MuKEA
 MuKEA copied to clipboard
MuKEA copied to clipboard
MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering

按照batch_size=256、学习率=1e-4无法复现两个下游任务精度?请问如何设置相关参数以及如何训练?
作者您好,感谢您提出的这项非常有意义的工作。我利用2卡的3090GPU尝试复现MuKEA在OK-VQA上的准确率。首先在预训练阶段学习率设置为代码里的10(-4),在第14轮左右预训练的准确率可以达到27.2左右。然后我利用这个模型在okvqa上进行微调,学习率也为10(-4),epoch为200,但往往在100-150轮左右收敛,准确率最高可达到40左右,与论文里的准确率42.59差了2个点。然后我将预训练的学习率设置为论文里的10(-5),epoch设置为200,在第181轮时预训练的准确率可以达到30.34,我拿这个模型进行微调准确率可以达到41.57,和论文里的准确率还是差了1个点左右。我也尝试过调低微调阶段学习率,代码也没有修改过,指令输入无误,但总是和论文里的准确率差了一两个点。所以想问一下作者能不能release一下训练好的模型。也请作者能够解答一下我的困惑,祝工作科研顺利!
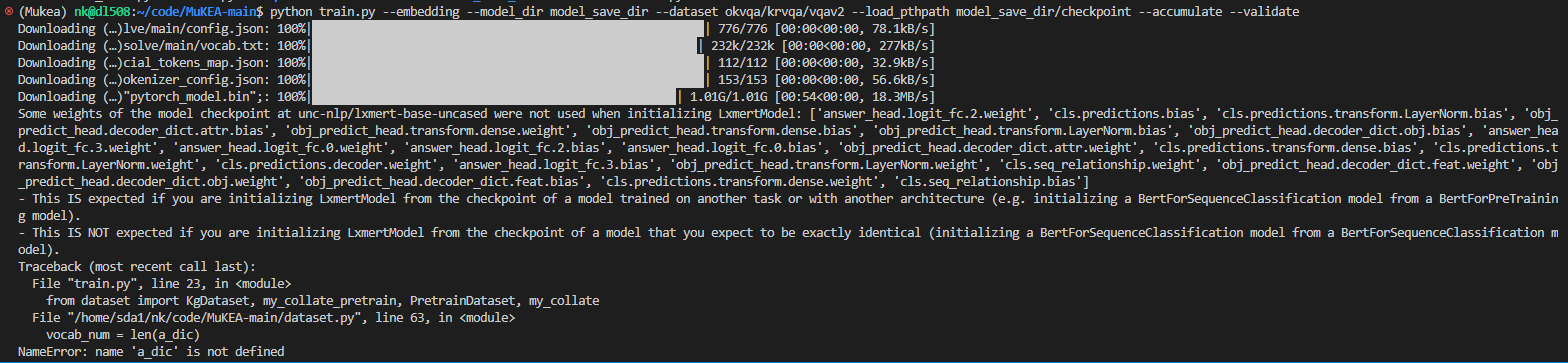 大佬您好,请问这是什么原因
大佬,你好,请问vqa_v2_pretrain文件下的prepare_img.py与tsv2feature_objects.py,两个py文件生成的vqa_img_feature_train.pickle,有什么区别啊?怎么样前后执行呢?麻烦了!
您好,我想咨询您一些关于在MuKEA中使用自定义数据集的问题: 我们的数据集不是通用领域(偏向于医学),格式类似VQA-RAD,导致您提供的pickle、tsv文件不能使用。我需要怎么做才能在我的数据集上使用?
运行命令为python train.py --embedding --model_dir model_save_dir --dataset okvqa --validate 报错:Some weights of the model checkpoint at unc-nlp/lxmert-base-uncased were not used when initializing LxmertModel: ['obj_predict_head.decoder_dict.attr.weight', 'cls.predictions.decoder.weight', 'cls.predictions.bias', 'obj_predict_head.decoder_dict.obj.weight', 'obj_predict_head.decoder_dict.attr.bias', 'answer_head.logit_fc.2.weight', 'answer_head.logit_fc.3.weight', 'obj_predict_head.decoder_dict.obj.bias',...
我贫穷到没有卡来跑预训练,但是很好奇MUKEA最后是怎么样,有没有跑好的mukea模型或者预训练好的,预训练实在是慢
Metadata
Owner
Metadata
MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering