Preventing/constraining words in the output
I asked LD for "fire" (samples=3, iter=2) and 5 of the 6 outputs had rendered some variant of the word "FIRE". Is it possible to somehow control whether text is rendered or not? Sometimes it's ideal (generating posters, books, etc.) but sometimes it ruins the render (cf "fire" above).
Or is it just a case that text from the training set is being picked up and there's nothing that can be done (other than training on non-textual sources)?
~I think this is kind of a fundamental problem with CLIP. CLIP scores images with the exact text significantly higher than images of what the text describes. Using a better calibrated model like CLOOB instead can probably help alleviate this to some extent.~
~Here's a repo that has latent diffusion conditioned on CLOOB rather than CLIP. I don't think there's been a larger 1.45B model trained yet though, so the results will probably be slightly worse.~
EDIT: got my models in a twist, no CLIP conditioning here
Another option would be to directly prompt the model to not generate text. ~There's probably some way to do conditioning arithmetic so that images with text are penalized.~
~e.g. changing the txt2img script to something like:~
c = model.get_learned_conditioning(opt.n_samples * [prompt])
c_text = model.get_learned_conditioning(opt.n_samples * ["there is text in the image"])
c -= c_text
...
~Note: I haven't tried the above code, so there might be some errors and I have no idea if this actually even works well. There are probably also better prompts than 'there is text in the image'. You'll have to experiment!~
EDIT 2: Gave it a try, conditioning arithmetic doesn't work well at all, prompt engineering (like rromb says) is the way to go!
@rjp Sure, that should be possible! Let's consider the example you posted and start with the plain prompt fire:
Running with settings --n_iter 1, --n_samples 6, --scale 5.0 , this produces the following output:
fire

We can see the behavior that you described, sometimes it renders an image of flames, sometimes it writes down the word fire.
Now, lets try to modify this via different prompts.
a photograph of a fire

a painting of a fire

a watercolor painting of a fire
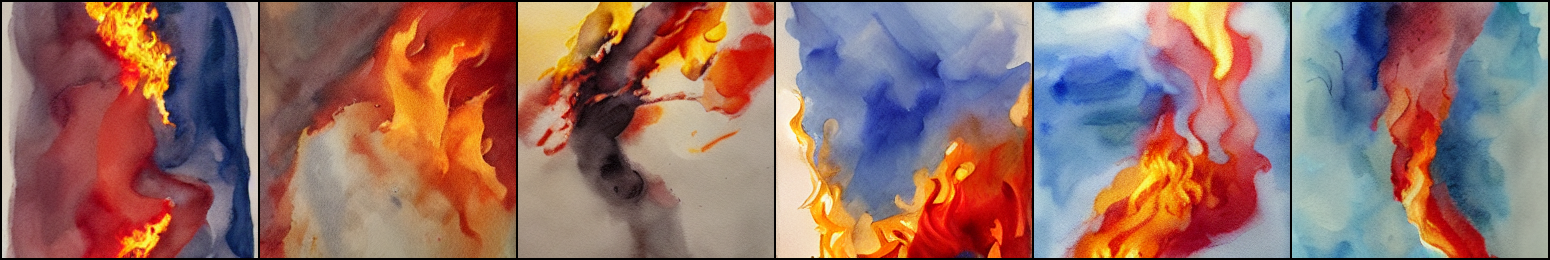
a shirt with a fire printed on it

the earth is on fire, oil on canvas

@JCBrouwer The LDM model here is not conditioned on a CLIP embedding but rather a token-sequence that was pre-processed by a BERT-like transformer (and jointly trained with the diffusion model)
RuntimeError: Given groups=1, weight of size [192, 3, 3, 3], expected input[6, 4, 32, 32] to have 3 channels, but got 4 channels instead