Suggested Framework Enhancements (with example Code)
I was looking for a lightweight agent framework, so a light langchain version. I found an article about your project and tried it out. It is nice and it is lightweight but for my use case it lacks a few features. I hacked a few classes together which add the features for me (the code is not optimized, just a quick working example). But if you are interested have a look at the extension i made to your agent framework and which address a few issues I encountered:
- Message transformers: The explicit input and output schemas of your framework are good, but it does not always work to feed the same theme into the next agent. I needed a message transformer which with little effort converts one agent's output to the next agent input without too much hazzle.
- Interconnect agents: To manually pass messages around between agents seems tedious. So I enhanced your BaseAgent to include an input and output ports which allow to connect the agents together and feed one output to the next agents input (after the optional transformation). So the connected agents send their output message to one or more connected agents input. This way the chain works automatically.
- Agent scheduler: Having an agent scheduler which steps the agent until there is nothing more to do, so all ports are emptied.
If you are interested have a look at : https://github.com/git5001/ConnectorAgents Feel free to integrate from my repo what you want. I probably will not work on this any more, but you can copy to your repo what you like.
There is an example application which reads news from the internet and mails them as an email to me, using a handful of interlinked agents. This works quite well.
PS: The multiple inheritance of the two tools can go away if the BaseAgent would already include the ports. I just did not want to change your base classes.
PPS: To make your framework really useful, it would also good to have more basic agents (forge tools), e.g. add an email agent, some debug or log agents, .... If people have a set of agents which do the most common tasks (like you already do with Taviliy and Scraper etc) they can get to work fast.
@git5001 Hi, sorry for getting back to this so late, but I did find your feedback very insightful!
I'll leave the issue open for now to come back to this later, because some of your ideas do sound like great quality-of-life improvements for some use cases
PS: I've been wanting to add some agents to the Atomic Forge like you suggested for months now, haven't gotten around to it yet, hopefully soon!
I changed the things a bit to make it more flexible and messed the repo up. Did not think anybody needs it right now and wanted to start over. I made the connect easier and added load save capability. It nearly works. If you need it right now I can commit the current version, otherwise I would have done it in a few days.
The main issue I am working on is to improve debug and restart capabilities. My pipeline runs very long and if it fails it would be good if I could restart it. This kind of works but not fully yet.
Since I implemented a second task with your agents, I am now even more happy with the framework. It works quite nice.
Ok I uploaded again what is already working. Changes are
- Better connect handling between agents in pipeline textMakerAgent2.connectTo(debugAgent1) or sinkAgent1.connectTo(emailAgent, transform_summaries_to_email)
- Better scheduler with support for loading and saving complete pipeline state
- Better list and multiport handling (List type is encapsulated into a schema now to stick with atomic agents parameter concept)
- Several Debug agents, DebugAgent, SaveJsonAgent, LoadJsonAgent, IdentityAgent (they are for debugging mainly, so you can pipe the output of agent to a file or the console or so)
Path: https://github.com/git5001/ConnectorAgents
I made another update which further improves the connection between agents. It works quite well now. Have a look at https://github.com/git5001/ConnectorAgents. Feel free to use any code you need or want.
I also added another example which does a quite intricate task with browsing and LLM (For anybody looking closely: the last step one should split and not do all in one loop, but otherwise its ok).
There are three examples available (the three test*.py files).
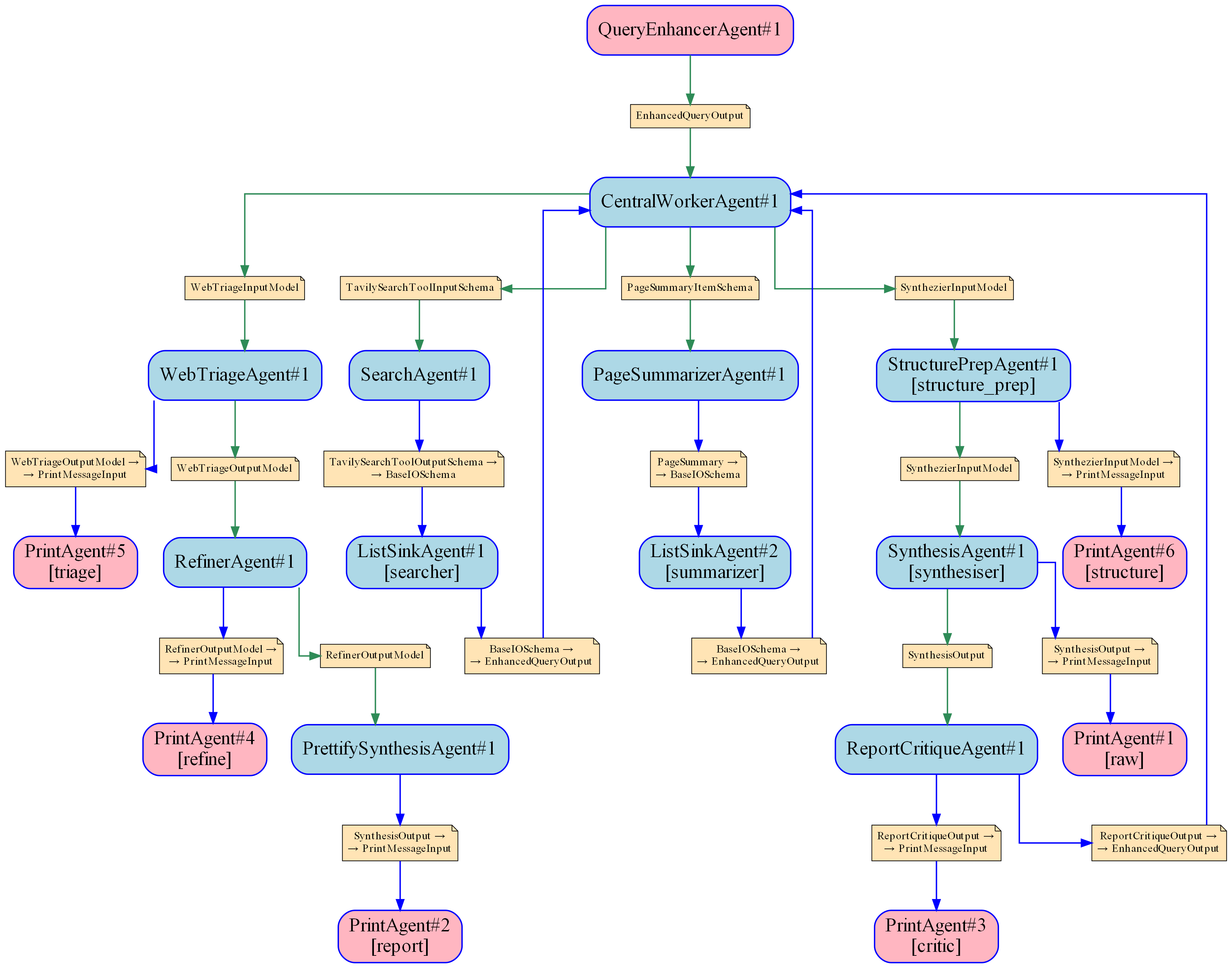
Due to the connection between agents you get connection diagrams (with or without data schemas) for free (it is included in the code as PiplinePrinter.py but needs 'dot' installed if it should work direcly to PNG):
Large diagram with data types

Medium diagram without data types

Medium diagram with data types
I played a bit more with various agent pipelines, e.g. a deep research one which works not so bad actually. But while doing so I wondered whether one should make the default agent multi schema for input and output? The current case with exactly one input and output schema would have then just one entry in a list[schema] or dict[..,schema].
But I am not totally sure, just up for discussion.
- Con: Few agents do need multi input and output, so overhead, but does it matter?
- Pro: The additional overwritten Multiport agents add odd behaviour for the schema handling, having this in the base class simplifies that a lot.
Example of the deep research pipeline (https://github.com/git5001/ConnectorAgents/tree/main/AgentDeepResearch):
- Note: I did try here on purpose to use a central worker agent to see how the multi port stuff works. You could most likely do the pipeline also just sequentially.