AutoGPTQ
 AutoGPTQ copied to clipboard
AutoGPTQ copied to clipboard
Comprehensive benchmarking of AutoGPTQ; Triton vs CUDA; vs old 'ooba' GfL
Over on @Laaza's text-gen-ui PR there has been discussion of inference performance.
In particular, people are concerned that recent versions of GPTQ-for-LLaMa have performed worse than the older versions. This is one reason why many people still use ooba's fork of GfL.
In order to help people understand the improvements AutoGPTQ has made, and also to help @PanQiWei and @qwopqwop200 look at potential performance differences in AutoGPTQ, I have compiled a list of benchmarks.
I have compared AutoGPTQ CUDA, AutoGPTQ Triton and the old GfL ooba fork with CUDA.
I've compared act-order/desc_act vs not, with and without streaming in text-gen-UI, and with/without the fused_attn and fused_mlp parameters.
I've not done absolutely every possible permutation of all those params. I only ran a few tests with streaming enabled in text-gen-ui as it always performs much worse. But I think I have enough here to get a good overview.
I will be posting these figures in the text-gen-ui PR thread as well.
Other benchmarks to do
To these results we could also add the latest GPTQ-for-LLaMa Triton and CUDA figures. I did already benchmark that yesterday and it compared the same or worse than AutoGPTQ. But later today I will run those benchmarks again and add them to the spreadsheet in this new format.
I would also like to test with some weaker/smaller GPUs, to see how performance might vary with less GPU processing available. And I'd also like to test on some larger models, to see if there is any difference in performance delta with varying model sizes.
Benchmarks of: ooba CUDA; AutoGPTQ CUDA; AutoGPTQ Triton
Implementations tested
- AutoGPTQ as of https://github.com/PanQiWei/AutoGPTQ/pull/43, using text-gen-ui from LaaZa's AutoGPTQ PR
- GPTQ-for-LLaMa using ooba's GfL fork (oobabooga/GPTQ-for-LLaMa), using text-gen-ui from
main, commit:875da16b7bc2a676d1a9d389bf22ee4579722073.
Test system
- Ubuntu 20.04, with Docker https://hub.docker.com/repository/docker/thebloke/runpod-pytorch-new/general
- CUDA toolkit 11.6
- NVidia 4090 24GB
- WizardLM 7B 128g
Test method
- All benchmarking done in text-gen-ui, using the output time and token/s reported by it.
- text-gen-ui restarted between each test.
- Output limit = 512 tokens.
- 'Default' paramater set used + 'ban eos token' set so as to always get 512 tokens returned
- Run one test and discard results as warm up, then record 4 results.
Results spreadsheet and overview charts
Spreadsheet
Google sheets with results and charts
Charts
A chart showing streaming performance is in the spreadsheet.
Description of results
AutoGPTQ vs 'ooba' CUDA with --no-stream
- AutoGPTQ CUDA outperforms GfL 'ooba' CUDA by 15% on a no-act-order model
- AutoGPTQ CUDA outperforms GfL 'ooba' CUDA by 10% on an act-order model (comparing AutoGPTQ on act-order model to GfL on no-act-order model)
- AutoGPTQ Triton is 5% slower than GfL 'ooba' CUDA
- AutoGPTQ Triton is 20% slower than AutoGPTQ CUDA
AutoGPTQ vs 'ooba' CUDA with streaming (no-act-order model)
- AutoGPTQ CUDA outperforms GfL 'ooba' CUDA by 12%
- AutoGPTQ CUDA outperforms AutoGPTQ Triton by 13%
- AutoGPTQ Triton outperforms GfL 'ooba' CUDA by 15%
- Interesting that with streaming on, Triton does better than GfL CUDA.
desc_act models vs non-desc_act models
- AutoGPTQ CUDA is 4.5% slower on a desc_act model vs not
- AutoGPTQ Triton has no performance difference between desc_act model vs not
- AutoGPTQ CUDA records significantly higher GPU usage % on desc_act models
- 80% usage with desc_act + fused_attn vs 30% with no-desc_act model
- This might be a problem on weaker cards? That needs testing.
- AutoGPTQ Triton has only a few % extra GPU usage with desc_act models.
fused_attn and fused_mlp
- AutoGPTQ CUDA: fused_attn increases performance by 20%
- This seems to account for nearly all the performance difference between AutoGPTQ CUDA and ooba GfL CUDA
- AutoGPTQ Triton: fused_mlp on its own increases performance by 15%
- AutoGPTQ Triton: fused_attn on its own increases performance by 26%
- AutoGPTQ Triton: fused_mlp and fused_attn together increases performance over no/no by 48%
Slow loading time with AutoGPTQ Triton
- AutoGPTQ Triton takes significantly longer to load a model vs CUDA
- I didn't record yet benchmarks for this, but from looking through my logs I see:
- CUDA: 2 -3 seconds
- Triton: 40-45 seconds (with or without fused_mlp)
- Triton + fused_attn: 55 - 90 seconds
- I'll add this to the benchmark table later.
- I didn't record yet benchmarks for this, but from looking through my logs I see:
Results table
| Implementation | Method | Streaming | Model type | fused_attn | fused_mlp | GPU usage max % | VRAM max after 512 tok | Avg token/s | Run 1 tokens/s | Run 2 tokens/s | Run 3 tokens/s | Run 4 tokens/s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ooba GfL | CUDA | No | no-act-order | N/A | N/A | 25% | 5837 | 23.84 | 23.86 | 23.91 | 23.70 | 23.90 |
| AutoGPTQ | CUDA | No | no-act-order | No | N/A | 24% | 6711 | 22.66 | 22.63 | 22.63 | 22.78 | 22.61 |
| AutoGPTQ | CUDA | No | no-act-order | Yes | N/A | 28% | 6849 | 27.22 | 27.23 | 27.33 | 27.33 | 27.00 |
| AutoGPTQ | Triton | No | no-act-order | No | No | 27% | 6055 | 15.25 | 15.25 | 15.25 | 15.29 | 15.20 |
| AutoGPTQ | Triton | No | no-act-order | No | Yes | 30% | 6691 | 17.48 | 17.52 | 17.51 | 17.43 | 17.47 |
| AutoGPTQ | Triton | No | no-act-order | Yes | No | 30% | 6013 | 19.33 | 19.37 | 19.42 | 19.29 | 19.24 |
| AutoGPTQ | Triton | No | no-act-order | Yes | Yes | 34% | 6649 | 22.58 | 22.19 | 22.67 | 22.70 | 22.75 |
| AutoGPTQ | CUDA | No | act-order | No | N/A | 64% | 6059 | 20.35 | 20.38 | 20.42 | 20.31 | 20.30 |
| AutoGPTQ | CUDA | No | act-order | Yes | N/A | 80% | 6079 | 26.02 | 26.12 | 26.15 | 26.18 | 25.61 |
| AutoGPTQ | Triton | No | act-order | No | No | 30% | 6057 | 15.39 | 15.47 | 15.30 | 15.35 | 15.42 |
| AutoGPTQ | Triton | No | act-order | No | yes | 33% | 6691 | 17.48 | 17.54 | 17.53 | 17.38 | 17.48 |
| AutoGPTQ | Triton | No | act-order | Yes | No | 33% | 6013 | 19.55 | 19.56 | 19.59 | 19.51 | 19.55 |
| AutoGPTQ | Triton | No | act-order | Yes | yes | 38% | 6649 | 22.86 | 22.86 | 23.01 | 22.98 | 22.57 |
| ooba GfL | CUDA | Yes | no-act-order | N/A | N/A | 17% | 5837 | 14.93 | 14.86 | 14.77 | 15.05 | 15.05 |
| AutoGPTQ | CUDA | Yes | no-act-order | No | N/A | 20% | 6711 | 16.85 | 16.94 | 16.84 | 16.87 | 16.76 |
| AutoGPTQ | CUDA | Yes | no-act-order | Yes | no | 22% | 6849 | 19.55 | 19.87 | 19.40 | 19.50 | 19.41 |
| AutoGPTQ | Triton | Yes | no-act-order | Yes | Yes | 27% | 6429 | 17.19 | 17.08 | 17.38 | 17.15 | 17.14 |
| AutoGPTQ | Triton | Yes | act-order | No | No | 25% | 6055 | 12.43 | 12.39 | 12.46 | 12.40 | 12.47 |
| AutoGPTQ | Triton | Yes | act-order | Yes | Yes | 33% | 6649 | 17.19 | 17.03 | 17.03 | 17.26 | 17.42 |
Benchmark logs
Benchmark logs in full
ooba GPTQ-for-LLaMA CUDA no streaming (--no-stream). no-act-order model. no fused_attn
Command
python server.py --model wiz-no-act --wbits 4 --groupsize 128 --model_type llama --listen --no-stream
Benchmark
GPU usage max: 25%, VRAM idle: 6037, VRAM after 512 tokens: 5837
Output generated in 21.46 seconds (23.86 tokens/s, 512 tokens, context 16, seed 104167586)
Output generated in 21.41 seconds (23.91 tokens/s, 512 tokens, context 16, seed 448558865)
Output generated in 21.60 seconds (23.70 tokens/s, 512 tokens, context 16, seed 816202521)
Output generated in 21.42 seconds (23.90 tokens/s, 512 tokens, context 16, seed 63649370)
ooba GPTQ-for-LLaMA CUDA with streaming. no-act-order model. no fused_attn
Command
python server.py --model wiz-no-act --wbits 4 --groupsize 128 --model_type llama --listen
Benchmark
GPU usage max: 17%, VRAM idle: 5247, VRAM after 512 tokens: 5837
Output generated in 34.39 seconds (14.86 tokens/s, 511 tokens, context 16, seed 572742302)
Output generated in 34.60 seconds (14.77 tokens/s, 511 tokens, context 16, seed 677465334)
Output generated in 33.95 seconds (15.05 tokens/s, 511 tokens, context 16, seed 1685629937)
Output generated in 33.95 seconds (15.05 tokens/s, 511 tokens, context 16, seed 1445023832)
AutoGPTQ CUDA no streaming (--no-stream). no-act-order model. fused_attn enabled
Command
python server.py --model wiz-no-act --autogptq --listen --quant_attn --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 28%, VRAM idle: 6849, VRAM after 512 tokens: 6849
Output generated in 18.81 seconds (27.23 tokens/s, 512 tokens, context 16, seed 1130150188)
Output generated in 18.74 seconds (27.33 tokens/s, 512 tokens, context 16, seed 939013757)
Output generated in 18.73 seconds (27.33 tokens/s, 512 tokens, context 16, seed 1724107769)
Output generated in 18.97 seconds (27.00 tokens/s, 512 tokens, context 16, seed 54252597)
AutoGPTQ CUDA with streaming. no-act-order model. fused_attn enabled
Command
python server.py --model wiz-no-act --autogptq --listen --quant_attn --wbits 4 --groupsize 128 --model_type llama
Benchmark
GPU usage max: 22%, VRAM idle: 5437, VRAM after 512 tokens: 6849
Output generated in 25.71 seconds (19.87 tokens/s, 511 tokens, context 16, seed 1472734050)
Output generated in 26.33 seconds (19.40 tokens/s, 511 tokens, context 16, seed 1285036592)
Output generated in 26.20 seconds (19.50 tokens/s, 511 tokens, context 16, seed 938935319)
Output generated in 26.32 seconds (19.41 tokens/s, 511 tokens, context 16, seed 2142008394)
AutoGPTQ CUDA no streaming (--no-stream). no-act-order model. no fused_attn
Command
python server.py --model wiz-no-act --autogptq --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 24%, VRAM idle: 6711, VRAM after 512 tokens: 6711
Output generated in 22.63 seconds (22.63 tokens/s, 512 tokens, context 16, seed 1551481428)
Output generated in 22.63 seconds (22.63 tokens/s, 512 tokens, context 16, seed 1993869704)
Output generated in 22.48 seconds (22.78 tokens/s, 512 tokens, context 16, seed 596462747)
Output generated in 22.64 seconds (22.61 tokens/s, 512 tokens, context 16, seed 619504695)
AutoGPTQ CUDA with streaming. no-act-order model. no fused_attn
Command
python server.py --model wiz-no-act --autogptq --listen --wbits 4 --groupsize 128 --model_type llama
Benchmark
GPU usage max: 20%, VRAM idle: 5277, VRAM after 512 tokens: 6711
Output generated in 30.16 seconds (16.94 tokens/s, 511 tokens, context 16, seed 709588940)
Output generated in 30.34 seconds (16.84 tokens/s, 511 tokens, context 16, seed 574596607)
Output generated in 30.30 seconds (16.87 tokens/s, 511 tokens, context 16, seed 16071815)
Output generated in 30.48 seconds (16.76 tokens/s, 511 tokens, context 16, seed 1202346043)
AutoGPTQ CUDA no streaming (--no-stream). act-order / desc_act model. fused_attn=yes
Command
python server.py --model wiz-act --autogptq --listen --quant_attn --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 80%, VRAM idle: 6077, VRAM after 512 tokens: 6079
Output generated in 19.60 seconds (26.12 tokens/s, 512 tokens, context 16, seed 1857860293)
Output generated in 19.58 seconds (26.15 tokens/s, 512 tokens, context 16, seed 616647949)
Output generated in 19.56 seconds (26.18 tokens/s, 512 tokens, context 16, seed 1384039801)
Output generated in 19.99 seconds (25.61 tokens/s, 512 tokens, context 16, seed 411623614)
AutoGPTQ CUDA no streaming (--no-stream). act-order / desc_act model. fused_attn=no
Command
python server.py --model wiz-act --autogptq --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 64%, VRAM idle: 6059, VRAM after 512 tokens: 6059
Output generated in 25.12 seconds (20.38 tokens/s, 512 tokens, context 16, seed 1777836493)
Output generated in 25.07 seconds (20.42 tokens/s, 512 tokens, context 16, seed 349075793)
Output generated in 25.21 seconds (20.31 tokens/s, 512 tokens, context 16, seed 188931785)
Output generated in 25.22 seconds (20.30 tokens/s, 512 tokens, context 16, seed 485419750)
AutoGPTQ Triton no streaming (--no-stream). no-act-order model. fused_attn=yes. fused_mlp=yes
Command
python server.py --model wiz-no-act --autogptq --autogptq-triton --fused_mlp --quant_attn --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 34%, VRAM idle: 6649, VRAM after 512 tokens: 6649
Output generated in 23.07 seconds (22.19 tokens/s, 512 tokens, context 16, seed 1396024982)
Output generated in 22.59 seconds (22.67 tokens/s, 512 tokens, context 16, seed 1322798716)
Output generated in 22.56 seconds (22.70 tokens/s, 512 tokens, context 16, seed 935785726)
Output generated in 22.50 seconds (22.75 tokens/s, 512 tokens, context 16, seed 2135223819)
AutoGPTQ Triton with streaming. no-act-order model. fused_attn=yes. fused_mlp=yes
Command
python server.py --model wiz-no-act --autogptq --autogptq-triton --fused_mlp --quant_attn --listen --wbits 4 --groupsize 128 --model_type llama
Benchmark
GPU usage max: 27%, VRAM idle: 6299, VRAM after 512 tokens: 6429
Output generated in 29.92 seconds (17.08 tokens/s, 511 tokens, context 16, seed 1687853126)
Output generated in 29.40 seconds (17.38 tokens/s, 511 tokens, context 16, seed 1796675019)
Output generated in 29.79 seconds (17.15 tokens/s, 511 tokens, context 16, seed 1342449921)
Output generated in 29.81 seconds (17.14 tokens/s, 511 tokens, context 16, seed 1283884954)
AutoGPTQ Triton no streaming (--no-stream). no-act-order model. fused_attn=no. fused_mlp=no
Command
python server.py --model wiz-no-act --autogptq --autogptq-triton --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 27%, VRAM idle: 6055, VRAM after 512 tokens: 6055
Output generated in 33.57 seconds (15.25 tokens/s, 512 tokens, context 16, seed 1071469137)
Output generated in 33.58 seconds (15.25 tokens/s, 512 tokens, context 16, seed 1554707022)
Output generated in 33.48 seconds (15.29 tokens/s, 512 tokens, context 16, seed 588803760)
Output generated in 33.69 seconds (15.20 tokens/s, 512 tokens, context 16, seed 719688473)
AutoGPTQ Triton no streaming (--no-stream). no-act-order model. fused_attn=no. fused_mlp=yes
Command
python server.py --model wiz-no-act --autogptq --autogptq-triton --fused_mlp --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 30%, VRAM idle: 6691, VRAM after 512 tokens: 6691
Output generated in 29.23 seconds (17.52 tokens/s, 512 tokens, context 16, seed 1413673599)
Output generated in 29.24 seconds (17.51 tokens/s, 512 tokens, context 16, seed 2120666307)
Output generated in 29.38 seconds (17.43 tokens/s, 512 tokens, context 16, seed 2057265550)
Output generated in 29.32 seconds (17.47 tokens/s, 512 tokens, context 16, seed 1082953773)
AutoGPTQ Triton no streaming (--no-stream). no-act-order model. fused_attn=yes. fused_mlp=no
Command
python server.py --model wiz-no-act --autogptq --autogptq-triton --quant_attn --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 30%, VRAM idle: 6013, VRAM after 512 tokens: 6013
Output generated in 26.43 seconds (19.37 tokens/s, 512 tokens, context 16, seed 1512231234)
Output generated in 26.36 seconds (19.42 tokens/s, 512 tokens, context 16, seed 2018026458)
Output generated in 26.54 seconds (19.29 tokens/s, 512 tokens, context 16, seed 1882161798)
Output generated in 26.61 seconds (19.24 tokens/s, 512 tokens, context 16, seed 1512440780)
AutoGPTQ Triton no streaming (--no-stream). act-order/desc_act model. fused_attn=yes. fused_mlp=yes
Command
python server.py --model wiz-act --autogptq --autogptq-triton --fused_mlp --quant_attn --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max: 38%, VRAM idle: 6649, VRAM after 512 tokens: 6649
Output generated in 22.40 seconds (22.86 tokens/s, 512 tokens, context 16, seed 1359206825)
Output generated in 22.25 seconds (23.01 tokens/s, 512 tokens, context 16, seed 609149608)
Output generated in 22.28 seconds (22.98 tokens/s, 512 tokens, context 16, seed 226374340)
Output generated in 22.68 seconds (22.57 tokens/s, 512 tokens, context 16, seed 1070157383)
AutoGPTQ Triton with streaming. act-order/desc_act model. fused_attn=yes. fused_mlp=yes
Command
python server.py --model wiz-act --autogptq --autogptq-triton --fused_mlp --quant_attn --listen --wbits 4 --groupsize 128 --model_type llama
Benchmark
GPU usage max: 33%, VRAM idle: 6299, VRAM after 512 tokens: 6649
Output generated in 30.00 seconds (17.03 tokens/s, 511 tokens, context 16, seed 456349974)
Output generated in 30.00 seconds (17.03 tokens/s, 511 tokens, context 16, seed 767092960)
Output generated in 29.61 seconds (17.26 tokens/s, 511 tokens, context 16, seed 381684718)
Output generated in 29.33 seconds (17.42 tokens/s, 511 tokens, context 16, seed 283294303)
AutoGPTQ Triton no streaming (--no-stream). act-order/desc_act model. fused_attn=no. fused_mlp=yes
Command
python server.py --model wiz-act --autogptq --autogptq-triton --fused_mlp --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max:33%, VRAM idle: 6691, VRAM after 512 tokens: 6691
Output generated in 29.19 seconds (17.54 tokens/s, 512 tokens, context 16, seed 1575265983)
Output generated in 29.21 seconds (17.53 tokens/s, 512 tokens, context 16, seed 1616043283)
Output generated in 29.47 seconds (17.38 tokens/s, 512 tokens, context 16, seed 1647334679)
Output generated in 29.29 seconds (17.48 tokens/s, 512 tokens, context 16, seed 256676128)
AutoGPTQ Triton no streaming (--no-stream). act-order/desc_act model. fused_attn=yes. fused_mlp=no
Command
python server.py --model wiz-act --autogptq --autogptq-triton --quant_attn --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max:33%, VRAM idle: 6013, VRAM after 512 tokens: 6013
Output generated in 26.18 seconds (19.56 tokens/s, 512 tokens, context 16, seed 289490511)
Output generated in 26.13 seconds (19.59 tokens/s, 512 tokens, context 16, seed 2123553925)
Output generated in 26.24 seconds (19.51 tokens/s, 512 tokens, context 16, seed 563248868)
Output generated in 26.19 seconds (19.55 tokens/s, 512 tokens, context 16, seed 1773520422)
AutoGPTQ Triton no streaming (--no-stream). act-order/desc_act model. fused_attn=no. fused_mlp=no
Command
python server.py --model wiz-act --autogptq --autogptq-triton --listen --wbits 4 --groupsize 128 --model_type llama --no-stream
Benchmark
GPU usage max:30%, VRAM idle: 6057, VRAM after 512 tokens: 6057
Output generated in 33.09 seconds (15.47 tokens/s, 512 tokens, context 16, seed 1881763981)
Output generated in 33.47 seconds (15.30 tokens/s, 512 tokens, context 16, seed 83555537)
Output generated in 33.36 seconds (15.35 tokens/s, 512 tokens, context 16, seed 332008224)
Output generated in 33.20 seconds (15.42 tokens/s, 512 tokens, context 16, seed 657280485)
AutoGPTQ Triton with streaming. act-order/desc_act model. fused_attn=no. fused_mlp=no
Command
python server.py --model wiz-act --autogptq --autogptq-triton --listen --wbits 4 --groupsize 128 --model_type llama
Benchmark
GPU usage max: 25%, VRAM idle: 5503, VRAM after 512 tokens: 6055
Output generated in 41.23 seconds (12.39 tokens/s, 511 tokens, context 16, seed 1164743843)
Output generated in 41.02 seconds (12.46 tokens/s, 511 tokens, context 16, seed 509370735)
Output generated in 41.21 seconds (12.40 tokens/s, 511 tokens, context 16, seed 246113358)
Output generated in 40.99 seconds (12.47 tokens/s, 511 tokens, context 16, seed 667851869)
Here is my result on rtx 3090 for 100 tokens total for llama 7B :
import time
timea = time.time()
input_text = "The benefits of deadlifting are:"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda:0")
out = model11.generate(input_ids=input_ids,max_length=100)
print(tokenizer.decode(out[0]))
print("took",-timea + time.time())
the result (50 words, i guess 100 tokens, but I did not measure):
<s> The benefits of deadlifting are:
Increased strength and muscle mass
Improved posture and core strength
Improved grip strength
Improved balance and coordination
Improved bone density and joint health
Improved athletic performance and recovery
Improved mood and self-esteem
Improved ability to perform daily tasks
Improved ability to perform work tasks
Improved ability to perform sports
Im
took 2.3102331161499023
So if the methodology is is the same, this is around 40 tokens per second on RTX 3090. While 4bit was 2-3x slower.
OK thanks. Can you show the full code please, including defining the model etc. Then I will repeat the test also
I have some code to measure exact tokens/s (copied from text-generation-webui) so I will run tests of:
- float16 HF model
- 8bit HF model
- 4bit GPTQ
I used this one, i just load "huggyllama/llama-7b" in 16 bit. This is correct code maybe with a small error somewhere, i hope not.
from transformers import AutoTokenizer,AutoModelForCausalLM
pretrained_model_dir = "huggyllama/llama-7b"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir, use_fast=True)
model11 = AutoModelForCausalLM.from_pretrained(pretrained_model_dir).half().eval().to("cuda")
import time
timea = time.time()
input_text = "The benefits of deadlifting are:"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda:0")
out = model11.generate(input_ids=input_ids,max_length=100)
print(tokenizer.decode(out[0]))
print("took",-timea + time.time())
Awesome.
For 8bit HF model, i get very terrible speed, even with some optimisation that they recommended on HF it is 3-4x slower than fp16.
Note: I first wrote a reply last night but I have deleted it and replaced it. This is because I had a bug in my test code, so my GPTQ results were wrong. (Due to a typo I wasn't applying fused_attn as I thought I was!)
For 8bit HF model, i get very terrible speed, even with some optimisation that they recommended on HF it is 3-4x slower than fp16.
Sorry for the delay. I have been working on writing a comprehensive testing script for GPTQ and HF models. I will publish it soon so others can test as well.
Here are some results, on a 7B model tested on a 4090.
I tested with this Llama 7B model as I converted it recently:
- GPTQ 4bit: https://huggingface.co/TheBloke/WizardLM-7B-uncensored-GPTQ
- HF 16bit: https://huggingface.co/ehartford/WizardLM-7B-Uncensored
Quick summary:
- Performance with AutoGPTQ CUDA is ~21% higher than with HF fp16: 28.251 tok/s vs 22.99 tok/s
- The performance difference is entirely due to AutoGPTQ's
fused_attn - If AutoGPTQ
fused_attnis disabled, performance is almost identical - Therefore if the user implemented fused_attn for an HF model as well, I imagine it would perform the same. I will try to look into how I could benchmark that for HF models.
- The performance difference is entirely due to AutoGPTQ's
- VRAM on HF is much higher of course (15GB vs 7.5GB AutoGPTQ)
- GPU usage % is also higher on HF (45% vs 27%)
- You are right, 8bit HF is very slow. I think right now it's only useful if you can't use GPTQ and you are low on VRAM for the model size
- However I have heard reports that a new version of
bitsandbytesis coming soon which will be faster, and will support 4bit as well: https://twitter.com/Tim_Dettmers/status/1654917326381228033?s=20
- However I have heard reports that a new version of
Conclusion: AutoGPTQ CUDA can outperform HF when fused_attn is used. Without fused_attn, it performs the same as HF fp16, but requires much less VRAM and has lower GPU usage %, making it usable on smaller GPUs.
I must admit, I thought the performance difference would be higher, given the big difference in model size. So maybe further optimisations are possible with AutoGPTQ to increase the performance improvement further.
Test:
- Testing with my own inference code in Python
- Run same prompt through 20x in a row
- 512 tokens returned each time (EOS is banned to ensure same number of tokens each time)
- HF model: loaded with
accelerate - GPTQ model: loaded with AutoGPTQ + CUDA + fused_attn
VRAM and GPU usage %
- HF fp16:
- VRAM: 14883 MiB
- GPU usage: 43 - 45%
- HF 8bit
- VRAM: 8877 MiB
- GPU usage: 19%
- AutoGPTQ CUDA + fused_attn:
- VRAM: 7509 MiB
- GPU usage: 22 - 29% (one very brief spike at 55%)
Model loading time
Models were loaded once prior to start of benchmark to ensure they're cached, so model loading times should be without disk access time.
- HF fp16 with
accelerate: 8.25 seconds - HF fp16 without
accelerate: 13.22 seconds - HF 8bit: 13.49 seconds
- AutoGPTQ CUDA: 2.78 seconds
- (AutoGPTQ Triton would be much slower)
Results:
HF fp16:
Average over 20 runs: 22.999 tokens/s (0.043 secs per token)
Result for 20 runs: tok/s (s/tok): 22.253 (0.045s), 23.066 (0.043s), 23.072 (0.043s), 23.061 (0.043s), 23.038 (0.043s), 23.047 (0.043s), 23.038 (0.043s), 23.045 (0.043s), 23.025 (0.043s), 23.059 (0.043s), 23.070 (0.043s), 23.045 (0.043s), 23.092 (0.043s), 22.987 (0.044s), 23.041 (0.043s), 23.060 (0.043s), 23.052 (0.043s), 23.019 (0.043s), 22.968 (0.044s), 22.945 (0.044s)
HF 8bit with bitsandbytes:
I only ran 5 iterations because it's so slow :)
Average over 5 runs: 6.923 tokens/s (0.144 secs per token)
Result for 5 runs: tok/s (s/tok): 6.874 (0.145s), 6.881 (0.145s), 6.964 (0.144s), 6.966 (0.144s), 6.930 (0.144s)
AutoGPTQ CUDA + fused_attn
Average over 20 runs: 28.251 tokens/s (0.035 secs per token)
Result for 20 runs: tok/s (s/tok): 27.171 (0.037s), 28.449 (0.035s), 28.488 (0.035s), 28.451 (0.035s), 28.412 (0.035s), 28.363 (0.035s), 28.491 (0.035s), 28.214 (0.035s), 28.140 (0.036s), 28.358 (0.035s), 28.392 (0.035s), 28.132 (0.036s), 28.284 (0.035s), 28.276 (0.035s), 28.283 (0.035s), 28.356 (0.035s), 28.175 (0.035s), 28.050 (0.036s), 28.318 (0.035s), 28.219 (0.035s)
AutoGPTQ CUDA without fused_attn
Average over 20 runs: 22.833 tokens/s (0.044 secs per token)
Result for 20 runs: tok/s (s/tok): 22.208 (0.045s), 22.918 (0.044s), 22.906 (0.044s), 22.880 (0.044s), 22.914 (0.044s), 22.852 (0.044s), 22.861 (0.044s), 22.855 (0.044s), 22.865 (0.044s), 22.897 (0.044s), 22.871 (0.044s), 22.852 (0.044s), 22.903 (0.044s), 22.903 (0.044s), 22.858 (0.044s), 22.825 (0.044s), 22.849 (0.044s), 22.809 (0.044s), 22.825 (0.044s), 22.799 (0.044s)
Awesome news for bits and bytes, if they make it work faster. Other models such as for example t5 are not usable because small models also work 3-4 slower such as T5-large and T5-3B.
This really look too slow on rtx 4090, what was your exact code and prompt, you should be getting around 70 tokens per second minimum. This is a high end card.
I even run llama on a CPU and I get around 3 tokens per second, and this is a slow VPS CPU on hetzner, 8 cores with around 9K points on Passmark CPU benchmark total, around 1.6 pe single core, so I would say that lets say on 13500K (35K points and 4k per single core) it would run at around 12 tokens per second. And a rtx 4090 has to be more than 2x faster than that. 13500K is a 45 EUR CPU
Were you able to run this code:
from transformers import AutoTokenizer,AutoModelForCausalLM
pretrained_model_dir = "huggyllama/llama-7b"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir, use_fast=True)
model11 = AutoModelForCausalLM.from_pretrained(pretrained_model_dir).half().eval().to("cuda")
import time
timea = time.time()
input_text = "The benefits of deadlifting are:"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda:0")
out = model11.generate(input_ids=input_ids,max_length=100)
print(tokenizer.decode(out[0]))
print("took",-timea + time.time())
result:
<s> The benefits of deadlifting are:
Increased strength and muscle mass
Improved posture and core strength
Improved grip strength
Improved balance and coordination
Improved bone density and joint health
Improved athletic performance and recovery
Improved mood and self-esteem
Improved ability to perform daily tasks
Improved ability to perform work tasks
Improved ability to perform sports
Im
took 2.3102331161499023
What system are you getting 2.31s on?
My result is much worse:
root@7f9412708170:/workspace# python test_huggy7b.py
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.30it/s]
<s> The benefits of deadlifting are:
Increased strength and muscle mass
Improved posture and core strength
Improved grip strength
Improved balance and coordination
Improved bone density and joint health
Improved athletic performance and recovery
Improved mood and self-esteem
Improved ability to perform daily tasks
Improved ability to perform work tasks
Improved ability to perform sports
Im
took 3.452160596847534
root@7f9412708170:/workspace# python test_huggy7b.py
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.54it/s]
<s> The benefits of deadlifting are:
Increased strength and muscle mass
Improved posture and core strength
Improved grip strength
Improved balance and coordination
Improved bone density and joint health
Improved athletic performance and recovery
Improved mood and self-esteem
Improved ability to perform daily tasks
Improved ability to perform work tasks
Improved ability to perform sports
Im
took 3.4403083324432373
I'm running this on a Runpod system in the cloud. If you're saying I should get 2.3 seconds or less on a 4090 maybe there is some bottleneck other than the GPU..
This is output of nvidia-smi during those two tests:
timestamp, name, utilization.gpu [%], utilization.memory [%], memory.total [MiB], memory.free [MiB], memory.used [MiB]
...
2023/05/08 14:23:50.527, NVIDIA GeForce RTX 4090, 0 %, 0 %, 24564 MiB, 23763 MiB, 453 MiB
2023/05/08 14:23:52.528, NVIDIA GeForce RTX 4090, 29 %, 1 %, 24564 MiB, 10875 MiB, 13341 MiB
2023/05/08 14:23:54.529, NVIDIA GeForce RTX 4090, 54 %, 50 %, 24564 MiB, 10775 MiB, 13441 MiB
2023/05/08 14:23:56.530, NVIDIA GeForce RTX 4090, 63 %, 5 %, 24564 MiB, 24216 MiB, 1 MiB
2023/05/08 14:23:58.531, NVIDIA GeForce RTX 4090, 0 %, 0 %, 24564 MiB, 24216 MiB, 1 MiB
...
2023/05/08 14:24:52.554, NVIDIA GeForce RTX 4090, 0 %, 0 %, 24564 MiB, 24216 MiB, 1 MiB
2023/05/08 14:24:54.555, NVIDIA GeForce RTX 4090, 34 %, 1 %, 24564 MiB, 15555 MiB, 8661 MiB
2023/05/08 14:24:56.556, NVIDIA GeForce RTX 4090, 55 %, 51 %, 24564 MiB, 10795 MiB, 13421 MiB
2023/05/08 14:24:58.557, NVIDIA GeForce RTX 4090, 55 %, 51 %, 24564 MiB, 10711 MiB, 13505 MiB
2023/05/08 14:25:00.558, NVIDIA GeForce RTX 4090, 0 %, 0 %, 24564 MiB, 24216 MiB, 1 MiB
I will try on a system from another provider.
What is strange is that I also run on runpod.io, just Iuse rtx 3090.
It would be strange that RTX 4090 is slower than RTX 3090 for example. I mean you can probably run much more batches on RTX 4090, but still speed should be the same at least. The frequency of RTX 4090 is around 50 percent higher, so it should work 50 percent faster on one batch.
Did you use the default runpod OS, which is pytorch 2.0 and cuda 11.6 or 11.7?
I found that cuda 10.2 was the fastest for T5, for LLama I did not test, but you can only use cuda 10.2 on vast.ai out of cheap cloud providers.
That figure was with a 3090!? OK then yes that is very odd.
I'm definitely going to test some other systems then.
I use my own Docker container (https://hub.docker.com/repository/docker/thebloke/runpod-pytorch-new/general) but it is based on their latest pytorch 2 one with CUDA 11.7 (runpod/pytorch:3.10-2.0.0-117)
Here is the Dockerfile - as you can see, it doesn't change CUDA or torch, just gets latest versions of other pips and apt packages.
FROM runpod/pytorch:3.10-2.0.0-117
RUN /bin/bash -o pipefail -c 'apt update -y && apt upgrade -y && apt install -y --no-install-recommends tmux vim net-tools less git-lfs zsh p7zip rsync'
RUN /bin/bash -o pipefail -c 'python -m pip install --upgrade pip'
RUN /bin/bash -o pipefail -c 'pip uninstall -qy transformers peft datasets loralib sentencepiece safetensors accelerate triton bitsandbytes huggingface_hub flexgen rwkv'
RUN /bin/bash -o pipefail -c 'pip install -q transformers peft bitsandbytes datasets loralib sentencepiece safetensors accelerate triton huggingface_hub'
RUN /bin/bash -o pipefail -c 'pip install -q xformers texttable toml numpy markdown pyyaml tqdm requests gradio flexgen rwkv ninja wget'
RUN /bin/bash -o pipefail -c 'git config --global credential.helper store && git lfs install'
RUN /bin/bash -o pipefail -c 'cd ~ && git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa gptq-llama'
RUN /bin/bash -o pipefail -c 'cd ~ && git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa -b cuda gptq-llama-cuda'
RUN /bin/bash -o pipefail -c 'cd ~ && git clone https://github.com/PanQiWei/AutoGPTQ'
RUN /bin/bash -o pipefail -c 'cd ~ && git clone https://github.com/oobabooga/text-generation-webui && mkdir text-generation-webui/repositories && ln -s ~/gptq-llama text-generation-webui/repositories/GPTQ-for-LLaMa'
RUN /bin/bash -o pipefail -c 'cd ~ && git clone https://github.com/ggerganov/llama.cpp'
RUN /bin/bash -o pipefail -c 'pip install wget'
RUN /bin/bash -o pipefail -c 'apt update -y && apt install -y libopenblas-dev libopenblas-base'
RUN /bin/bash -o pipefail -c 'pip install fire'
COPY get_repo.py /root
RUN /bin/bash -o pipefail -c 'apt update -y && apt install -y zip unzip'
RUN /bin/bash -o pipefail -c 'apt-get clean && rm -rf /var/lib/apt/lists/*'
RUN /bin/bash -o pipefail -c 'pip install protobuf'
RUN /bin/bash -o pipefail -c 'cd ~ && git clone https://github.com/oobabooga/GPTQ-for-LLaMa ooba-gptq-llama'
COPY bashrc /root/.bashrc
RUN /bin/bash -o pipefail -c 'pip install peft --upgrade'
RUN /bin/bash -o pipefail -c 'apt update -y && apt install iputils-ping'
RUN /bin/bash -o pipefail -c 'pip install langchain'
RUN /bin/bash -o pipefail -c 'apt update -y && apt install traceroute'
RUN /bin/bash -o pipefail -c 'pip install rich'
I will test on some other systems and let you know.
My performance with 7B quantized (in textgen) is at most 20 tokens/s on a 3080. (cuda 11.8, WSL)
My performance with 7B quantized (in textgen) is at most 20 tokens/s on a 3080. (cuda 11.8, WSL)
But quantized is much slower than fp16 (and was broken), here is my result for 100 tokens (around 14 tokens per sec);
<s> The benefits of deadlifting are:Webachivendor BegriffsklärlisPrefix Dragonskyrilledominument Agencyferrerзовilen BoyscottingÙ Dez Collegadoionaopus zewnętrzipagegiaandeniernogreenilo PremiumitulslantпраniaelescontribetersZeroardihelmoportulibernste MasculATE counterharedients ==>vat Chiefурruspenas Float zewnętrzipagegiaandeniernogreenilo PremiumitulslantпраniaelescontribetersZeroardihelmoportulibernste MasculATE counterhared
took 7.574721097946167
Without quantizing it is 2.31 seconds for 100 tokens.
I guess it would work much faster on 3080 if you could load it in fp16
I mean, guys with CPP run around 10-15 tokens per sec in high end CPU. However, they don't get speed up for higher batch size.
My performance with 7B quantized (in textgen) is at most 20 tokens/s on a 3080. (cuda 11.8, WSL)
But quantized is much slower than fp16 (and was broken), here is my result for 100 tokens (around 14 tokens per sec);
<s> The benefits of deadlifting are:Webachivendor BegriffsklärlisPrefix Dragonskyrilledominument Agencyferrerзовilen BoyscottingÙ Dez Collegadoionaopus zewnętrzipagegiaandeniernogreenilo PremiumitulslantпраniaelescontribetersZeroardihelmoportulibernste MasculATE counterharedients ==>vat Chiefурruspenas Float zewnętrzipagegiaandeniernogreenilo PremiumitulslantпраniaelescontribetersZeroardihelmoportulibernste MasculATE counterhared took 7.574721097946167Without quantizing it is 2.31 seconds for 100 tokens.
I guess it would work much faster on 3080 if you could load it in fp16
Maybe, but I can't.
I know, 3090 is the same speed.
I guess after 2 weeks you will be able to run it faster, if they make plugin bitsandbytes support 4 bits and work faster, as they said.
What is strange is that I also run on runpod.io, just Iuse rtx 3090.
OK this is troubling. Nearly all Runpod servers I have tested are performing poorly. I found exactly one pod that performed well.
Test script:
import time
from transformers import AutoTokenizer,AutoModelForCausalLM
pretrained_model_dir = "huggyllama/llama-7b"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir, use_fast=True)
model11 = AutoModelForCausalLM.from_pretrained(pretrained_model_dir).half().eval().to("cuda")
num_runs = 20
results = []
for i in range(1, num_runs+1):
timea = time.time()
input_text = "The benefits of deadlifting are:"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda:0")
out = model11.generate(input_ids=input_ids,max_length=100)
print(tokenizer.decode(out[0]))
took = time.time() - timea
print("took", took)
results.append(took)
average = sum(results) / len(results)
print(f"Average over {num_runs} runs:", average)
Some results:
-
Runpod Secure Cloud 4090 pod 1 (Location: RO)
- max GPU usage: 55%
- Average over 20 runs: 3.005104184150696
-
Runpod community 4090 pod 1 (Location: PT)
- max GPU usage: 56%
- Average over 20 runs: 3.1650051712989806
-
Runpod community 4090 pod 2 (Location: SE)
- didn't even finish, was taking so ridiculously long to load the model that I aborted it
-
Runpod community 4090 pod 3 (Location: CA)
- max GPU usage: 57%
- Average over 20 runs: 3.013183331489563
-
Runpod community 4090 pod 4 (Location: CA)
- max GPU usage: 99%
- Average over 20 runs: 1.718130850791931
- FINALLY!
This is really frustrating because now every time I connect to a Runpod and want to do something performance related, I need to run a benchmark to confirm I'm actually getting a top performing server.
So what is the difference between the one that works and the others? I don't know
I thought it might be PCIe version or link width. But that CA server that performed well is only at PCIe x8, and several of the servers that performed badly are at x16.
Comparing the working Community server to one of the Secure poorly performing servers, I see Community has driver 525.78.01 vs 525.105.17.
I also see that the community server has twice as high TX and RX throughput as the Secure server, despite being PCIe x8 instead of 16x. Community pod 4 (good performance) is left, Secure pod 1 (bad performance) is right:
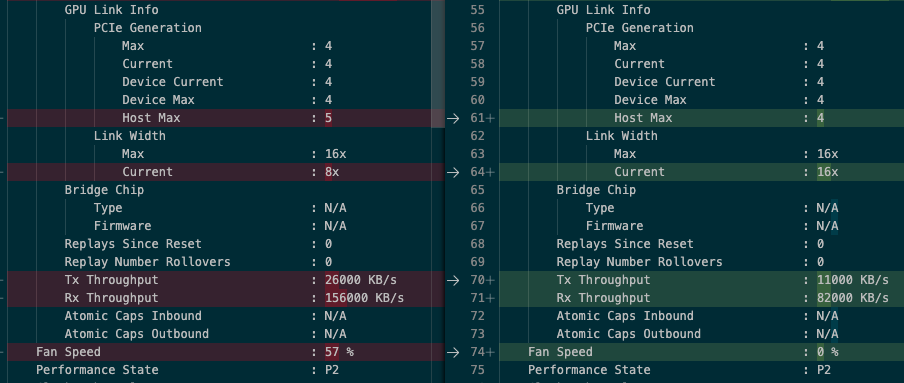
But I have no idea what causes that. And maybe that's a symptom of the problem, not the cause. Presumably there's some issue on the CPU/motherboard side, not GPU.
I don't know, but this is really annoying. I am definitely going to raise this as an issue to Runpod.
I'm going for dinner now but when I get back I will try to find a well-performing Runpod and then I will re-run my fp16 HF vs GPTQ benchmark again.
You did an awesome analysis so we know what the problems is. Perhaps their datacenter secure servers work better, we need to test that.
What I noticed is that rtx 3090 on runpod works with the same speed as my own server, that I installed with rtx 2080. And rtx 2080 is around 10 percent faster than those Hetzner servers with old GTX 1080.
Also I found that cuda 10.2 is the fastest, around 20 percent faster than cuda 11.0+, on rtx 2080, not sure for RTX 3090.
So when i need faster interface I will test some servers on vast.ai where I can choose cuda version. And it is a bit cheaper but less stable. For interface with multi servers it's fine.
Perhaps their datacenter secure servers work better, we need to test that.
Unfortunately not! In my earlier results I listed "Secure Cloud pod" - that is the 'datacenter secure server'. And it is just as bad!
So when i need faster interface I will test some servers on vast.ai where I can choose cuda version. And it is a bit cheaper but less stable. For interface with multi servers it's fine.
Yeah I definitely plan to try Vast.ai soon. I tested them once, just for 10 minutes. I didn't like their UI as much as Runpod, and the service felt more basic with fewer features. But if Runpod servers are going to be unreliable, I will definitely try Vast.ai as well.
New test script for Runpod servers
I am now using this test script for Runpod, downloading facebook-125m instead so it gets started a lot quicker
import time
import torch
from transformers import AutoTokenizer,AutoModelForCausalLM
pretrained_model_dir = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(pretrained_model_dir).eval().cuda()
num_runs = 20
results = []
def inference():
input_text = "The benefits of deadlifting are:"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.cuda()
with torch.no_grad():
out = model.generate(input_ids=input_ids,max_length=496)
for i in range(1,num_runs+1):
start_time = time.time()
inference()
duration = time.time() - start_time
print("Run time:", duration)
results.append(duration)
average = sum(results) / len(results)
print(f"Average over {num_runs} runs:", average)
I tuned the params so that on a Runpod 4090 server that performs properly, it returns in almost exactly 1.00 seconds:
Run time: 1.2180137634277344
Run time: 1.0310206413269043
Run time: 1.0049505233764648
...
Run time: 1.0063436031341553
Average over 20 runs: 1.0157599568367004
So it is quick to see the performance multiple on a bad 4090 server, like this:
Average over 20 runs: 3.5650864601135255
3.5 times slower!
And here is a Runpod Secure Cloud 3090:
Average over 20 runs: 3.541660189628601
Exactly the same - clearly showing it's bottlenecked and not able to properly use the GPU at all.
EDIT: And also the same on an A4000. This card should be ~40% slower than a 3090, and yet performs the same. This is crazy.
Next: new HF / GPTQ benchmarks. HOLY SHIT!
All I can say is.. wow. The performance on a properly performing 4090 is so much better.
Later EDIT: I subsequently realised that the reason for this enormous performance difference was the CPU. All prior benchmarks were CPU bottlenecked, and this one was not. The results below were with an i9-13900K, which is a leader in single-core performance. Previous results were with AMD Epyc server CPUs which have high core count but low per-core speeds.
I don't own any NV GPUs so I had no idea what a 4090 should be capable of with this stuff. I just assumed that if I got the same figure on multiple Runpod servers, it must be the real figure. And the figures I got for AutoGPTQ CUDA of ~28/s seemed to be in the right ballpark from what I'd read other people were getting with text-gen-ui.
I'm really glad you raised these issues, @Oxi84 else I might still not know.
So here's the figures. Completely different. Tomorrow I will try Vast.ai as well, to confirm these figures really are the max for a 4090. I've also sent a message to a friend with a 4090 to ask him to run my quick test script, to compare his figures.
Anyway, here's the HF + AutoGPTQ benchmarks for a good 4090 system!
Summary: WizardLM 7B-Uncensored (Llama)
- HF fp16: 50.741 tok/s
- AutoGPTQ CUDA: 76.588 tok/s
- AutoGPTQ CUDA + fused_attn: 97.418 tok/s
- AutoGPTQ Triton + fused_attn + fused_mlp: 66.372 tok/s
Good Runpod 4090 server
HF fp16
- Max GPU usage: 97%
- Average over 20 runs: 50.741 tokens/s (0.020 secs per token)
Result for 20 runs: tok/s (s/tok): 48.727 (0.021s), 50.903 (0.020s), 50.871 (0.020s), 50.839 (0.020s), 50.825 (0.020s), 50.839 (0.020s), 50.826 (0.020s), 50.829 (0.020s), 50.825 (0.020s), 50.839 (0.020s), 50.828 (0.020s), 50.842 (0.020s), 50.832 (0.020s), 50.825 (0.020s), 50.839 (0.020s), 50.874 (0.020s), 50.856 (0.020s), 50.873 (0.020s), 50.870 (0.020s), 50.862 (0.020s)
AutoGPTQ CUDA, no fused_attn
- Max GPU usage: 80%
- Average over 20 runs: 76.588 tokens/s (0.013 secs per token)
Result for 20 runs: tok/s (s/tok): 72.243 (0.014s), 76.713 (0.013s), 76.764 (0.013s), 76.619 (0.013s), 76.821 (0.013s), 76.716 (0.013s), 76.642 (0.013s), 76.965 (0.013s), 77.080 (0.013s), 76.866 (0.013s), 76.944 (0.013s), 76.924 (0.013s), 76.846 (0.013s), 77.087 (0.013s), 76.949 (0.013s), 76.763 (0.013s), 76.875 (0.013s), 76.724 (0.013s), 76.589 (0.013s), 76.636 (0.013s)
AutoGPTQ CUDA, fused_attn
- Max GPU usage: 94%
- Average over 20 runs: 97.418 tokens/s (0.010 secs per token)
Result for 20 runs: tok/s (s/tok): 90.940 (0.011s), 97.465 (0.010s), 98.129 (0.010s), 98.030 (0.010s), 97.597 (0.010s), 97.444 (0.010s), 97.800 (0.010s), 97.787 (0.010s), 97.817 (0.010s), 97.649 (0.010s), 97.743 (0.010s), 97.742 (0.010s), 97.774 (0.010s), 97.687 (0.010s), 97.997 (0.010s), 98.047 (0.010s), 97.774 (0.010s), 97.613 (0.010s), 97.642 (0.010s), 97.683 (0.010s)
AutoGPTQ Triton, fused_attn + fused_mlp
- Max GPU usage: 100%
- Average over 20 runs: 66.372 tokens/s (0.015 secs per token)
Result for 20 runs: tok/s (s/tok): 61.101 (0.016s), 66.361 (0.015s), 66.779 (0.015s), 66.820 (0.015s), 66.675 (0.015s), 66.664 (0.015s), 66.741 (0.015s), 66.684 (0.015s), 66.782 (0.015s), 66.729 (0.015s), 66.597 (0.015s), 66.625 (0.015s), 66.532 (0.015s), 66.689 (0.015s), 66.614 (0.015s), 66.550 (0.015s), 66.615 (0.015s), 66.624 (0.015s), 66.588 (0.015s), 66.663 (0.015s)
HF 8bit bitsandbytes
- Max GPU usage: 100%
- Average over 20 runs: 20.760 tokens/s (0.048 secs per token)
Result for 20 runs: tok/s (s/tok): 20.127 (0.050s), 20.767 (0.048s), 20.750 (0.048s), 20.783 (0.048s), 21.025 (0.048s), 20.780 (0.048s), 20.868 (0.048s), 20.804 (0.048s), 20.760 (0.048s), 20.929 (0.048s), 20.613 (0.049s), 20.796 (0.048s), 20.742 (0.048s), 20.964 (0.048s), 20.820 (0.048s), 20.717 (0.048s), 20.819 (0.048s), 20.776 (0.048s), 20.818 (0.048s), 20.545 (0.049s)
I think the bad performance is the most common for people on their own systems too.
Also using textgen I get about 18 tokens/s with AutoGPTQ "old cuda" + fused_attn using WizardLM uncensored. 100% gpu usage.
Yeah it seems that way. I started out being really angry with Runpod for selling me bad systems. But actually it appears this is the norm. Which is really weird - it's like the majority of 4090s are only using ~33-50% of their potential, at least with pytorch language models.
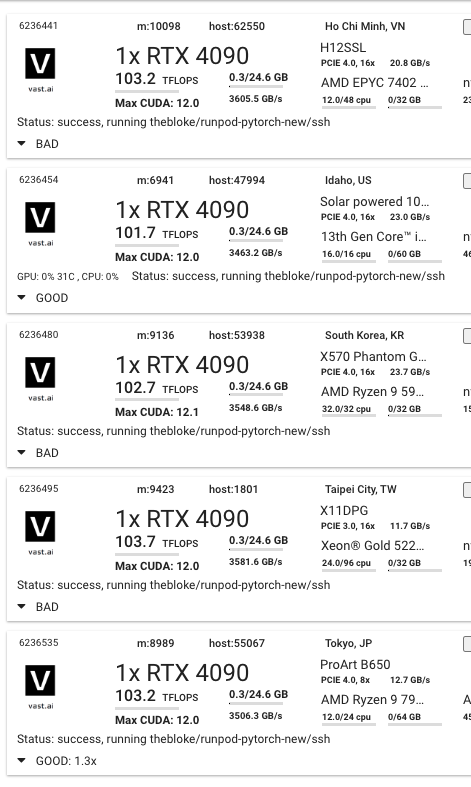
I did an audit of a variety of Vast.ai 4090 systems using the facebook-125m test script shown above. They did slightly better than with Runpod: I found two out of five that performed well. One got the same 1.0 timing, and the other got 1.3x which I'm counting as also good:
For further verification of my test results from last night, I ran the 'good' Runpod community server with text-gen-ui using ooba CUDA and --no-stream and got:
Output generated in 6.90 seconds (74.25 tokens/s, 512 tokens, context 41, seed 191644998)
Which is in line with my new expectations for CUDA without fused_attn
I'll keep digging to see if I can figure out what's different about the systems that run well.
Run your test in my WSL, 115 t/s (about 90 on windows(11) directly). My friend ran it on windows(10) with 1070 and got 139 t/s. cuda 11.8 for both.
I would say he has a "good" setup considering how much weaker 1070 should be. It can't be ram because he was running 2400MHz since his xmp was off. His cpu is 11700K. Completely fresh install of python and transformers/pytorch.
...I don't understand... and now I'm sad.
@TheBloke
For pretrained_model_dir = "facebook/opt-125m"
1.0 second is very very fast.
I get Run time: 2.509828567504883 on RTX 2080. This is a dedicated server, so I have a full control over it, i installed os and everything. And it works faster that Runpod for cases that I compared. T5 large works the same speed as on (probably bad) runpod RTX 3090, but really i tried multiple and I did not find any that works faster than the rtx 2080.
And here I am getting around 4.0s using facebook/opt-125m with RTX 3080. Something is really weird.
Yes,
I run ubuntu 18.04.
But my envinronment is easy to replicate in Anaconda:
conda create --name ai102
conda install pytorch=1.9.0 cudatoolkit=10.2 -c pytorch
I will try with cuda 11.1 or 11.8:
conda install pytorch cudatoolkit=11.1 -c pytorch -c nvidia
It can't be the package versions or cuda versions(maybe differences but not the major one) they have not correlated on bloke's testing. I have similar bad performance on the Windows side as well as WSL Ubuntu-22.04, so it's the exact same hardware and cuda. It is not due to WSL because it performs slightly better.
You are getting 4 seconds for opt-125m but for llama you get 115 tokens/second?
Has to be the same speed with the same hardware, the same OS and the same cuda and anaconda.
I am trying to install cuda 11.8 on rtx 2080, so I will test it anyways.
Oh, so it is 4x slower than TheBloke's best runpod server 4090? 3080 is only 2x slower than 4090.
Have no ideal, maybe a clean install would help. I doubt card can be bad. I just installed ubuntu 18.04 and then anaconda and then pytorch and that is all, just 3-4 steps.
You are right for cuda 11.8, it is the same speed around 2.5-2.6 seconds.
I mean the WSL is pretty much a clean install. Though the cuda comes from the Windows drivers. I have not clean installed those, but I think I did specifically install 11.8 recently. ~Also the gpu usage is near 100% which is different from those bad 4090s.~ Okay I think Windows is just showing it wrong, the actual clocks are low and usage reported by GPU-Z is closer to 30-40%.