Claes Fransson
![]()
![]()
![]()
Claes Fransson
Interesting, in my experiment I have never seen the GP kernel values right at resume, since the tuner only logs them after it has done fitting with new data points....
Thanks, now the y-scales at resume are much shorter than with Bask 0.10.2, maybe these shorter scales are actually more accurate? Iteration 1271, at resume: 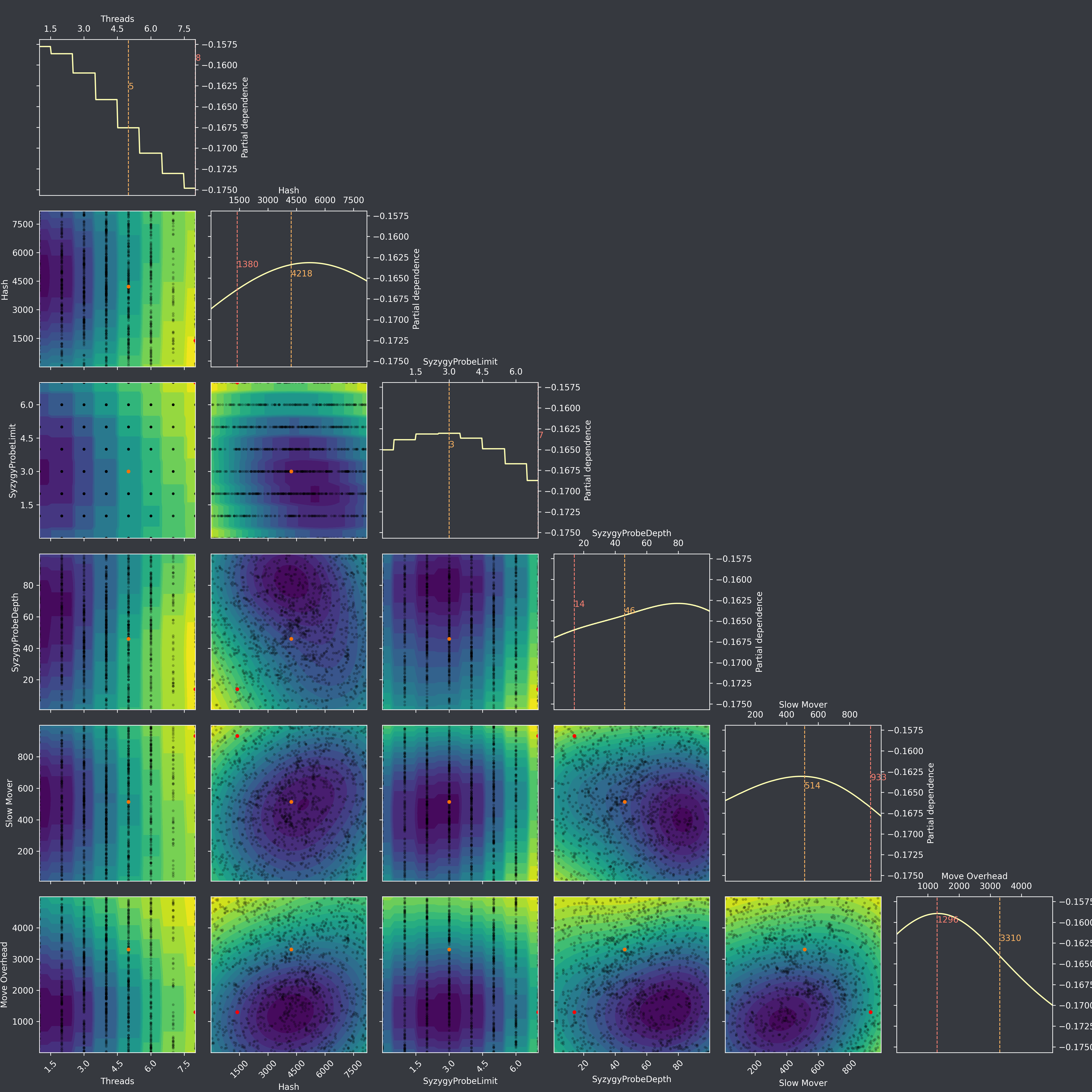 Next iteration, 1272, looking...
I did some more iterations, and unfortunately the issue of flattening landscape/decreasing y-scales are still there: Iteration 1275, after 3 continuous iterations: 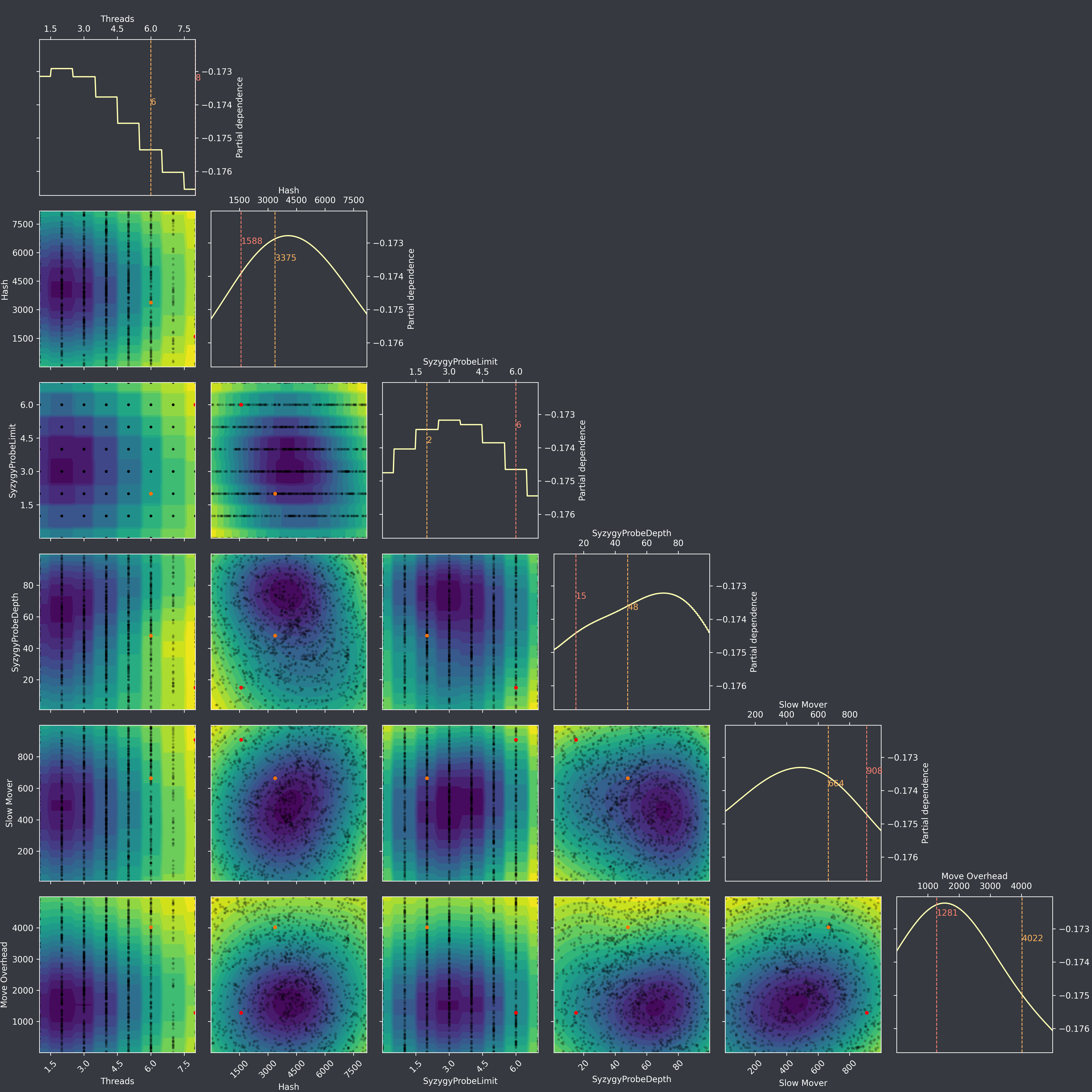 Then, after resume at iteration 1276: 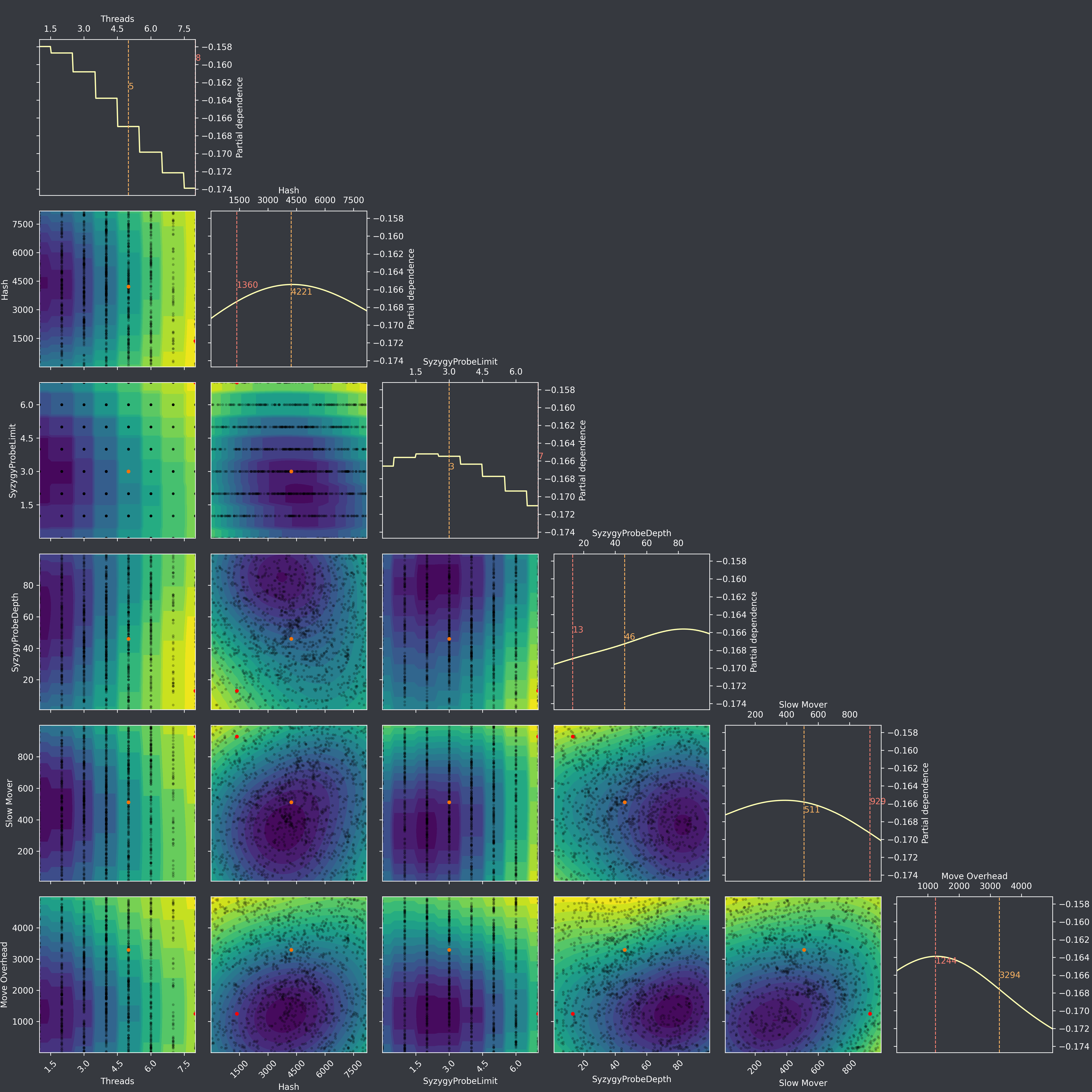...
I have not run any continuous iterations with normalize_y=False since December 30 to December 31, iterations 884 to 913. But yes, on those iterations I see the same behavior. Iteration...
Here are iterations with normalize_y=False, gp-initial-burnin=gp-burnin=25, Bask=0.10.3. The y-scales are now much larger when resuming compared to normalize_y=True. Then they slowly get shorter each iteration though. Iteration 1276 (resume): 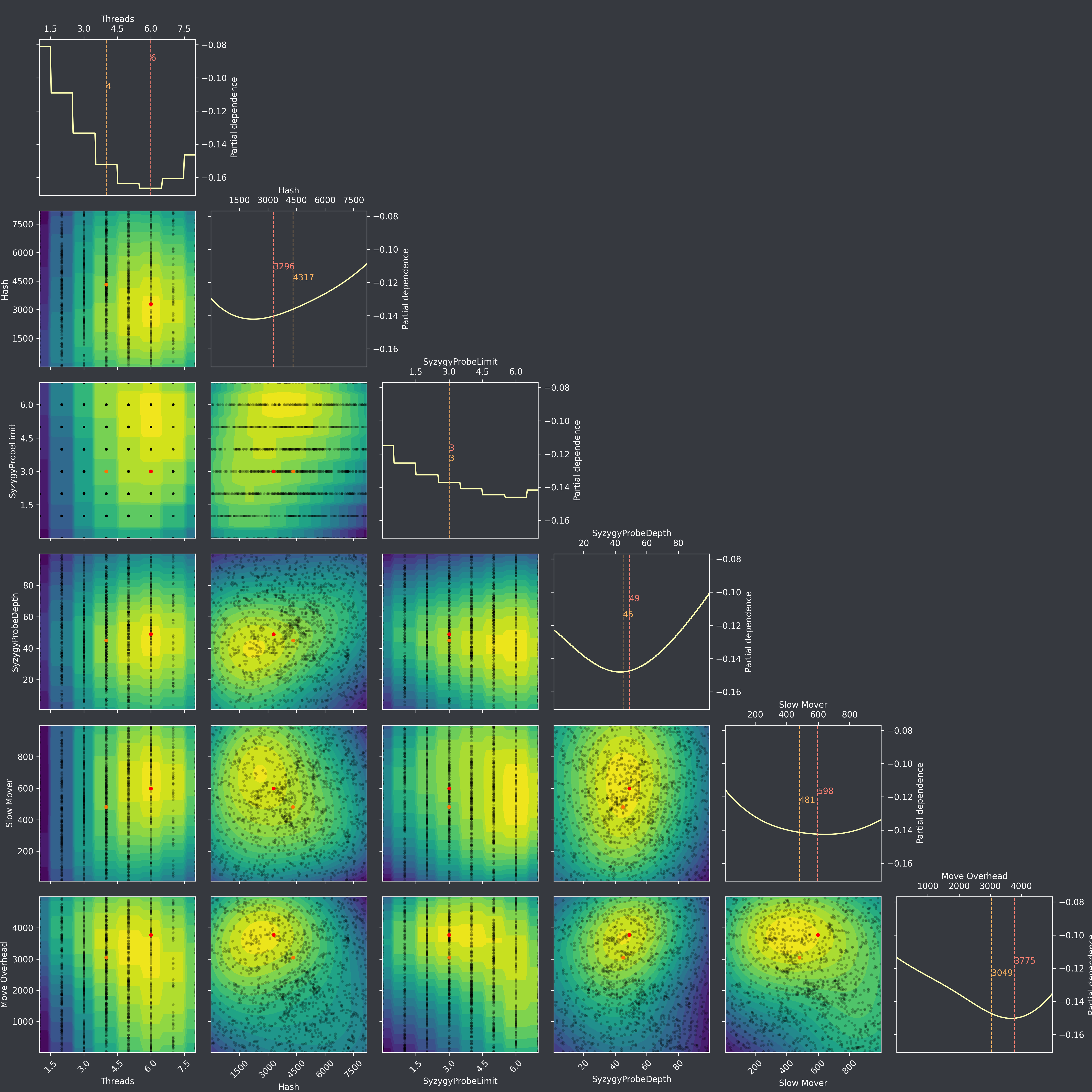...
I made an experiment: I set the noise_vector to 0 in the main optimization loop like this: ``` opt.tell( point, score, #noise_vector=error_variance, noise_vector=0, n_samples=n_samples, gp_samples=gp_samples, gp_burnin=gp_burnin, ) ``` And in...
Thanks, I look forward to try your fixes with new tunes. :)
Thanks, in the meantime I might try some new tunes with the noise set to zero as above. But with the noise set to zero during all iterations this time,...
I made some more iterations on the same tune, but this time disabled input warping. Also updated Bask to 0.10.5 and added your latest changes from version 0.7.2 of Chess...
Have been stepping through the code with Pdb to try to follow (and understand) the program execution. It then seemed to me like the "fit" function in bayesgpr.py is called...