pdf2docx
 pdf2docx copied to clipboard
pdf2docx copied to clipboard
After extract_tables some values have <NEST TABLE>
Hello. After application of function extract_tables in some lists I get values <NEST TABLE>. Is it possible to extract data from <NEST TABLE>? If necessary, I can give an example pdf file, where it is.
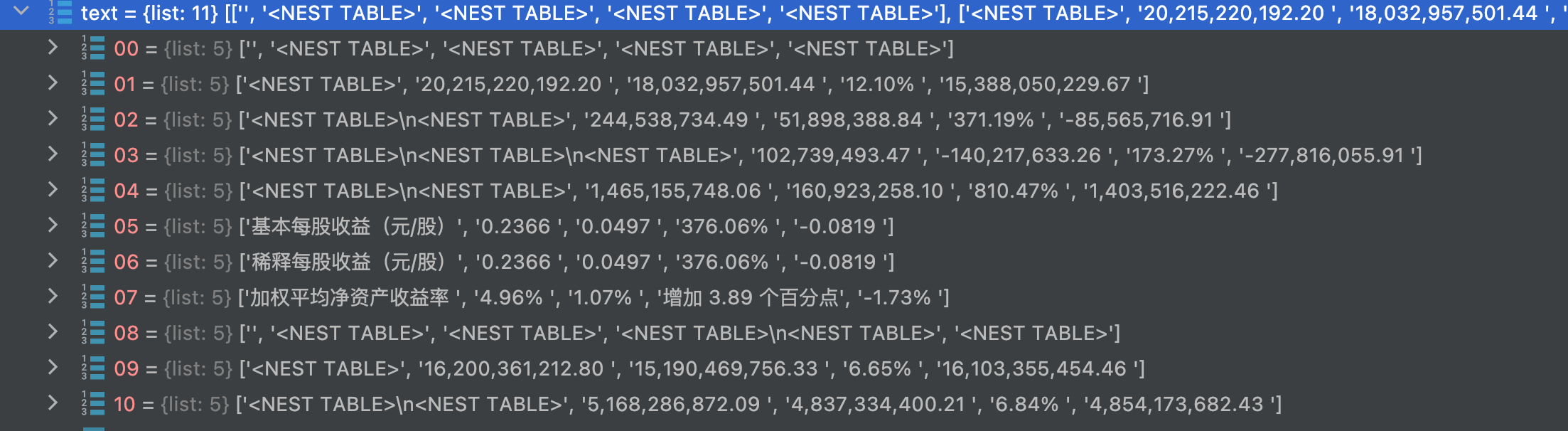
感谢这么好用的工具库 我也遇到同样的问题,表格的单元格内容有时会被解析成<NEST TABLE>, 我发现在表格背景色为灰色的时候很大概率会出现这种问题
pdf中的表格:

debug:
请问有什么建议,可以改进么?
Yes, I also noticed that one of the reasons why <NEST TABLE> appears when other colors are present in the table. I sometimes had a yellow color in my table because of a comment left in a pdf document, so if possible, I removed all such comments manually. Nevertheless, there are still documents where there is a <NEST TABLE> for another reason, I just logged that I did not extract everything from the table.
Is there any update on this issue?
I also encounter this when parsing a table with background color.
See the testing pdf file and the result screenshot below:
every even row's(with blue background) header will be parse as <NEST TABLE>
test.pdf
@icarusxxy This modification in table/Cell.py worked for me, though it's not perfect, but I'd rather have some text than <NEST TABLE>.
@property
def text(self):
'''Text contained in this cell.'''
if not self: return None
# NOTE: sub-table may exists in
text = []
for block in self.blocks:
if block.is_text_block:
text.append(block.text)
elif block.__class__.__name__ == "TableBlock":
text.append(''.join(flatten(block.text)))
else:
logging.warning(f"Found {block.__class__.__name__} - {block.text}")
text.append("<NEST TABLE>")
return '\n'.join(text)
Although, I eventually moved to using pdfplumber as it's working better for documents I am working with.