Questions for classifier-free guidance on ImageNet
Hi, could I ask a simple question about the classifier-free guidance on class-conditioned models?
According to the original paper, we need to jointly train the conditioned and unconditioned models with a null index and probability p_uncond
 Based on the DDIM code, I guess the null index is 1000 for ImageNet.
However, I could not find the details of p_uncond in the current code, and I am not sure how this joint training is done.
Could you please give a pointer on that? Do you also use p_uncond=0.1?
Based on the DDIM code, I guess the null index is 1000 for ImageNet.
However, I could not find the details of p_uncond in the current code, and I am not sure how this joint training is done.
Could you please give a pointer on that? Do you also use p_uncond=0.1?
Thank you so much
The null conditioning is an empty string (passed to the text tokenizer + text encoder and then into the unet in stable diffusion at least). I.e. throwing away the text for an image when training and passing in "" instead. p_uncond is 20% in stable diffusion.
The index is unrelated, it decides how much noise is added to the original image.
Thanks very much!
Although it would be nice to know where this code passed 20% p_uncond and how "" string was used, thanks for the useful information! I am interested in class-conditioned generation for now, but it should be the same for text-to-image generation.
This is a good question. I don't understand where in the stable diffusion code does it take into account the random dropping of condition (20%) and more over its not clear if classifier-free guidance was taken into account in the stable diffusion's code during training!
Any insights are much appreciated.
It seems that the logic of classifier-free guidance in conditional ImageNet is missing in this repo(at least.)
Figures 26, 27 in the appendix state: Sampled with classifier-free guidance... which is on par with the current code, i.e., the model is trained with class-context embeddings being fed through let's say a ClassEmbedder and during sampling, you can choose whether or not you will apply classifier free guidance with a corresponding scale. But this is just an assumption. However, with the given code, there is no dropout applied to the conditioning embeddings which are fed to the UNet constantly during training.
@GiannisPikoulis I held the same assumption previously. However, one question is that, if the model is not trained with unconditional mode, i.e., empty string, can it really handle the empty string? Or in another word, how to ensure the quality of the unconditional result.
Hi everyone, I've found this figure in the Stable Diffusion Repository:
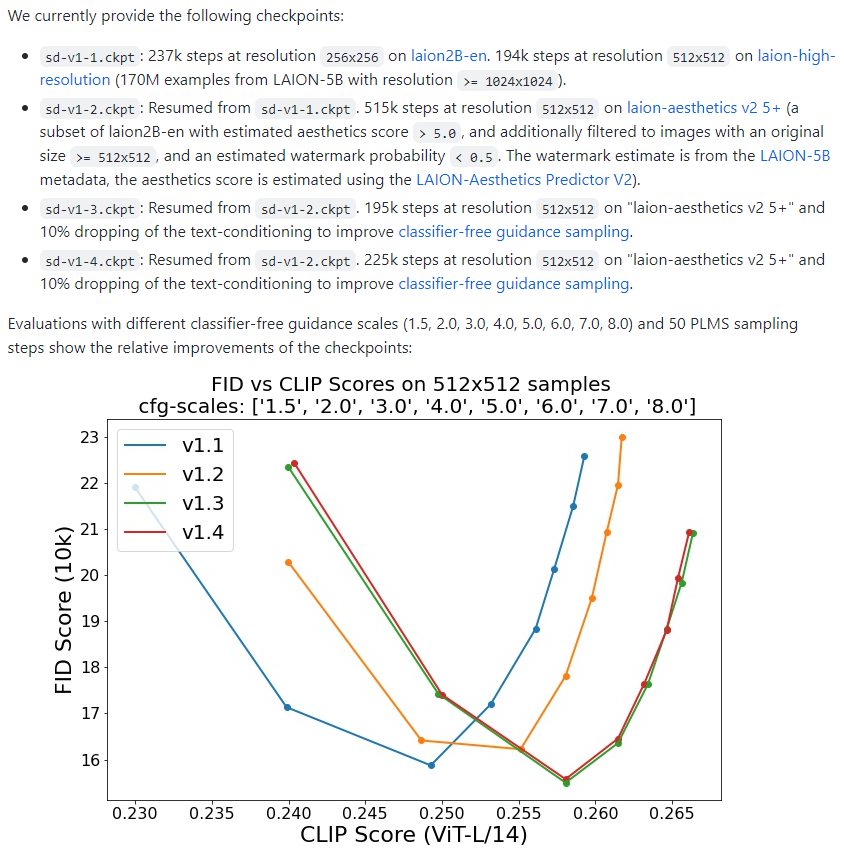
where it seems that only v1.3 and v1.4 used dropping in the training, but all the versions used the classifier-guidance sampler. Thus the assumption above seems true.
However, I still have the question why it could work even if the net is not trained with dropping.
I'm currently conducting experiments with classifier-free guidance during training for the AffectNet dataset. I'm also considering whether the null embedding needs to be trainable or not. I will come back with updates.
Hello, If I look at the inference code in scripts/latent_imagenet_diffusion.ipynb I do not understand where the class_label (i.e. the 1001th class) representing the unconditional_conditioning comes from. It is neither clear to me from the runcard in configs/latent-diffusion/cin256-v2.yaml that is loaded, nor can I see it in the ImagnetTrain class. Is this bit just missing or did I miss it in the code?
Hello, If I look at the inference code in scripts/latent_imagenet_diffusion.ipynb I do not understand where the class_label (i.e. the 1001th class) representing the unconditional_conditioning comes from. It is neither clear to me from the runcard in configs/latent-diffusion/cin256-v2.yaml that is loaded, nor can I see it in the ImagnetTrain class. Is this bit just missing or did I miss it in the code?
I also do not find any usage of the 1001th class label as conditioning during training. From my understanding, if this is the case, the embedding of 1001th class should remain at its initialization value. Could anyone explain why this is possible for inference?
Hello, I would like to ask the difference between unconditional LDM and conditional LDM. After the model is trained, is unconditional sampling generate image randomly, but not based on a given image? So, if I want to generate a normal image from a flawed image (without any annotations in the inference phase), should I use conditional LDM? @samedii @MultiPath @dongzhuoyao @koutilya-pnvr @flymin
In LDM, uc = model.get_learned_conditioning( {model.cond_stage_key: torch.tensor(n_samples_per_class * [1000]).to(device)} ) the unconditional was represented by the extra label index 1000, which was not in the class index range 0 ~ 999. So, the class embedding shoud be randomly replaced by the embedding of index 1000 when training, or you can set a learnable nn parameter.
The p_uncond is label by this argument:--proportion_empty_prompts, and --proportion_empty_prompts=0.2 in the official sdxl training script