flinkStreamSQL
 flinkStreamSQL copied to clipboard
flinkStreamSQL copied to clipboard
基于开源的flink,对其实时sql进行扩展;主要实现了流与维表的join,支持原生flink SQL所有的语法

配置文件 CREATE TABLE kafka( id varchar )WITH( bootstrapServers='10.10.14.117:9092', timezone='Asia/Shanghai', groupId='ddd', parallelism='1', topic='ddd', offsetReset='latest', sourcedatatype='dt_nest', type='kafka'); CREATE TABLE es( id varchar )WITH( sourceid='b93d1e56-0b17-4855-a60f-bd18fd245a78', cluster='aiops-cluster', address='10.10.14.51:9200', parallelism='1', index='myresult', estype='_doc', authMesh='false', type='elasticsearch'); insert...
yarn-session.sh -n 1 -s 1 -jm 768 -tm 1024 -qu default -nm test -d >> /var/log/flink/flink-setup.log 这里的-d 参数没有生效啊,不是分离模式,并且 -nm test自定义 名称 也没有生效????啥问题,大佬麻烦看看 ![Uploading image.png…]()
例如读kafka09写入kafka11,我测的好像会造成jar包冲突,报错 java.lang.NoSuchMethodError: org.apache.kafka.clients.producer.ProducerRecord.(Ljava/lang/String;Ljava/lang/Integer;Ljava/lang/Long;Ljava/lang/Object;Ljava/lang/Object;)V
---kudu维表语句 CREATE TABLE side_rt_d_spu_sku_relation( spu_id int, sku_ids varchar, PRIMARY KEY(spu_id), PERIOD FOR SYSTEM_TIME )WITH( type ='kudu', master ='xxxxxx' tableName='d_goods_wlm_sku_rel', cache ='LRU', cacheSize ='10000', cacheTTLMs ='60000', parallelism ='1', partitionedJoin='false' );
**报如下错误:** 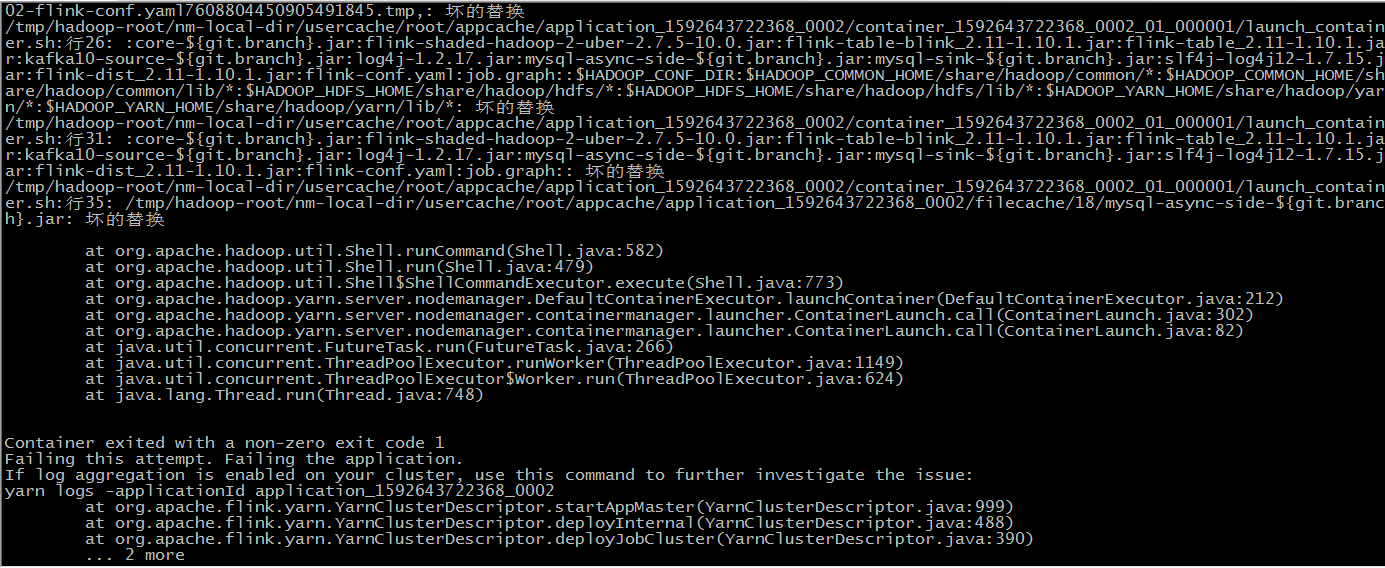 **提交命令如下** 
目前,Kafka-Source插件csv数据格式,用于读取kafka消息,使用的是flink官方的CsvRowDeserializationSchema(调用jackson-dataformat-csv的API进行解析),只支持单字符分隔符。是否考虑添加多字符分隔符。这个应该很实用!!!
定义watermark时报类型不匹配,但是已经通过TO_TIMESTAMP函数转成timestamp类型了,系统提示出来的却是localDateTime类型,求大佬解答,如下图  
` insert into dim_kafka_sink SELECT p.no, p.code, count(c.phone) tag_test_1 from bdl_kafka_source s inner join bdl_kudu_side c on c.user_id = s.user_id ` 使用1.8版本,在测试的时候,发现统计的结果是s表和c做笛卡尔积的数量,怀疑join中的on条件没有起作用。通过源码断点调试,发现下面的循环不能进去: 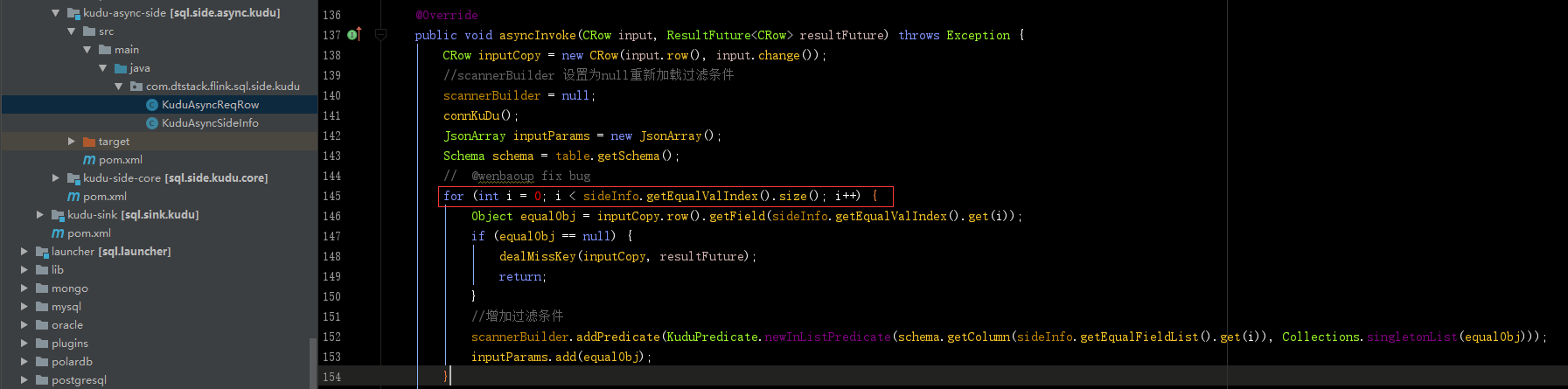 继续排查发现KuduAsyncSideInfo类的buildEqualInfo方法是空的实现, dealOneEqualCon也方法也没有被调用
现使用的guava版本为19.0,但是在hadoop3.*中版本guava的版本升级成了29.0-jre,启动yarnPre类型任务的时候会报错,将pom改为guava29.0-jre,会和现有方法冲突,望兼容下hadoop最新版本