[BUG] EventHubScaleMonitor does not vote to scale in for applications with overall decreasing, but locally oscillating event counts
Library name and version
EventHubs 5.1.1.0
Describe the bug
In order for the EventHubScaleMonitor to vote for a scale in, the active message count needs to be decreasing for the last 5 samples. The events that are sent to the following cx's application do not follow a strict downwards trend per sample, so the EventHubMonitor never votes to scale in. However, the overall trend clearly shows that the event count has been decreasing, and we should be voting to scale in. The impact of this is that the cx's app is stuck at 100 workers, incurring significant cost. See Incident-334978579 Details - IcM (microsofticm.com) for details
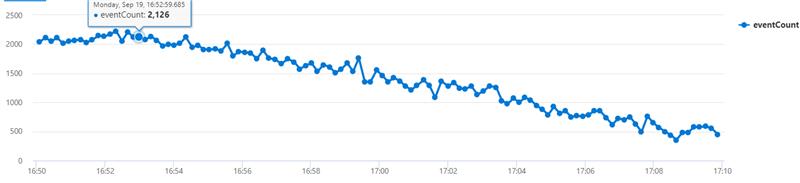

Execute in [Web] [Desktop] [cluster('wawseus.kusto.windows.net').database('wawsprod')] FunctionsLogs | where PreciseTimeStamp between(datetime(2022-9-19 16:50) .. 20min) | where AppName =~ "a202986-p1-musea2-logic001-dec" | where Source == "Microsoft.Azure.WebJobs.Script.Scale.FunctionsScaleMonitorService" | where Summary startswith "Scale metrics sample for monitor 'host.functions.decision-agent-eventhubtrigger-decision-eventhubtopic-decisionagentconsumergroup'" | parse Summary with "Scale metrics sample for monitor 'host.functions.decision-agent-eventhubtrigger-decision-eventhubtopic-decisionagentconsumergroup': " info | project PreciseTimeStamp, info | extend eventCount = split(split(info, ",", 0), ":", 1) | extend infoJson = parse_json(info) | extend eventCount = toint(infoJson.EventCount) | project PreciseTimeStamp, eventCount | render timechart
Execute in [Web] [Desktop] [cluster('wawseus.kusto.windows.net').database('wawsprod')] FunctionsLogs | where PreciseTimeStamp between(datetime(2022-9-19 16:50) .. 20min) | where AppName =~ "a202986-p1-musea2-logic001-dec" | where Source == "Microsoft.Azure.WebJobs.Script.Scale.FunctionsScaleManager" | where Summary startswith "Monitor" | extend finalVote = split(Summary, " ", 3) | extend monitorName = split(split(Summary, " ", 1), ".", 2) | where Source contains "scale" | project PreciseTimeStamp, monitorName, finalVote | where monitorName contains "decision-agent-eventhubtrigger-decision-eventhubtopic-decisionagentconsumergroup" | summarize ScaleOutVotes=countif(finalVote has 'ScaleOut'), ScaleInVotes=countif(finalVote has 'ScaleIn'), MaintainVotes=countif(finalVote has 'None') by bin(PreciseTimeStamp, 1min), tostring(monitorName) | render timechart
Expected behavior
EventHubScaleMonitor should vote to scale in based on the overall trend. An immediate fix would be to take averages of the samples in batches of 3, so if we have 10 samples taken, scale in if avg(samples[0:3]) < avg([3:6]) < avg(samples[7:10]) etc. Regarding a long term approach, the scaling team is moving towards targetBasedScaling, which determines the number of workers based on a point-in-time queueLength, (targetWorkers = queueLength/targetMetricValue). This would remove logic needed to determine decreasing samples, etc. and address the bug that this application is facing.
Actual behavior
The EventHubScaleMonitor votes to maintain state, causing the application to stall at 100 workers
Reproduction Steps
Send messages such that the active message count is steadily decreasing but locally oscillating. Perhaps a pattern where additional events send follow a -10, +5 pattern. For example, send a batch of messages every 10 seconds, with 100, 90, 95, 85, 90, etc.
Environment
No response
Label prediction was below confidence level 0.6 for Model:CategoryLabels: 'Mgmt:0.51443124,Client:0.34426937,Service:0.13947414'
@chiangvincent: I'm going to close this out, as the new scale monitor design obviates this. Please let me know if you disagree.