uwu
 uwu copied to clipboard
uwu copied to clipboard
Doesn't scale properly with the number of threads used.
I ran some benchmarks and noticed that the throughput reaches an optimum with 4 threads and starts decreasing afterwards:
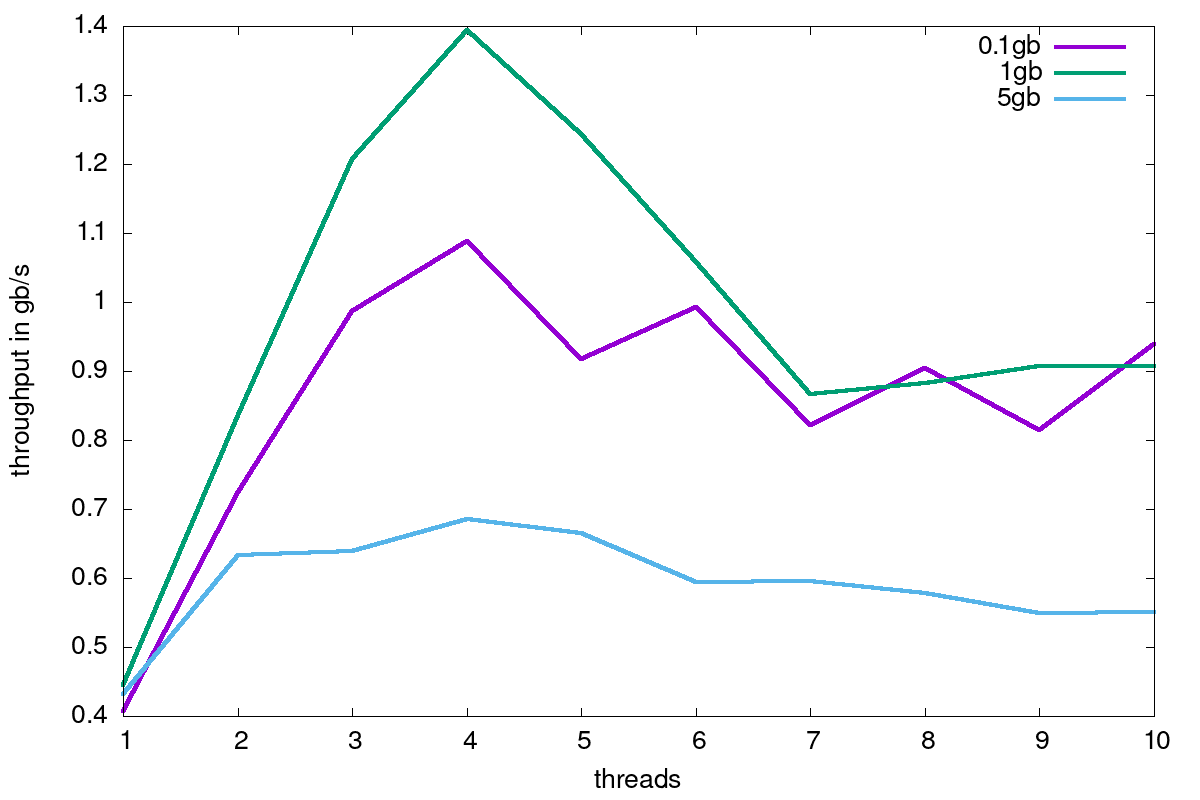
0.1 gb 1gb 5 gb
1 0.4067 0.44447 0.43217
2 0.7244 0.83551 0.63393
3 0.98752 1.20703 0.63876
4 1.08851 1.39454 0.68621
5 0.91721 1.24367 0.66534
6 0.99265 1.05864 0.5936
7 0.82179 0.86623 0.59534
8 0.90496 0.88324 0.57842
9 0.81467 0.90776 0.54953
10 0.93938 0.90655 0.55023
(Ran on an AMD Ryzen 5 1600X Six-Core Processor CPU)
the threads need to synchronize to do file IO, so that becomes a bottleneck as the number of threads increases
on my machine with 8 cores, i found the optimal setting to be 8 threads
thanks for running the benchmark though, its very informative
@camel-cdr You can only archive perfect scaling if 100% of the code can be run in parallel, you can use Amdahl's law to determine the theoretical speedup.
@Daniel-Liu-c0deb0t I didn't dig into the code but technically if the length of the data is not changed (ie. because you will never change a multi-byte char into a single-byte char or vice versa) you can pre-allocate the output file (ie. seek(length, SEEK_SET)) and then you can have each file have it's own file pointer writing only the portion of the data.
In this way you wouldn't need locking.
Also, if you are not doing it, cpu pinning helps a lot with the SSE4.1 instructions because you will not end-up asking the same units to process the data. When you do the pinning you will need to identify the cpu id via something like thread_index % cpu_count.
In general it's worth to run about 2 threads per core, especially because you are doing IO.
Swapping data out from L1/L2/L3 during the data processing is fine, it's very bad though to access the memory so it would be worth to process chunk sizes of an appropriate length (you can fetch the cpu cache sizes dynamically and calculate it at runtime).
unfortunately, pre-allocating an output file isn't possible because stuff like adding emojis can change the length of the data
cpu pinning is a good idea. im not doing it rn (the user passes in the number of threads), but it could be added. though in theory the os should be able to spread threads evenly between cores if you pass in a reasonable thread count.
i do try to keep stuff in cache. each thread has its own buffer that should fit in L2 cache. its a fixed size of 64kb rn, as i did not implement checking cpu cache sizes