blog-frontend
 blog-frontend copied to clipboard
blog-frontend copied to clipboard
Protocol Buffers编码原理
Protobuf简介
将其理解为更快,更简单、更小的JSON或者XML,区别在于Protocol Buffers是二进制格式,而JSON和XML是文本格式
优点:
- 写法上简洁
- 传输体积小
- 解析速度快
缺点:
- 社区规模较小
- 语言支持不全面(暂时)
- 不直观
1. 体积对比
对比JSON和Protobuf,定义protobuf结构为
syntax = "proto3";
package TestPackage;
message TestStruct {
string name = 1;
int32 id = 2;
string email = 3;
}
JSON, 61字节, 不包含中文直接取得长度即可
{
"id": 1234,
"name": "calabash",
"email": "[email protected]"
}
Protobuf,36字节,具体含义将在后文介绍
0A
08 63 61 6C 61 62 61 73 68
10
D2 09
1A
15 63 61 6C 61 62 61 73 68 40 63 61 6C 61 62 61 73 68 2E 63 6F 6D
附加:gRPC使用不多,没有找到Postman那样的可视化调试工具,命令行工具grpcurl只能获得text或者json格式的结果,没办法获得二进制格式响应体。于是用了一个蠢办法拿到二进制的结果,如果想动手实践,可以参考一下,并不重要
const Koa = require('koa')
const protobuf = require('protobufjs')
const app = new Koa()
function payloadToProtoBuf(targetFile, targetStruct, payload) {
return new Promise((resolve, reject) => {
protobuf.load(targetFile, (e, root) => {
if (e) reject(e)
const struct = root.lookupType(targetStruct)
const errMsg = struct.verify(payload)
if (errMsg) reject(errMsg)
resolve(struct.encode(struct.create(payload)).finish())
})
})
}
app.use(async ctx => {
if (ctx.request.method === 'GET') {
const buf = await payloadToProtoBuf('test.proto', 'TestPackage.TestStruct', {
"id": 1234,
"name": "calabash",
"email": "[email protected]"
})
return ctx.body = buf
}
})
app.listen(3000)
2. 关键编码原理
2.1 前置知识
变长编码和定长编码:
- 定长编码使用固定字节数来表示,如int32类型固定使用4个字节表示
- 变长编码是需要几个字节就使用几个字节,如对于int32类型的数字1来说,只需要1个字节
Protobuf采用Base-128变长编码,每个字节使用低7位来表示数字,除了最后一个字节,其他字节的最高位都设置为1
小端序和大端序
- Big-Endian:大端序,高位字节在前,低位字节在后,这是人类读写数值的方法
- Little-Endian:小端序,低位地址在前,高位地址在后

上图就很直观了,计算机的内部处理都是小端序,Protobuf也采用小端序
2.2 Base-128 可变长编码实战
数字300:
// 二进制表示
0000000100101100
// Base-128变长编码表示
0000010 0101100
// 考虑到小端序,对调
0101100 0000010
// 除了最后一个字节,其他字节的最高位都设置为1
10101100 00000010
// 转换为16进制表示
AC 02
数字1234:
// 二进制表示
00000100 11010010
// Base-128变长编码表示
0001001 1010010
// 考虑到小端序列,对调
1010010 0001001
// 除了最后一个字节,其他字节的最高位都设置为1
11010010 00001001
// 转换为16进制表示
D2 09
2.3 TLV编码格式
TLV即Tag-Length-Value, Tag作为该字段的唯一标识,Length代表Value数据域的长度,最后即Value数据本身
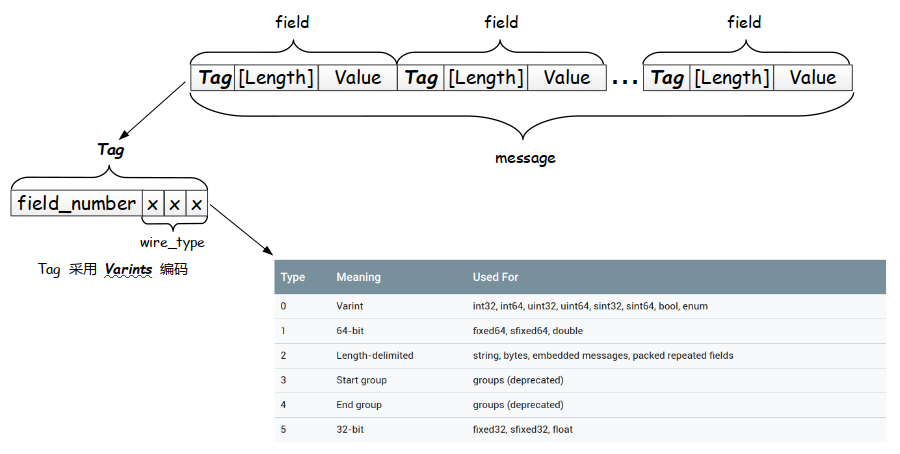
ProtoBuf编码采用类似的结构,但实际上又有较大的区别
-
TLV:编码表中Type=2的类型将使用这种结构,也就是说string采用TLV -
TV:编码表中Type=0,Type=1,Type=5的类型将使用这种结构,也就是说int32采用TV
图中的Wire_type解释:
- Type=0: 可变长编码类型,采用TV结构,计算方式参考2.2
- Type=1: 64bit定长,采用TV结构,无压缩
- Type=2: String类型,采用TVL结构,其中L采用可变长编码,V就是string具体的内容
- Type=5: 32bit定长,采用TV结构,无压缩
Tag的计算方式为: field_number << 3 | wire_type
字段编号1,2,3,计算出来的Tag值分别为:
// field_number = 1, wire_type = 2
1 << 3 | 2 = 10(10进制) = 0A(16进制)
// filed_number = 2, wire_type = 0
2 << 3 | 0 = 16(10进制) = 10(16进制)
// filed_number = 3, wire_type = 2
3 << 3 | 2 = 26(10进制) = 1A(16进制)
回顾上文的proto以及结果
// proto
message TestStruct {
string name = 1;
int32 id = 2;
string email = 3;
}
// 0A由类型string和编号1计算出
// 08代表string的长度:8个字节
// 16进制转换为字符串得到:calabash
0A
08 63 61 6C 61 62 61 73 68
// 10由类型int32和编号2计算出
// D2 09由Base-128 Varints整数变长编码计算出
10
D2 09
// 1A由类型string和编号3计算出
// 15代表string的长度:21个字节
// 16进制转换为字符串得到:[email protected]
1A
15 63 61 6C 61 62 61 73 68 40 63 61 6C 61 62 61 73 68 2E 63 6F 6D
2.4 负数的处理
如果要表示的数是一个负数,采用上面所说的方式编码,就会占用很多字节,因为对于比较常用(数值比较大)的负数来说,转成补码后会有很多个1,也就是说占用的字节会比较多,这样如果还采用上面那种方式编码,就得不偿失了,因此Google又新增加了一种数据类型,叫sint,专门用来处理这些负数,其实现原理是采用zigzag编码,zigzag编码的映射函数为:
ZigZag(n) = (n << 1) ^ (n << k),k为31或者63
最终的效果就是将负数映射为正整数,了解到这里即可
2.5 疑问
为什么文档中提到:“范围为1到15的字段编号需要一个字节来编码,16到2047之间的字段编号占用两个字节”
因为Tag由field_number << 3 | wire_type计算出,wire_type占用3位,最大也就是0000 0111, 那么field_number << 3最大也能取到1111 1000,为什么只能到15呢?
11111000 = 248 (10进制)
01111000 = 15 << 3 = 120 (10进制)
10000000 = 16 << 3 = 128 (10进制)
假设原因是Tag也采用可变长编码,将一个wire_type=2的字段的编号修改为16,得到其Tag值为两个字节:82 01, 将其还原:
// Tag值,16进制
82 01
// 转换为二进制
10000010 00000001
// 去掉1和0
0000010 0000001
// 对调
0000001 0000010
// 还原成10进制
130
130 - 2 = 128, 似乎得证明了,Tag也采用了可变长编码,可变长编码一个字节(7位)能表示的最大数字为127,因此字段编号超过15会用2个字节
3. 参考
worktile - Protocol Buffers序列化协议及应用