blog-frontend
 blog-frontend copied to clipboard
blog-frontend copied to clipboard
Remote Procedure Call
?
初步理解, 记录一把
1. 什么是RPC?
RPC (Remote Procedure Call) 远程过程调用
-
过程: 泛指函数或方法
-
远程: 代表方法不在当前进程里
RPC是一种进程间通信方式, 它允许程序调用另一个进程上 (通常是共享网络的另一台机器上) 的过程或函数, 而不用程序员显示编码这个远程调用的细节, 即无论调用本地的还是远程的函数, 本质上编写的调用代码基本相同
因此, RPC用来解决三件事情:
-
进程间通讯
-
提供和本地方法调用一样的调用机制
-
屏蔽程序员对远程调用的细节实现
RPC和Restful并不是一个维度的概念, RPC涉及的维度更广
2. RPC调用流程
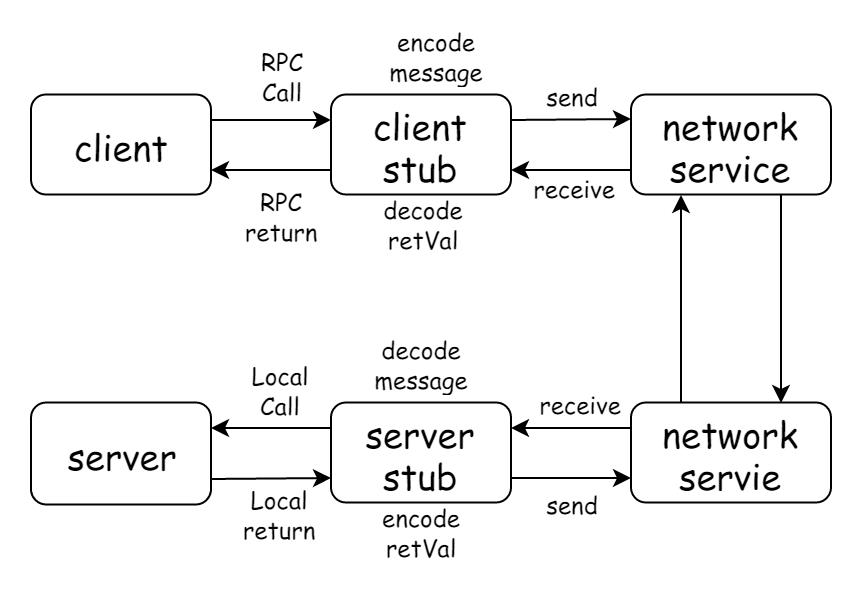
涉及名词:
-
Client: 调用方 -
Server: 服务端 -
Proxy: 本地RPC代理 -
RPC Protocal -
RPC Request -
RPC Response
过程如下
-
Client通过Proxy调用相应接口 -
Proxy将调用相关信息转换成一个RPC Request, 交给RPC框架 -
RPC框架采用
RPC Protocol将RPC Request对象序列化成二进制形式, 然后通过TCP通道传递给Server -
Server收到二进制数据后, 将它反序列化为RPC Request对象 -
Server根据RPC Request对象中的信息找到本地对应的方法, 执行, 得到结果, 封装成RPC Response, 交给RPC框架 -
RPC框架采用
RPC Protocol将RPC Response对象序列化成二进制形式, 然后通过TCP通道传递给Client -
Client收到二进制数据后, 将它反序列化成RPC Response对象, 并将结果通过Proxy返回给业务代码
3. 通讯层协议设计
因为在 TCP 通道里传输的数据只能是二进制形式的,所以我们必须将数据结构或对象转换成二进制串传递给对方,这个过程就叫「序列化」。而相反,我们收到对方的二进制串后把它转换成数据结构或对象的过程叫「反序列化」。而序列化和反序列化的规则就叫「协议」。
RPC协议可以分为两类:
-
通讯层协议: 业务无关, 职责是将业务数据打包后, 安全, 完整的传输给接收方, 例如:
HSF,Dubbo,gRPC -
应用层协议: 业务相关, 职责是约定业务数据和二进制串的转换规则, 例如:
Hessian,Protobuf,JSON
3.1 简单设计RPC通讯协议
通常它由一个Header和一个Payload组成, 合起来叫一个包packet,
之所有要有包,是因为二进制只完成 Stream 的传输,并不知道一次数据请求和响应的起始和结束,我们需要预先定义好包结构才能做解析。
这个地方和Webosocket中数据帧的概念类似, 通常来说: Header的长度是固定的, Payload的长度是变化的, 其长度记录下Header中
参考文章的Header设计方式如下, 这个随意就好
-
type: 1个字节, 标记包的类型 -
requestId: 4个字节,Int32, 生成一个唯一的Id, 将请求和响应关联 -
codec: 1个字节, 标记应用层协议的类型 -
bodyLength: 4个字节,Int32, 记录Payload长度
0 1 2 3 4 5 6 7 8 9 10
+------+------+------+------+------+------+------+------+------+------+
| type | requestId | codec| bodyLength |
+------+---------------------------+------+---------------------------+
| ... payload |
| ... |
+---------------------------------------------------------------------+
4. Node.js部分实现
分解一下需要实现的东西:
-
编码
-
解码
-
协议包的切分
4.1 编码
也就是将RPC Request对象序列化成二进制形式, 面条代码如下
// 要调用服务的相关信息
const payload = {
service: 'com.calabash.nodejs.Test:1.0',
methodName: 'plus',
args: [1, 2],
}
// Payload的二进制数据
const body = Buffer.from(JSON.stringify(payload))
// Header的二进制数据
const header = Buffer.alloc(10)
// 用0代表请求
header[0] = 0
// 写入四字节的requestId
header.writeInt32BE(1000, 1)
// 用1代表JSON序列化
header[5] = 1
// 写入四个字节的payloadLength
header.writeInt32BE(body.length, 6)
// 组装成一个packet
const packet = Buffer.concat([header, body], 10 + body.length)
还是非常直观
4.2 解码
const type = buf[0] // => 0 (request)
const requestId = buf.readInt32BE(1) // => 1000
const codec = buf[5] => 1
const bodyLength = buf.readInt32BE(6)
const body = buf.slice(10, 10 + bodyLength)
const payload = JSON.parse(body)
TCP/IP 协议 RFC1700 里规定使用「大端」字节序作为网络字节序,所以,我们在开发网络通讯协议的时候操作 Buffer 都应该用大端序的 API,也就是 BE 结尾的。
4.3 协议包的切分
网络数据并不是按照我们定义的协议包为单位传输的, 有可能一次收到多个包, 或者一个包分多次收到, 那么收到数据后第一件事情应该是将它切分成一个一个完整的包
比较传统的做法是基于data事件版本,
const net = require('net')
const socket = net.connect(12200, '127.0.0.1')
const HEADER_LENGTH = 10
// 存储所有二进制数据
let buf
socket.on('data', data => {
// 来数据就收!
if (!buf) buf = data
else buf = Buffer.concat([buf, data])
// 判断一下是否大于HEADER_LENGTH
while (buf.length > HEADER_LEN) {
const packetLength = HEADER_LEN + buf.readInt32BE(6)
if (buf.length > packetLength) {
// 切分出一个完整的packet
const packet = buf.slice(0, packetLength)
// 处理packet逻辑
...
buf = buf.slice(packetLength)
} else {
break
}
}
})
可以看到: data事件是一种被动消费的方式,就是说一旦有数据传输过来就会吐给监听函数,监听函数必须马上处理或者把数据缓存下来,不然数据就丢失了
后文还有基于readable和基于流的版本, 不过不是本文的中心, 再写就偏了, 本文主要了解一下基本概念