Blog
 Blog copied to clipboard
Blog copied to clipboard
網站架構介紹
作者利用自家的
Storyblocks網站內部系統, 說明各自獨立角色的用途, 與角色間的關係. 這讓我回想, 早期過去的我很排斥, 要理解與自家網站內部相關的所有大小事, 但因為維護必須得知曉, 後來才發現這種經歷可遇不可求.[name=Chaol Liu][time=20180815] derived from...
Web Architecture 101 – VideoBlocks Product & Engineering
engineering.videoblocks.com
[name=Jonathan Fulton] [time=Tue, 07 Nov 2017 22:13:22 GMT]
以下介紹一些基本架構, 也是一些很希望當初我剛成為網頁設計師時就能知道的概念
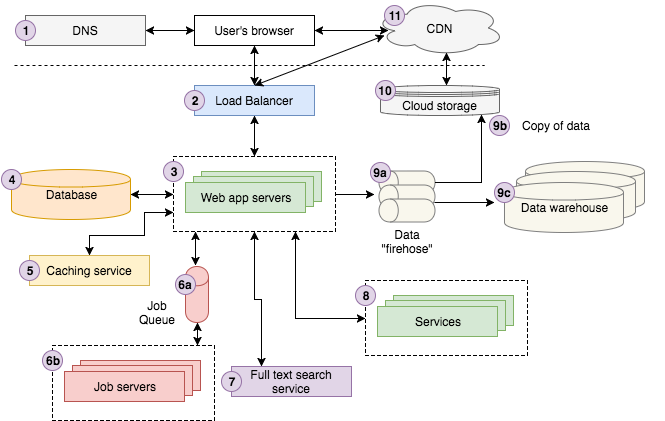 現代化網站應用架構總覽
現代化網站應用架構總覽
- 上圖能很清楚展示我們家
Storyblocks(一家提供素材的平台, 包括影音圖等)的架構. 如果你不是很有經驗的網站設計師, 很可能會覺得複雜. 底下開始會以更親切的方式說明每個部分.
假如有位用戶在 Google 上搜尋 "Strong Beautiful Fog And Sunbeams In The Forest(瀰漫著濃霧, 光線穿透的森林)", 想要搜尋相關的圖片. 搜尋完成後, 第一個就是 Storyblocks 的結果, 是一個提供
stock photo(庫存照片)和vectors(向量圖)的網站. 用戶點擊了 Storyblocks 的結果, 等同於重新導向瀏覽器, 從 google.com 到圖片所在的 detail page. 而底部運作機制其實是, 用戶的瀏覽器會發出一個請求給1.DNS(Domain Name Server), 要找到與 Storyblocks 溝通的方法, 然後才發出一個請求給 Storyblocks.
請求發出後, 會先到達
2.負載平衡(load balancer), 它會隨機從10 個或更多的3.網站伺服器(web app servers), 注意這些網站伺服器是同時運作的, 取其中一個網站伺服器處理這次的請求. 網站伺服器會從5.快取服務(cache service)找與圖片相關的資訊, 然後從4.資料庫(database)取得相關的資料. 結果, 我們發現此圖片的色彩特性(color profile)還沒處理完, 於是發送一個工作到6a.工作佇列(job queue), 它會由許多的工作伺服器(6b.job servers)非同步處理, 並把結果更新至資料庫.
下一步, 我們嘗試要找相似圖片, 發送請求到
7.全文檢索服務(full text search service)以這張圖片的標題搜尋. 用戶通常情況是會先登入 Storyblocks, 所以此時是一個 Storyblocks 的用戶, 我們就會從8.帳戶服務(account service)找出帳戶資訊. 最後, 我們發出一個頁面瀏覽事件(page view event)至9a.資料串流帶(data firehose), 記錄在10.雲端儲存系統(cloud storage system). 然後最終載入至9c.資料倉儲(data warehouse), 這是用來幫助分析師回答一些專業問題(藉由用戶的操作, 做其他大數據應用).
伺服器現在即可開始呈現 html 的畫面, 完成後送回到用戶的瀏覽器, 傳送時會先經過 load balancer. 網頁裡包含載入到雲端儲存系統中的 Javascript 和 CSS, 是連接著
11.CDN(content delivery/distribution network), 所以會用戶瀏覽器從 CDN 上取得. 最後, 瀏覽器就清楚呈現網頁給用戶了.
- 下一步, 我要帶領你們理解每個部分, 理解整個網站架構的模型.
1. DNS
- DNS 全名為
Domain Name Server, 它是讓網際網路成真的主要技術. 最基礎等級的 DNS 提供一個 key/value 配對組合, 由domain 名稱(如, google.com)/IP 位址(如, 85.129.83.120)所組成, 讓你的電腦發送請求到別台伺服器. 如果以手機號碼比喻, 不同的地方就是, 你需要一本電話簿找別人的電話, 但你需要透過 DNS 找別人的 IP 位址.
2. 負載平衡(Load Balancer)
- 在開始之前, 我們要討論一下
horizontal & vertical application scaling(水平與垂直的應用擴增化).水平擴增是指你擴增更多機器到你的資源池裡, 而垂直擴增是指你擴增更強的資源(CPU, RAM)到現有的機器上. - 在網站開發中, 你都會想
水平擴增, 因為能保持單純. 當你有不只一台伺服器, 機器發生狀況時, 能有更多種處理方式. 換句話說, 你的網站就是因為 load balancer 而有了容錯能力. 第二,水平擴增讓你能把後端拆分至最小化(網站伺服器, 資料庫, 某服務等), 讓它們散佈在不同機器上執行. 你如果要垂直擴增, 那終究有極限. - 回到 load balancer. 它讓網站的
水平擴增化為可能. 將進來的請求發送到其中一台伺服器, 然後從這一台伺服器回覆發送回用戶端. 不管是哪一台, 處理請求的方式都會一致, 這樣就只需關心哪些網站伺服器 overload 了, 哪些還未 overload, 就可以平衡負擔.
3. 網站伺服器(Web Application Servers)
- 網站伺服器相對較簡單描述. 它們執行核心的商業邏輯, 處理用戶的請求並送回 html 到用戶的瀏覽器. 要能完成工作, 基本上就是與後端各種角色溝通, 像是
資料庫(database),快取層(caching layer),工作佇列(job queues),搜尋服務(search services), 其它微服務(microservices),資料/記錄佇列(data/logging queues)等. 上面也有提到過, 至少會有兩台的網路伺服器, 通常會更多, 掛在 load balancer 後, 處理用戶請求.
4. 資料庫伺服器(Database Servers)
- 每個現代網站都有一到多個資料庫儲存資訊. 資料庫會定義資料結構, 加新資料, 查詢, 更新或刪除現有資料等的方法.
5. 快取服務(Caching Service)
- 快取服務提供簡單的 key/value 資料儲存, 讓資訊的存和查能接近 O(1) 時間複雜度. 通常會應用在運算成本高的結果, 下一次需要時就不用再重新運算. 也可應用在資料庫查詢, 呼叫外部服務等. 底下列了一些真實範例:
- Google 對很常見的搜尋查詢, 像是 "dog" 或 "Taylor Swift" 會 cache 搜尋結果, 並不是每次都重新運算.
- Facebook 會在你登入時 cache 很多資料, 像是貼文, 朋友等資訊.
- Storyblocks 會 cache React 產出的 html, 搜尋結果, 預輸入的結果等.
6. 工作佇列和工作伺服器(Job Queue & Servers)
- 大部分網站都需要有角色在背後非同步工作. 例如, Google 需要
爬(crawl)整個網路的網站再建立索引, 這樣才能呈現搜尋結果. 但並不是每次檢索都做一次. 會以非同步執行, 再更新搜尋索引. - 有很多不同的架構能夠完成非同步工作, 最普遍的就是這裡提到的
工作佇列(job queue)架構. 它由兩個角色組成: 工作佇列, 包含很多需要被完成的工作, 和工作伺服器(通常稱作工人(workers)), 要完成佇列上的工作. - 工作佇列上會儲存一串需要非同步完成的工作. 最簡單的儲存方式是
先進先出(first-in-first-out, FIFO). 無論網站需要哪個工作完成, 不管是依照正常流程的順序, 或是由用戶操作行為的順序, 就是單純加一個工作進佇列. - 工作伺服器處理工作. 會從佇列取出工作, 先確認這個工作還需不需要做, 如果要才開始.
7. 全文檢索(Full-text Search Service)
- 許多但並非大部分的網站都支援搜尋功能, 其中一個用戶輸入文字(通常稱作
查詢(query)) 搜尋, 然後網站會呈現相關的結果. 這項技術是透過全文檢索(full-text search)實現. 每篇文章標題中的每個字詞, 在排除掉停用詞(stop words)後, 分群並轉換成另一張表的主鍵欄位, 而另一個欄位則是記錄這個詞出現在哪些文章標題中. 範例說明了如何將3個文章標題轉換成
範例說明了如何將3個文章標題轉換成 反向索引(inverted index)
8. 服務(Services)
- 一旦網站到達一定規模, 很可能就會出現不同服務, 它們會根據各種目標而建立. 並不會對外, 但網站能與它們互動.
9. 資料(Data)
- 今日, 公司的存活都是取決於他們如何有效利用資料. 今天, 大部分網站, 一旦到達一定規模, 就會善用
資料流程(data pipeline)確保資料能收集, 能儲存且能分析. 典型的流程包含三大階段:- 網站送出資料, 基本上都是用戶的操作行為, 會送到
資料串流帶(data firehose), 它能提供一個串流介面, 擷取並處理資料. 通常原始資料會被轉換或加工, 然後傳到其他串流帶上. - 原始資料和最後的資料(轉換或加工過的資料)會存到雲端儲存區.
- 最後的資料通常會載入到
資料倉儲(data warehouse)分析用途.
- 網站送出資料, 基本上都是用戶的操作行為, 會送到
10. 雲端儲存(Cloud storage)
- AWS 提過 "雲端儲存是一個簡單又可規模化的方式, 透過網路就能儲存, 存取和分享資料". 你可以用它來儲存與存取, 任何那些原本儲存在本地檔案系統的東西, 就能在 http 上透過 RESTful API 互動.
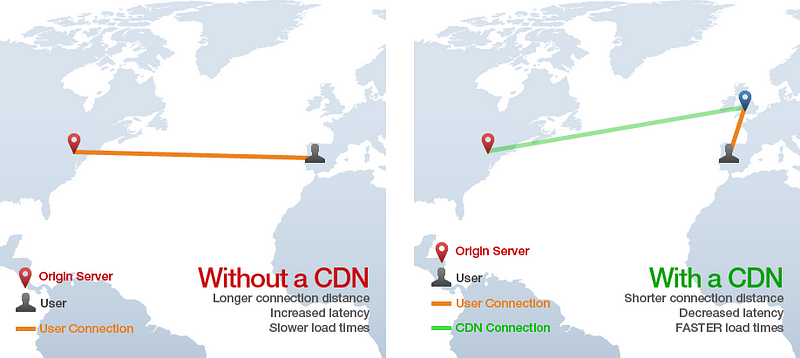
11. CDN
- CDN 全名為
Content Delivery Network. 這項技術讓你能將靜態的 html, css, javascript 和圖片放到別的網站, 下載速度會比放在原本的伺服器更快. 它的機制是將內容檔案散佈在全世界, 橫跨許多邊緣伺服器(edge servers), 用戶其實是在邊緣伺服器下載, 而不是在原伺服器下載. 舉例, 一位西班牙的用戶連到架設在紐約市的網站, 但是網頁上的靜態檔案卻是從英國的 CDN 邊緣伺服器下載, 這樣做就可避免許多橫跨大西洋的 http 請求.