRACE | WARN | (pkg/trace/writer/trace.go:252 in recordEvent) | Trace writer payload rejected by edge: 413 Request Entity Too Large"
Here's another screenshot of the profile (not the full profile):

As a result, we're having to turn off our tracer. We suspect that we ran into this problem now as compared to the past because Datadog advised us to use the tracing without limits and do ingestion control at the Datadog side. Let us know what you recommend or if there's something I'm missing.
@shannontan-bolt 👋 sorry to hear you're running into issues! I work on the profiler, but maybe I can help a little bit as well : ).
We have an app we use for internal testing called go-prof-app that has an endpoint that does 2 SQL queries and burns a bit of CPU time. It's instrumented with profiling and tracing, and we're hitting it with 500 requests / second.
I just looked at the Heap Live Size for the app (using 1h aggregation), and the overhead I'm seeing for this code path (and the tracer in general) is much lower:

The picture below shows all Heap Live Size allocations of the tracer highlighted in the overall picture.
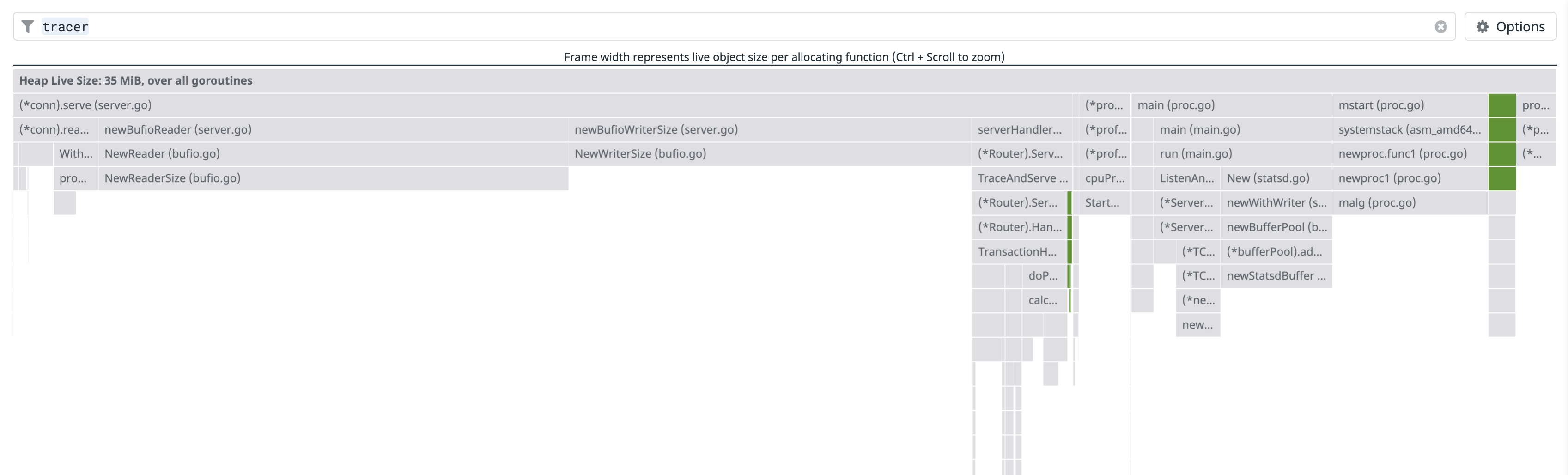
Based on this I suspect that the overhead you're seeing may not be inherent to tracing, and we might be able to figure out how to get rid of it.
My initial ideas on what might be going on:
- The agent is overloaded, forcing the ddtrace/tracer to hold on to payloads while retrying / waiting for confirmations. (not sure about the retries)
- The payloads are excessively large for some reason (huge values inside of the tags or something)
Would you be able to check if either of those two things might be happening in your environment? Seeing the graphs for these tracer metrics could also be interesting.
Again, I don't work on the tracer, so I might be wrong about some details here, but hopefully the above will be helpful.
@felixge Thanks for the response. In terms of tracer metrics, we see above ~50k traces dropped. Flush duration spikes, but not considerably high (~160ms max 95percentile). Besides dropped traces + flush duration, is there anything else that we should look at?
"2021-07-02 23:07:20 UTC | TRACE | WARN | (pkg/trace/writer/trace.go:252 in recordEvent) | Trace writer payload rejected by edge: 413 Request Entity Too Large"
@shannontan-bolt which agent version are you running? The agent part with the 413 response is possibly a separate issue.
@gbbr looks like 7.24.1 (I think). I'm not a Kubernetes expert, but that looks like what we're pulling from GCR.
@gbbr do you think agent version is related? I'm not entirely sure what is at fault here - it makes sense that the agent rejects too large of a payload, but that shouldn't lead to a buildup in the buffer that is unending.