Json loading from efficient binary representation for performance wins
Summary
Performance "Binary json input for various performance wins"
Purpose of change
Performance profiling shows that a lot of time is spent inside the json input stack simply manipulating json. A hypothesis I had for a long time is that there is potential for wins here by using an efficient 'pre-parsed' binary representation of the json. Simply making loading faster is a worthwhile goal in and of itself, but we can also unify the json input stack off the 'streaming' model and have everything consistently using the object oriented deserialize approach. Furthermore, there is potential for runtime wins by 'externing' strings sourced from json. By changing data types to hold pointers into the binary json for each string, instead of a std::string member with a possible heap allocation, we can shrink objects and save on runtime with faster string comparisons. This latter approach has not yet been explored.
Describe the solution
First, a description of the binary format being used. Google FlatBuffers are a binary hierarchical data representation that can basically be described as 'typed json', except they require a schema defined ahead of time. For slightly less efficient representation, however, there are FlexBuffers, which do not require a schema. A full description can be found at https://google.github.io/flatbuffers/flexbuffers.html. The shorthand description is that the representation is a flat binary file consisting of vectors and possibly cached/reused values. Objects are represented as two vectors: a key vector, and a value vector. Arrays are simply a single value vector. The key and value vectors store offsets into the binary to where the keys/values are actually stored. The FlexBuffer parser is configurable to share keys, string values, and key vectors across the input. So, a series of objects with the same keys will share the same key vector in the final binary. Repeated usage of the same string value will be reduced to a single string in the output.
The solution I have implemented starts by deprecating almost all usage of JsonIn in the entire project. I did first attempt to reimplement the semantics of JsonIn, except backed by the binary, but ran into a long series of issues when crossing between code using JsonIn, converting to eg. JsonObject, then back to JsonIn using get_raw(). Simply eliminating get_raw() was insufficient for resolving these issues. Ultimately I decided to remove JsonIn because it is essentially lying to the user that the performance is different over JsonObject/JsonArray. All parsing would be effectively O(1) post conversion.
The deprecation begins by eliminating usage of get_raw() throughout the codebase. The most complicated places were unit and translation parsing, and generic_factory get_next() style parsing. unit and translation parsing relied on JsonIn to seek and throw errors at specific offsets. I augmented the Json apis to allow JsonValue to throw a similar error, then templated the parser over the 'error throwing' function to allow the same logic to be used regardless of the source (JsonIn, JsonObject, or JsonValue). I also added functions for getting just a JsonValue from JsonIn and JsonArray.
The refactor continues by first implementing a deserialize() function for each type that currently uses JsonIn that instead accepts a JsonValue/Object/Array. For many types, this was trivial. These types as the first line of logic would generally call something on the order of JsonObject jo = jsin.get_object(). For clarity sake I collapsed refactoring these types into a single commit.
There were some types that were slightly more complicated, such as doing a simple iteration using start/end array or start/end object without deeper streaming behavior. I kept these conversions in separate commits despite considering these refactors 'trivial'.
Finally there were the 'hardcore' streaming parsers, such as savegame.cpp, savegame_json.cpp, and submap. These were refactored at the end, once all their dependencies already had been adapted to accept JsonValue etc.
Then there is a commit to delete all of the deserialize() functions that accept JsonIn, which breaks the build, followed by a commit which changes the logic inside of JsonIn to pass JsonValue to all deserialize users. Implicit conversions allow this to automatically get cast to JsonObject or JsonArray as needed.
At this point, we have still not done anything except slow down load times by forcing non-streaming parsing everywhere. Now we start implementing the FlexJson stack.
First, the supporting cast and crew, aka helper classes.
cata_bitset, astd::bitset-like type that supported dynamic resizing and space for 24 or 56 bits of inline storage. I use this to implement efficient used fields tracking forJsonObject. It supports setting or clearing individual bits or all of them, and queryingall(),none(),any(), and direct bit access if desired.small_literal_vector, a vector type with a template configurable amount of inline storage for storing trivial types. If too many values are pushed in, it will heap allocate and move values there. This is used for an efficient implementation of aJsonPath, which is used to throw errors using the old Json text-based stack which point into the appropriate location in source for messages.mmap_file, an abstraction for a shared handle to a file which has beenmmap'd into existence. Used to cheaply loadFlexBuffers off disk and reduce heap footprint (although mmapping does have a cost of page-at-a-time usage, it is backed by the filesystem cache so the net memory usage of the system does not rise).flexbuffer_cache, a helper which vends parsedflexbuffersof unknown provenance. The public api accepts either a path to a json source file, with an optional offset into the file (to handle some json that is prepended with a # comment), or a string buffer in memory. For json files, it consults a disk cache to see if we have previously parsed this json file into aFlexBuffer, and will mmap thatFlexBufferand return that if appropriate. We compare the mtime of the input json vs an encoded value for the mtime when we parsed the json, and if they match, we reuse. Otherwise we discard the cachedFlexBufferon disk and re-parse the json input, caching that result. For string buffers, we parse but do not cache them at this time.- And coming in at the end,
cata_unreachable(), for instructing the compiler to optimize out branches we statically proclaim cannot be reached through Logic.
Then, finally, we implement FlexJsonValue/Object/Array. The api conforms to the same api exposed from JsonValue/Object/Array, minus what we deprecated before or what otherwise does not make sense. JsonValue takes the role of JsonIn as far as the template deserialize hookups go, and otherwise all cast and conversion operations are performed by JsonValue. JsonValue itself is implemented to be as cheap to create and destroy as possible. It is allocation-free, and nearly trivial. The most expensive part is a shared_ptr member which retains the backing memory for the FlexBuffer, but even that is essentially free in a single threaded environment. JsonObject and JsonArray primarily serve as JsonValue vending types and internally convert all accesses and convenience getters (eg. JsonObject::get_foo(member) and JsonArray::get_foo(index)) to just return the appropriate JsonValue for that member or index. Everything is functionally implemented in headers for maximum inlining, as all the FlexBuffer accessor code is also contained in the headers as they are just a complicated stack of offset based lookups into the buffer. Measurement shows that most of the cost left attributed to the FlexJson stack is in JsonObject's string to index binary search, because key vectors are sorted.
Testing
-
Create, save, load, save, load games.
-
Create & use characters and character templates.
-
find . -type d -name "cache"and inspect the results to find caches in the expected folder locations when run by default. I.e.cache,data/cache, and per-world and character caches as appropriate. -
Tested the cross build by putting cdda in a folder with unicode in it, creating a world with unicode in the name, creating a character with unicode in the name, and saving & loading that character as a template with unicode in the name. No obvious issues or exceptions thrown.
-
And the generated flatbuffer cache files also are unicode-correct.
-
Output size and build time regressions are consistent with the increased number of source files added.
du -sh obj/tilesreports an increase from ~180mb to ~200mb with clang++-12 in release/tiles/sound build configuration.cataclysm-tilessize remained constant at 45mb. Build times regressed approximately 10% in instrumentation for clean builds, in a corresponding fashion to build output increase.
Additional context
On a warm cache, with a handful of extra mods enabled (eg. Aftershock, Magiclysm), load times and cpu cycle counts decrease by ~25%, from ~13.5s to ~10s in wall time on my computer. Testing was done by passing --world <world> as an argument and calling std::exit(0); immediately after loading completed, to isolate as much noise out of the equation as possible. On the left is before this PR, on the right is after.
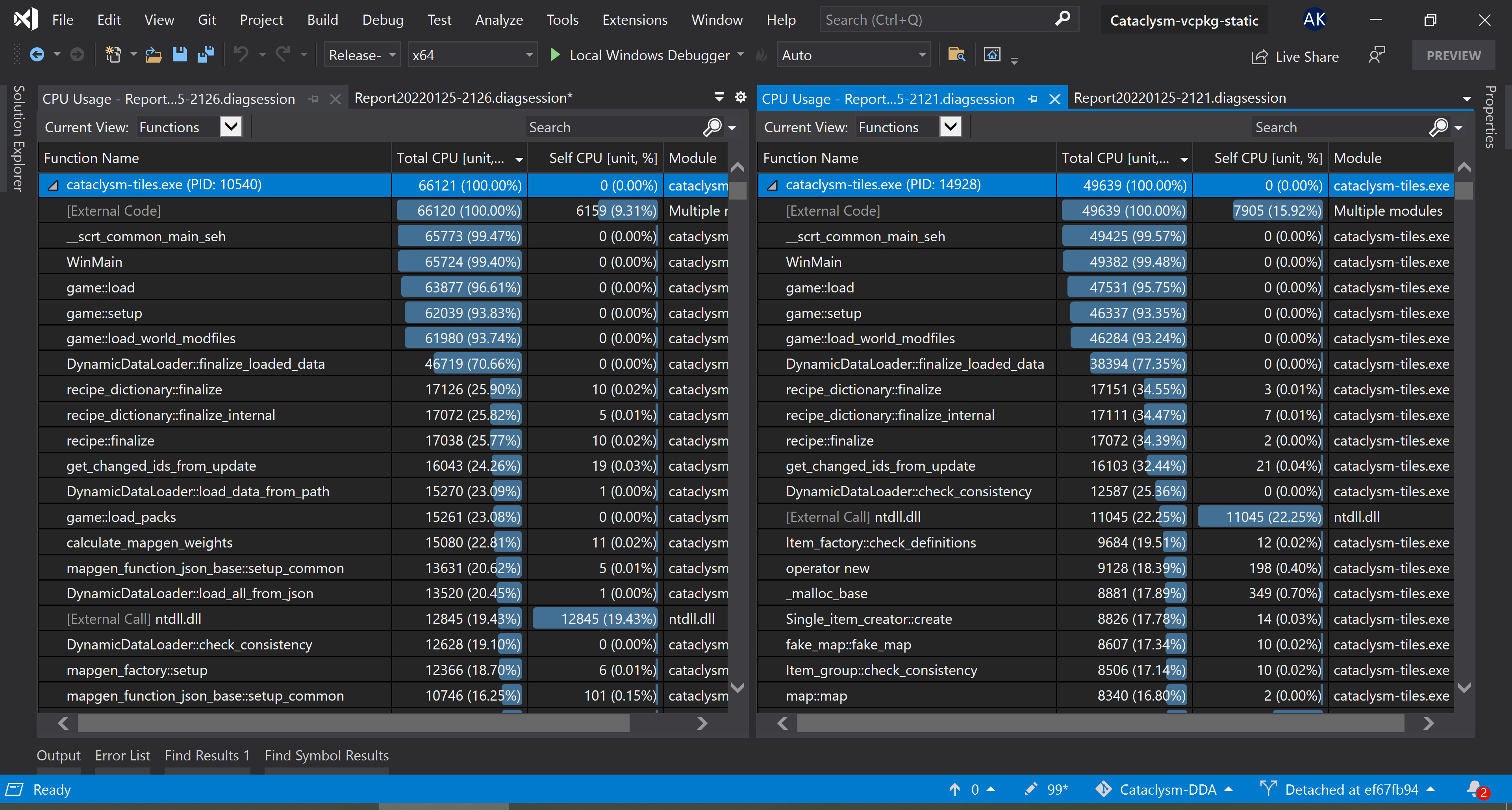
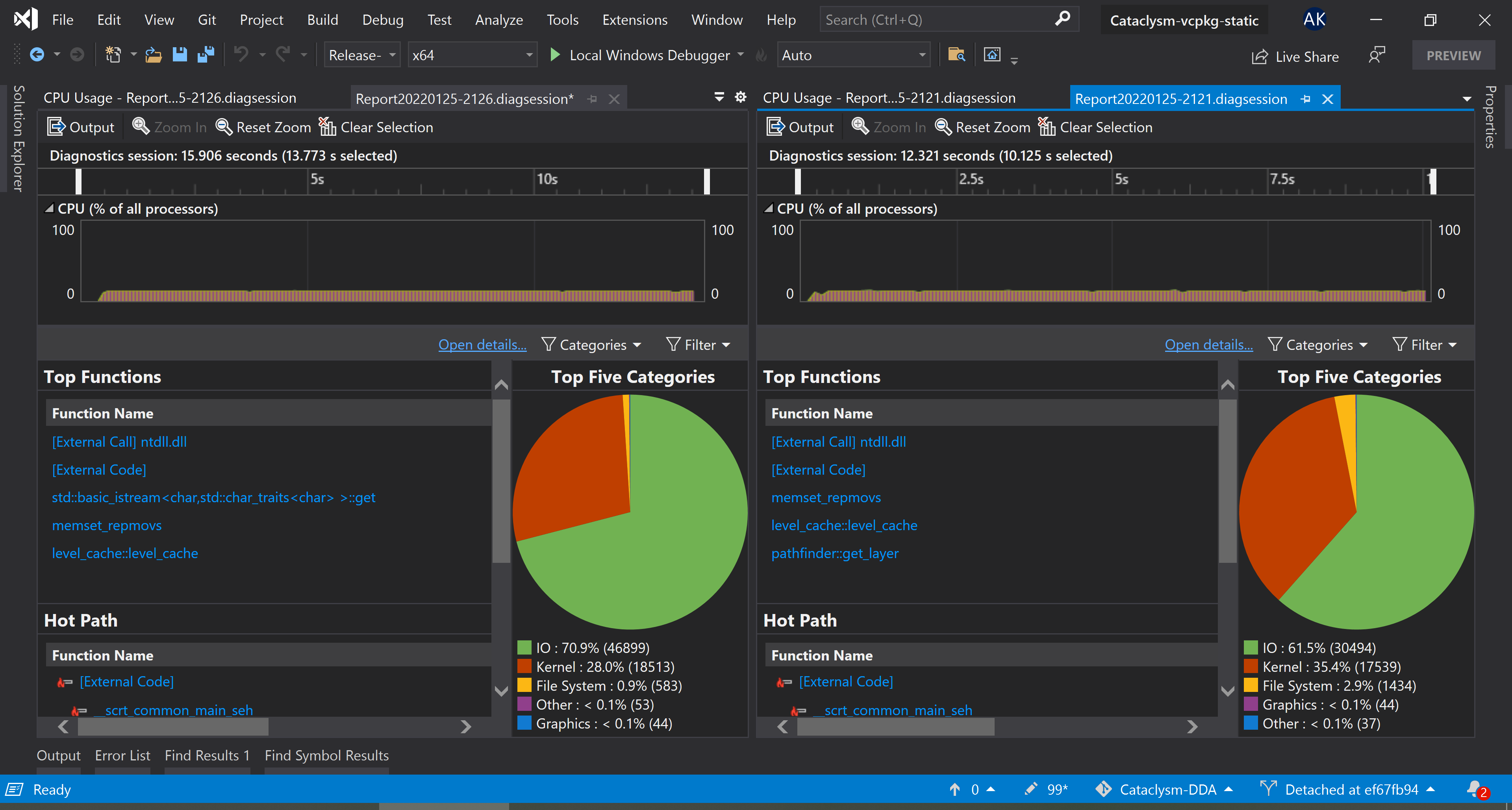
Even with a cold cache, times are improved >10%.
[Edit 7/28/2022]
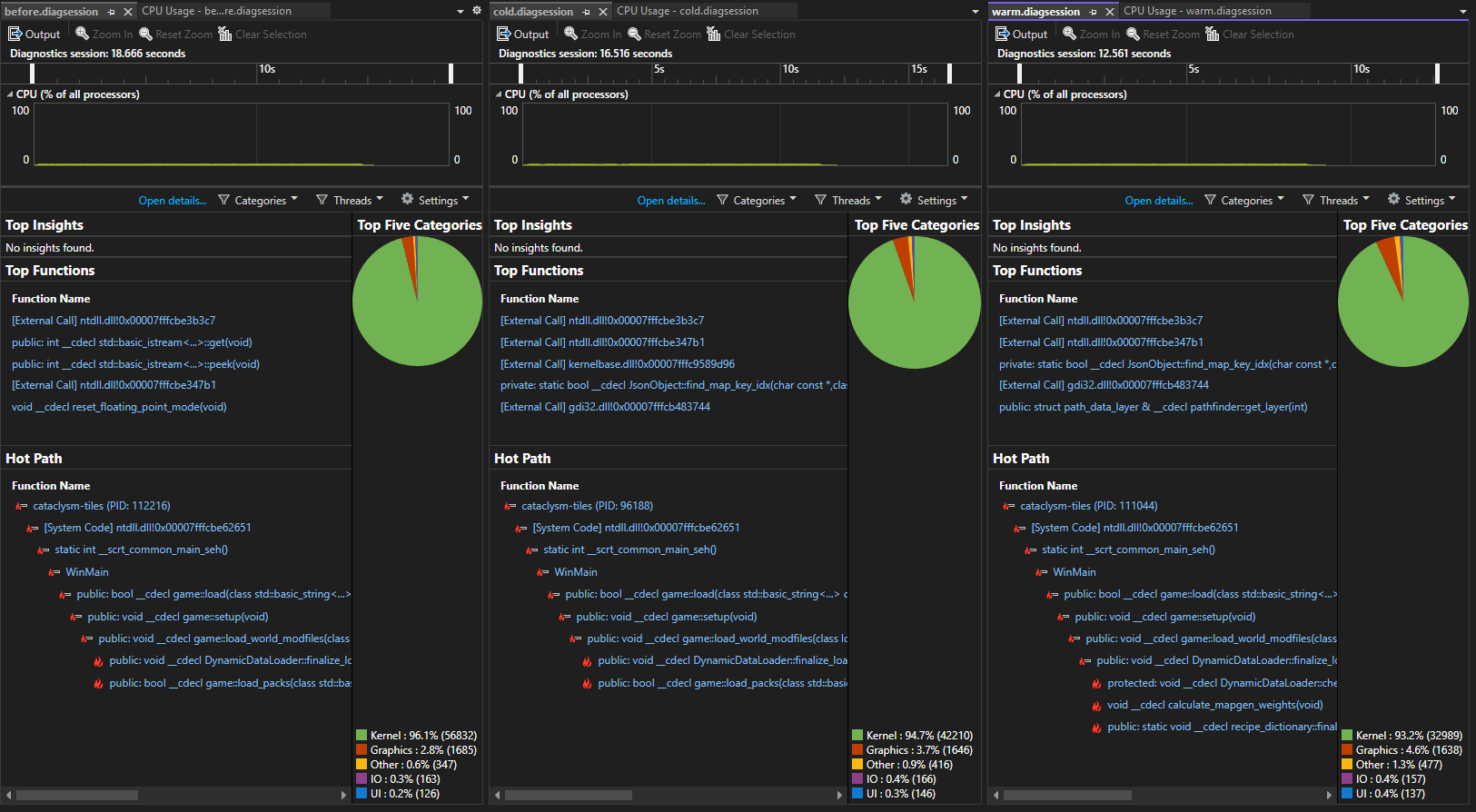
New measurements on a threadripper ryzen 3975X 32 core @ 4GHz single core boost clock on Windows 10 in Release-NoTiles x64 configuration (texture loading durations were highly variable and irrelevant to this experiment). Non-relevant patches were needed to make -NoTiles compile due to recent changes. Comparing before my stack, on a cold cache (nothing on disk), and a warm cache (all files on disk). Measurements are taken from launch with --world <worldname> as commandline argument, and std::terminate called immediately after g->load( cli.world ) in main.cpp. Duration of the trace went from 18.5s before, to 16.5s with cold cache, and 12.5s with warm cache, a 33% reduction in load time.
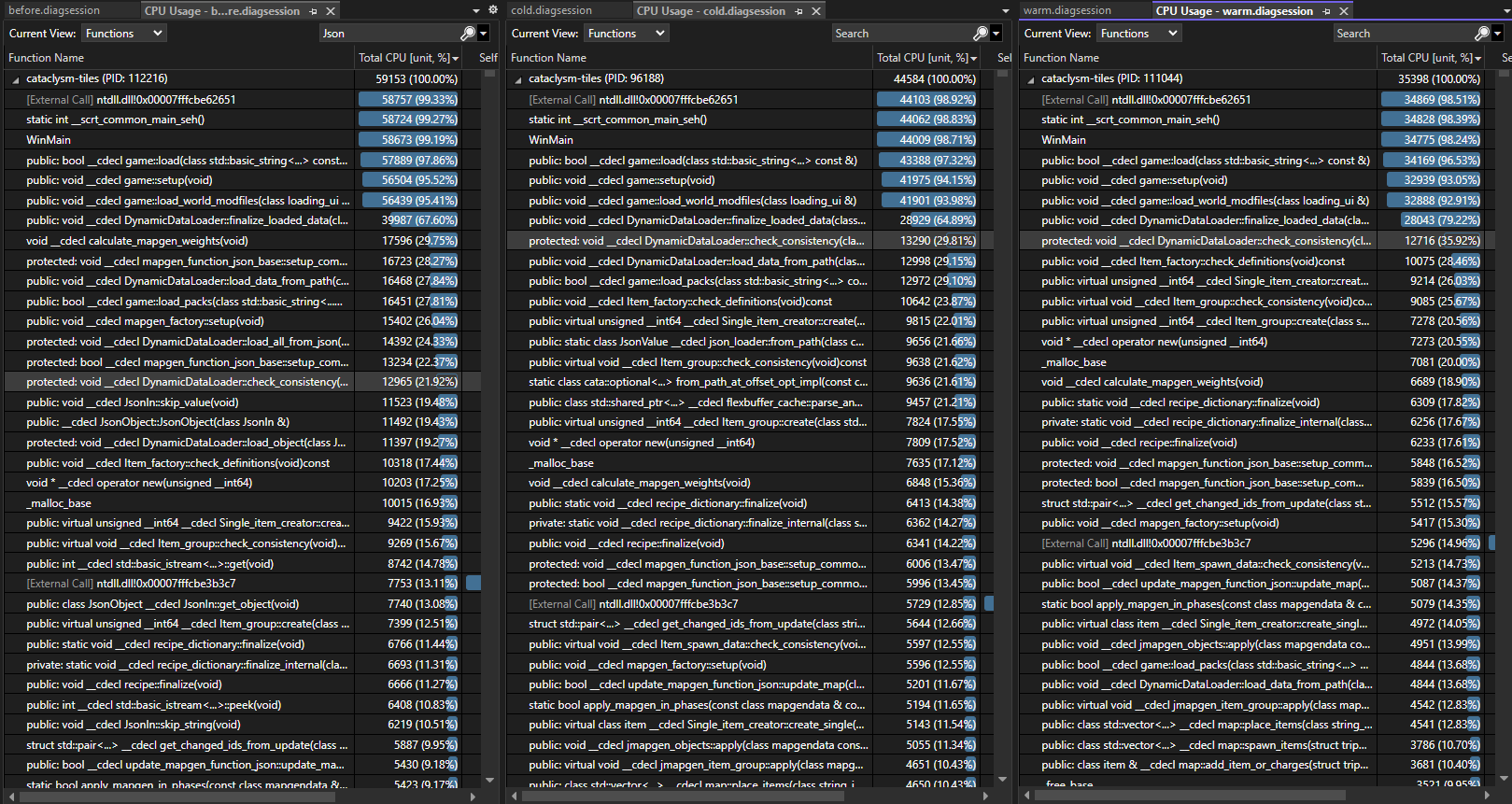
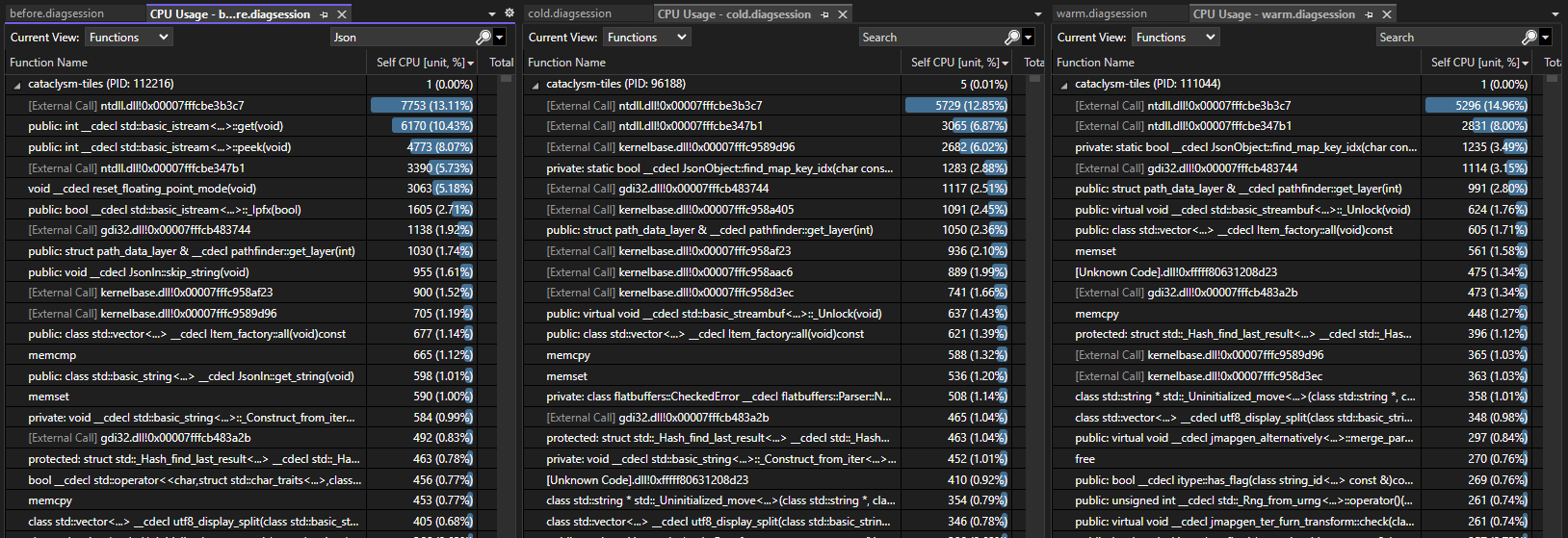
Measuring on the same machine but in WSL we see similar order of magnitude improvements, from ~10s before to ~6s with a warm flatbuffer cache.
TODO
- [x] Fix file operations to use ghc filesystem wrappers where needed.
- [x] Integrate into non-Windows builds.
- [x] Integrate FLATBUFFERS_ASSERT_INCLUDE into all build systems correctly.
- [x] Non-Windows support in
mmap_file&pragma(pack)usage. - [x] Used field tracking might not actually work correctly right now.
- [x] Test using xxhash or etc for data integrity checks on top of mtime.
- Probably overly paranoid and not worth the cpu hit.
- [x] Screenshots or other measurements of wins.
- [x] Fix tests.
- [x] Separate data caches (out of line) and savegame caches (inline with save game json).
- [x] Modify flexbuffer parser to skip comment members because they are irrelevant at runtime and just waste flexbuffer space.
- Was not actually useful, <2% savings (for 5 lines of changes, but still).
- [x] Create flexbuffers on save so they are fresh for next load.
- Not worth the overhead on save because these files are write-many read-few.
- [x] Investigate storing
JsonStringpointers into flexbuffer instead of extracting tostd::string.- That can happen later.
- [x] Style cleanup (class/variable naming,
foo const& x->const foo &x, etc) - [x] Fix Android.
- [x] Update before/after metrics with modern measurements.
- [x] Measure impact on compile times, object file sizes, and binary size.
- [x] I'm sure I'm forgetting something here.
- Am I though?
Is there any chance that you could break up this into a couple of smaller pull requests in the size of around at most thousand lines of changes for easier review?
Before un-drafting, sure. I can peel off chunks that can be landed independently. I put this up for discussion purposes now that I got it to the point of working, before the final push and cleanup before land.
Right now each commit is independently reviewable. The commits are loosely sequential (and there are some ordering constraints) but you can review each commit in isolation without missing important context. As long as you go in order at least. In fact, with few exceptions, the project will build and run correctly at each commit.
cata_scope_exit, a helper type which runs a callback when it is destructed, unless it has been dismissed. This is a kind of scope guard to allow for resource cleanup in the face of an exception.
There's on_out_of_scope in cata_utility.h.
1. I'm not sure if checking for mtime will always work. In some extreme edge cases it may fail. Maybe we should run a checksum of the json file when other indicators such as mtime, size, etc are all the same, although I'm not sure if it won't have a noticeable impact on performance.
I'm not sure what cases you are thinking about it failing. mtime is good enough for make, and we aren't trying to handle mtime changes on the order of micro or nanoseconds, just human scale changes. I can try measuring what happens if we do eg. xxhash of the input, but that seems extra paranoid.
2. If the disk runs out of space during caching or the data files are in a read-only disk/directory, does it fail gracefully?
Technically, yes, but not on purpose. We don't throw an error if writing the binary out fails. In the case where have to parse json to binary, we parse to a heap allocation, and we reuse that heap allocation to load json from. The write to disk is an incidental optional step in that path.
3. Maybe we can ship the binary json in the release to improve first-time loading speed.
Probably, but on my desktop the whole stack loads faster even without doing that.
4. IIRC, previously reading two json values concurrently was impossible because they use `JsonIn` internally, and reading from one object will change the stream position of another. Does this PR fix that?
Yes. There is no shared mutable state between different json objects.
I haven't looked at the changes but it sounds like you're caching the converted json files in the data directory. I don't think it's safe to assume that directory is writable; I assume it would be e.g. in /usr on a Linux system for a regular install of the game (though I've only ever run CDDA from my git checkout myself, so I don't really know...). Possibly we should be generating the cached versions at make install time.
Yes, currently it's in /data because it was convenient. We could distribute pre-serialized versions of these so the typical user case doesn't require a writeable fs, or just put the cache in the user dir (which is presumably writeable), but I'm curious how mods etc are handled.
Ultimately all that matters is having one persistent cache for data which is standalone and then separate per-save caches for savegame json. Where it is is less relevant except being easy to delete for debugging/reproducability.
FWIW, I recommend you separate out the initial portion of deprecating JsonIn within deserialize functions and try to get that merged first. That seems like a good change regardless of the rest, and it's the thing that's going to suffer most from merge conflicts as other development continues.
This is now largely 'feature complete'. AFAICT it builds and runs correctly on all supported platforms. The remaining large features I want to implement are:
- logic to save flexbuffers into global data, world, and per-character caches, so it can be cleaned up appropriately when data is deleted.
- generating flexbuffers on save, but I might skip this if it makes saving too slow.
The rest is style fixes, I think. Edit: and one of my last minute changes broke non-windows builds apparently. I'll try to fix that tonight.
generating flexbuffers on save, but I might skip this if it makes saving too slow.
I just want to point out that saving happens much more often than loading, so we shouldn't make saving slower in order to make loading faster.
That is indeed the issue, and a lot of those buffers will get overwritten without being loaded ever. But first I want to measure it.
With as long as this has been simmering, how the vast majority of the change is an import, and the vast majority of the rest is very mechanical, I'm ok with this going in without additional fragmentation. Is there anything left that's a blocker to merging this?
Some kind of system to detect and delete expired flexbuffers because the source doesn't exist anymore, because eg. The save or source mods got deleted. This is mainly relevant for saves because those experience the most mutation and creation/deletion. My plan right now is to just create one cache in data/ for non-save JSON and a cache in each save for everything under that save. I think that'll be good enough.
Also need to turn off used field tracking in debug because there's a loooooooooot of errors right now.
I'm going to undraft this so I can get ASAN coverage on tests and the other compilers cause I can't easily get mac access to test on.
We can revisit that now that ccache is actually getting hits, but for now, yea draft cancels the full general build to save on GHA queue time.
I've updated this PR with an extension on top of the previous code, so if you've seen everything up to "Fix chkjson" / before "Implement json_loader" then you can start at "Implement json_loader".
The likely uncontroversial change is:
- Implement
json_loader, a type which abstracts the process of getting a JsonValue away from the JsonValue class. Internally this class can choose from one of manyflexbuffer_cacheinstances to use for caching the resulting flexbuffer.
The possibly interesting change is:
- Implement
cata_path, a class that feels-like anfs::pathexcept a) is considered relative to a 'logical root', which in cataclysm speak is a concept like 'the data folder' or 'the base folder' or 'a savegame folder', and b) is always relative to that root, and never represents an absolute path or a path outside of that root (except didn't finish implementing this).
I then extend json_loader to load json via cata_path instances, and key off the logical root value in each to choose an appropriate flexbuffer_cache instance to load from. The idea is that, since each of {base, config, data, memorial, save, user} are individually remappable to arbitrary locations on the filesystem, it makes sense that each should theoretically have its own cache folder. This avoids polluting one folder with potentially stale flexbuffer caches from arbitrary locations and unbounded growth of the cache folder therein (without some kind of pruning heuristic like 'cleanup unreferenced flexbuffers on quit', but that itself could be noisy/lossy if someone just starts and quits the game immediately).
I expect the only real place where unbounded growth would practically happen would be savegames and the per-character json like map memory. The solution is to put a cache in each world for global state and a cache per character for per character state. This feels the cleanest to me, although I could be convinced to not worry about it and just have a cache per world.
I've gone down this path far enough to load a few files and verify the path operations seem to be doing the right thing as far as picking the right logical roots and constructing/relativizing the paths correctly. I didn't want to keep this local forever while chewing through the rest so I've put up what there is, but currently the game won't build & run past "Fix chkjson" (it'll build and run and throw an exception as soon as a json file gets loaded from an 'unknown root'). I'd appreciate feedback on whether the cata_path approach seems like a reasonable one and to move forward more fully there.
This is now actually feature complete, but the commits for all the cata_path conversion are not in the best shape and there's more code cleanup to do.
There is a test error persisting across multiple retries:
ERROR : src/iuse_actor.cpp:751 [virtual cata::optional<int> unfold_vehicle_iuse::use(Character &, item &, bool, const tripoint &) const] Error restoring vehicle: ::error file=<unknown source file>,line=EOF::error: input file is empty
Thanks for finding that, I was having trouble parsing the logs because the expected errors are getting the red text and that one was hidden in all the grey.
Ok, except for that last commit of 'buncha clang tidy fixes' which I'll merge down into the appropriate places, this is ready.
whew
Android is fixed. UBSan test passed (found one error this morning). clang-tidy is green. I'm going to go ahead and start updating the measurements graphics but I think... it might be Done? Like Done-Done?
Error: src/mmap_file.cpp:10:10: fatal error: Windows.h: No such file or directory
You have got to be kidding me, cross compiler. [edit: looks like the fix is just rename to windows.h lowercase, which although it doesn't match the official casing, it doesn't matter on Windows native].
Just as well. Hit a crash in some conversation deserialization code loading a new world with a new character and I haven't 100% excluded my changes yet.
Something I need to wait for the MXE build to finish to test is whether the path concatenation I'm doing is safe or if I need to add indirection to wrap string inputs in fs::u8path before performing the concatentation. I plan to test with cata installed in a directory with unicode in it, with character and world names with unicode in them, and try to create/load a character template with unicode in it. I don't think so because iirc that was only an issue when passing an fs::path directly to std::basic_stream types, which is why we have cata::if/ofstream now, but just want to make extra sure.
-
Fixed the cross build linker error.
-
Tested the cross build by putting cdda in a folder with unicode in it, creating a world with unicode in the name, creating a character with unicode in the name, and saving & loading that character as a template with unicode in the name. No obvious issues or exceptions thrown.
-
And the generated flatbuffer cache files also are unicode-correct.
Well something is murdering the tests now, and I'm not sure why, but time to figure that out.