Movie-scrapy
 Movie-scrapy copied to clipboard
Movie-scrapy copied to clipboard
Published
20 hours ago •
 Danielyan86
Danielyan86
时光网电影数据和海报爬虫
准备环境安装
- 测试环境 MacOS-10.15.4
- python 版本3.6.10
- pip install -r requirements.txt
安装MongoDB
- 安装文档 https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/
- the configuration file (/usr/local/etc/mongod.conf)
- the log directory path (/usr/local/var/log/mongodb)
- the data directory path (/usr/local/var/mongodb)
运行
- brew services start [email protected]
执行爬虫
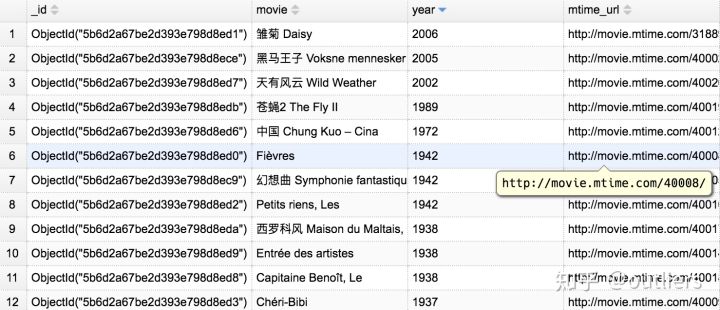
- 此程序有两个爬虫,一个mtime是爬取电影名字,年代和页面链接放入本地mongoDB,另外一个是下载图片到本地文件夹
运行数据爬虫
- scrapy crawl mtime 注意需要修改setting 中的ITEM_PIPELINES配置为movie.pipelines.MoviePipeline,
运行图片爬虫
- scrapy crawl mPicture
- 注意需要修改setting 中的ITEM_PIPELINES配置为 movie.pipelines.MyImagesPipeline,
- ITEM_PIPELINES中的IMAGES_STORE为图片文件保存路径
- IMAGES_MIN_HEIGHT和IMAGES_MIN_WIDTH为图片筛选参数,只有大于这个尺寸图片才会被保存在本地

更多详细介绍
- https://zhuanlan.zhihu.com/p/41733996