rez
 rez copied to clipboard
rez copied to clipboard
determine branching and releasing strategy
Currently rez follows a simplistic branch/release process:
- Changes are merged into master via PR;
- Releases are performed from master;
- Releases follow semantic versioning.
Pros:
- It's easy to track down regressions, since one release typically pulls in a small number of updates (and often a single PR).
- It's simple
Cons:
- It doesn't guarantee stable releases. Many releases have known issues that later releases have fixed.
- Does not convey a sense of which release should be used to the community
Questions:
- What strategy would be better, and why?
- What does the ASWF recommend/prefer, or do they have anything to say about this? Should they?
- Is there existing tooling we can use to support our chosen strategy? (Specifically, to automate as much as possible, and to guarantee well structured changelog and corresponding github release notes).
- Changes are merged into master via PR;
- Releases are performed from master;
- Releases follow semantic versioning.
That's fine. It's quite common (if not the most common way of doing releases).
It doesn't guarantee stable releases. Many releases have known issues that later releases have fixed.
That's part of life. If there is too many regressions every time we do a change, then it means we need to work on the tests (either add new or improve existing ones)
Does not convey a sense of which release should be used to the community
To me, it comes down to the way releases are made right now. Each release is a "micro" release. Sometimes rez is released more than once a day and often with only a single PR merged in master. Speaking from experience, updating rez is "painful" because it's difficult to keep track of what changed because there is too many one PR releases.
Releasing less often and having releases with more PRs/changes would help to convey more information and help know, in some way, which version they should use. Micro releases can make sense inside a studio, but in open source it makes less sense because I'm sure most studios don't update rez as soon as there is a new release available.
What does the ASWF recommend/prefer, or do they have anything to say about this? Should they?
As far as I know, the ASWF doesn't have a preference. Release management is really a per project thing (in most cases) because projects are managed by different individuals and they are managed differently.
Is there existing tooling we can use to support our chosen strategy? (Specifically, to automate as much as possible, and to guarantee well structured changelog and corresponding github release notes).
There is a bunch of different tools to manage releases. One that comes to mind is GitHub has an auto-generator for the release notes nowadays. Also, automations can be built with GitHub Actions (for example, we could have a workflow to generate the changelog + tag + create the release in GitHub). Really, the sky is the limit.
Crossposting from Slack:
We do similar internally with a few additions:
- We tag branches (bug/name , feat/name, chore/name )
- We have a develop branch
- We merge PRs into develop
- Once we want to release we merge to main and tag
- Develop SHOULD always be kept usable, main is guaranteed (well there is no guarantee of course, but that's the goal)
This has some advantages:
- It's more reliable for releases to be stable as you mentioned (though that of course also depends on the level of actual testing
- It's helpful if you need to combine multiple PRs for something to work (or if you would break something if you don't combine PRs)
- It makes a clear distinction between "Here we work" and "Here we release"
- It gives an easy way to treat PRs differently in CI if that is something we want
If this is worth the overhead i don't know. Depends also on how many people contribute and how many people maintain I guess. Also +1 for JC's comment in regards to "micro" releases.
I am a huge fan of semantic commit / branch naming, and allowing that semantic naming to trickle downward as helpful information. i.e, if any of the merges since the last release contain a "feat/" branchname or commit name, automatically ensure that the next release is also a feature-semver-bump, and/or ensure proper formatting of something makes it into the changelog.
At the very least, a specific list of chosen tokens like fix, feature, docs, style, refactor, test, etc, would be great.
I also hate clicking on the "branches" dropdown on the rez repo because it has many different styles of branch naming, and we don't delete branches after being merged. I think we're due for a spring cleaning.
I also hate clicking on the "branches" dropdown on the rez repo because it has many different styles of branch naming, and we don't delete branches after being merged.
That can be fixed by enabling auto-deletion of branches on merge: https://docs.github.com/en/repositories/configuring-branches-and-merges-in-your-repository/configuring-pull-request-merges/managing-the-automatic-deletion-of-branches.
I'm in favor of the git-flow-named branches, and I think @JeanChristopheMorinPerso has a point about releasing less-frequently-with-more-changes.
This also gives us an opportunity to change the primary origin branch to main instead of master to have some more inclusive language.
Releasing less often and having releases with more PRs/changes would help to convey more information and help know, in some way, which version they should use. Micro releases can make sense inside a studio, but in open source it makes less sense because I'm sure most studios don't update rez as soon as there is a new release available.
Can we talk about this more please? Having smaller releases doesn't prevent anyone from say, updating Rez to the latest when they're ready to do so. After all, they'd do it in any case, regardless of how many tags happen to lie in-between. However if there's less releases, when they're ready to make a move, there'll be many more merge conflicts to deal with versus smaller releases. That's bitten us in the past. "We can't update to the latest Rez yet because there's a bunch of merge conflicts we need to QA and test". This has prevented much desired features from making it to the user floor. Larger releases exasperate this problem.
Speaking from experience, updating rez is "painful" because it's difficult to keep track of what changed because there is too many one PR releases.
It will be worse if they're all between 2 tagged releases. With separate tags, 2.100.0, 2.101.0, 2.102.0, etc, you can do git diff 2.100.0...2.105.0 to view the full thing or git diff 2.102.0...2.103.0 to view each feature's change incrementally. If there's only one, uber tag containing all 5 releases code, then you're stuck with just git diff 2.100.0...2.101.0. And the diff will likely contain multiple unrelated feature's code all at once that you'd have to guess / reason through.
I would much rather update from an older Rez to a later, non-latest (of those 5) Rez releases than delay updating because there's too many merge conflicts between my fork and the latest branch to be tackled all at once. if you have more incremental tags / releases, you allow users that option. But if the releases are grouped, you don't have any choice.
Is there any benefit to considering separate stable-vs-unstable release streams? (Personally, I'm in the prefer-small-releases-camp, but I'm suggesting ideas that accommodate worries from the larger-releases-camp)
There are different aspects and as always advantages and disadvantages. While it might be easier to do a git diff evaluation it is a whole lot more hassle to just read release notes. One of the examples you gave, going from 2.100.0 to latest involves 3 pages of releases and release notes where most of the space is redundant information (like the download links etc.). I recently did that and usually i read release notes rather than code. I usually also just use a release and deploy that and there are no merge conflicts. Do you have that because you also maintain internal changes that you need to combine with official releases? And if so is that because you lack fixes or features? (I think it would be desirable to try and enable everyone to just use of the shelf releases. For one it is less hassle for the affected people and it also helps with support as supporting code we don't know is tricky at times).
My take is, that the difference is typically the same code wise but i find it more hassle to just read through changes and understand implications. In practice i never released every version - as mentioned before there might be multiple a day and i typically release every few weeks rather than multiple times a day - so i do a big upgrade anyways. It's just harder to tell what exactly is happening unless i want to look at code for individual features. You still get to check individual commits that are also associated with the issues (in the future hopefully ;) )
Another aspect is that it can be hard to tell the current state as in "will there be more short term releases that i should wait for? Or ss the current release the end of the current set of releases?"
One of the examples you gave, going from 2.100.0 to latest involves 3 pages of releases
The release notes is fine for getting an overview but without reading and auditing a change. But I would not advocate for any new Rez upgrade to an artist floor without reading the source code changes to know exactly what it's doing. The alternative that you're suggesting, what I understand from your reply, is you'd prefer to collapse all of these into a single release or just less releases. It'd still be basically the same amount of reading, just now it's in one diff that we cannot separate anymore since it's one release. Seems like a demerit to me, overall.
Unrelated side note, for viewing diffs more easily, I use exclude wildcards help for the files that I know aren't as important (e.g. benchmark files).
Do you have that because you also maintain internal changes that you need to combine with official releases? And if so is that because you lack fixes or features?
Yes and yes. We / I wanted those changes in the main Rez but sometimes issues / PRs may take longer than production is willing to wait. It ends up going in the fork. And sometimes we need a feature that isn't well received in the open source community (which is fine, of course). In those cases forking is the only option.
You still get to check individual commits that are also associated with the issues (in the future hopefully ;) )
If Rez adopts a "all PRs must be rebased and squashed prior to merge" policy, which I think you can actually set directly in the GitHub repo settings, commits can still be WIP, formatting / newline changes, pylint, "fixed unittest", etc. But if we have that guarantee that each commit is clean and contains exactly one bug fix / one feature (one PR's content), then I can see that being viable.
Btw I'm not necessarily advocating for rebase + squash as a requirement. I'm just saying, in the absence of that, diffing WIP commits in a larger release is more frustrating than diffing release tags that you know are atomic.
Our setup makes it easy to mix and match and roll back and forth (we tried to adopt a similar strategy for our Rez deployment than Rez does: Provide all versions supported and make it easy to choose and switch). So i am not auditing every code change. I treat Rez similar to other software and libraries:
- I check the changelog for relevant changes and possible deal breakers
- If i find none i deploy to staging and have testers test in a production like environment
- If testers approve we deploy to production
I would like to add another comment to clarify in regards to the "amount of reading". Here is a shot from the top of the releases page. This is on 1440p:
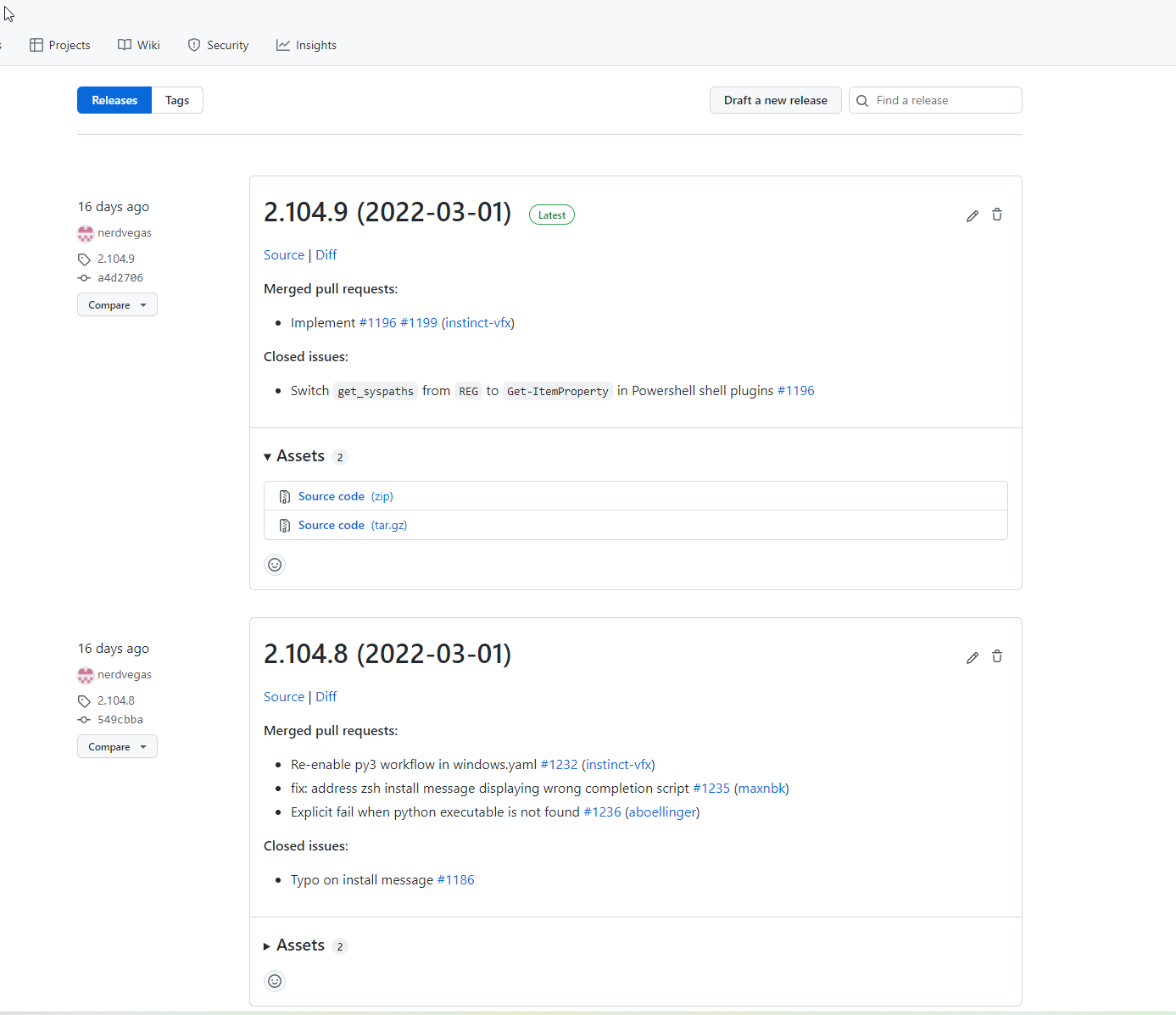
I get 2 releases per screen. And the relevant information is this:
- Implement 1196 1199 (instinct-vfx)
- Re-enable py3 workflow in windows.yaml 1232 (instinct-vfx)
- fix: address zsh install message displaying wrong completion script 1235 (maxnbk)
- Explicit fail when python executable is not found 1236 (aboellinger)
I get around 4-5 pages per screen and 3 pages to reach 2.100.0. That's really hard to just read and get a quick overview of changes.
Just to make that clear: I am not a dire advocate of this, and i can live with what we have now too, i am just pointing out why i would slightly prefer somewhat bigger releases. In the past releases were usually in groups when Allan was spending time on Rez. That typically results in 2-3 releases on that day. So i am not saying only release once a month and make releases huge, but i would see benefit in grouping these 2-3 releases that are released the same day anyways if that makes sense.
(As a side note, documenting release notes in a dedicated page in the docs or alike might also help mitigate this i guess)
Sorry for the wall of text... But I felt there was a lot of ground to cover.
Colin: It will be worse if they're all between 2 tagged releases. With separate tags, 2.100.0, 2.101.0, 2.102.0, etc, you can do git diff 2.100.0...2.105.0 to view the full thing or git diff 2.102.0...2.103.0 to view each feature's change incrementally. If there's only one, uber tag containing all 5 releases code, then you're stuck with just git diff 2.100.0...2.101.0. And the diff will likely contain multiple unrelated feature's code all at once that you'd have to guess / reason through.
That's what commits are for. If there is a release that contains multiple changes, normally the release notes will contain links to PRs and it's also quite easy to inspect the commits between two tags.
As for comments about forks that are hard to maintain because of conflicts, I don't think there is much we can do. Anyone forking a repo and doing changes to that fork should know that keeping the fork up to date will require time, efforts and merge conflict resolution skills. I don't think micro releases help in any way with having less conflicts.
Colin: Having smaller releases doesn't prevent anyone from say, updating Rez to the latest when they're ready to do so.
Indeed, and my suggestion for having less frequent and bigger releases isn't about that. It was slightly related since I talked about release notes, but @instinct-vfx already covered the pain points around these and I don't have more things to add on that than what he said.
Colin: The alternative that you're suggesting, what I understand from your reply, is you'd prefer to collapse all of these into a single release or just less releases. It'd still be basically the same amount of reading, just now it's in one diff that we cannot separate anymore since it's one release.
(saying "just now it's in one diff that we cannot separate anymore since it's one release" is incorrect because there would still be at least one commit per merged PR)
If we look at it that way, yes there isn't "any" big benefit. At the end of the day, if there is for example 10 PRs, no matter if they are split between 1 or 10 releases, it's the same amount of code. But I don't think it should be seen with that perspective. In the issue description, @nerdvegas asks questions and lists pros and cons. My suggestion of moving away from micro releases is to try answering how we could solve the con "Does not convey a sense of which release should be used to the community".
Let me try to explain things differently in hope that it will highlight more clearly my view of how things can be improved. I'll try to explain how we could better help our community to choose which version to pick and also how to give a better sense of stability (or in other words, how we can increase the trust our users have when it comes to updating Rez).
Right now, Rez releases feel like rolling/nightly releases because they contain really small set of changes and can happen multiple times a day. The condition for a release to happen is to have at least one PR merged (no matter what kind of change it is. There's been releases just for extremely small changes in the past that wasn't affecting the behaviour of Rez, for example a change in a test only). Hence the reason why I'm making a parallel with rolling/nightly releases.
Slowing the release cycle and having bigger releases has multiple benefits, some of which are:
- Reduction of the noise generated by multiple micro releases in a short amount of time. Note the use of the word noise which I carefully chose to help demonstrate my point. This leads to the next point.
- Reducing the release cadence would help improve the impression of stability and would potentially give more confidence in the project to some users. That's a quite personal opinion, but I tend to "trust" a little bit less projects which release too often because I can't keep up with the release cadence and I endup missing some crucial information. Which leads to the next point.
- We would be able to better communicate the changes since there is more possibilities that they would be grouped. So instead of saying A was released in version X, B in version Y and C in version Z, we could say A, B and C where released in X. This applies to both users and contributors/maintainers. I'm pretty sure that almost nobody can say in which versions a specific thing was introduced or fixed without looking at the release notes because of the sheer amount of releases that makes release versions almost meaning less.
- Give meaning to versions. Right now the only meaning that the versions convey is semantic information.
- We would be able to have release announcements, which would tremendously help our community.
- Remove some work on the maintainer shoulders (maintainers with an "s" once TSC is formed)
And with more time I could probably find more benefits and I could also explain more in-depth some of them.
maxnbk: Is there any benefit to considering separate stable-vs-unstable release streams?
We could have dev/unstable releases, but the how do we determine that something if a version needs to be a dev or an official release? Also I don't think anyone would install dev releases (because the sole purpose of tagging a release as dev is to tell everyone to not use it in production) which means we would have the same result as having bigger releases.
Again, sorry for the wall of text.
@JeanChristopheMorinPerso
I read through the whole post however I'm mostly going to reply the last 60%, because I think there's important points you've made and I want to clarify those.
(or in other words, how we can increase the trust our users have when it comes to updating Rez)...Reducing the release cadence would help improve the impression of stability
In general, when I talk to artists and stakeholders about assets or code features, they trust my word when I say something is fixed, works, "is ready", etc.
The reason I read through Rez's diff is not because I don't trust its changes but because Rez permeates through the entire pipeline, touching every user, and even runs on the farm with elevated permissions. It's unique compared to other Open Source projects in that way. Having larger releases will not make this responsibility go away and will make maintaining that level of care for our users harder during upgrades.
I'm pretty sure that almost nobody can say in which versions a specific thing was introduced or fixed without looking at the release notes
I agree and I'd like to expand that by saying if we used git tags Rez more effectively, we could still achieve the same clarity without requiring to group releases. git tag -n is pretty great and I wish Rez's tags summarized each change better. They're mostly "changelog update" etc.
Right now, Rez releases feel like rolling/nightly releases ... Slowing the release cycle and having bigger releases has multiple benefits
I realize that what I'm about to say may come off poorly and I apologize in advance. Rez has been propped up by Allan and as a community effort. For many, entirely in their own free time. However I cannot help but point this out. Does slowing Rez's release cycle make sense for Rez? Is everyone happy enough with Rez's current set of features that we're okay with waiting longer for releases?
There's currently 34 open PRs, and 63 open enhancement issues. Many dating back several years. If we can do something to help Rez implement & merge those faster, I would like to seek out what that could be. The thought of slowing down, especially with the recent momentum following ASWF adoption, IMO would be a wasted opportunity.
Our current branch structure suits Rez well, I think. We just need to be more effective with the processes that are already in place.
I realize that what I'm about to say may come off poorly and I apologize in advance. Rez has been propped up by Allan and as a community effort. For many, entirely in their own free time. However I cannot help but point this out. Does slowing Rez's release cycle make sense for Rez? Is everyone happy enough with Rez's current set of features that we're okay with waiting longer for releases?
Just a quick comment here: I don't think slowing down the release cadence has a direct relation to the speed of development. My take would be that the development of features is stable and all we are deciding is how often we package a release. Depending on the overhead the release process has it might even be less effort to release less often.
Without being overly verbose, I prefer @ColinKennedy 's take, but I do sympathize that it is currently difficult to figure out what happened in what release.
That said, my use-case-scenario is usually much more of a "I just want to know if this particular feature or bugfix is in this particular version or not", and I have much less of a problem finding out that information with basic git skills.
If I was going to suggest any change to the rez release schedule, I would propose something like this: merging/releasing only bugfix PRs as one large batch, once every-approximate-fortnight, and only merging/releasing only features as one large batch, every-other-fortnight (if any features are ready to be merged). It wouldn't really slow down the development/merge/release cycle, but it would organize the fact that "after we release features, we release bug fixes to those features", kind-of, and would have the tendency to group fixes with other fixes, features with other features, making for slightly easier release/changelog review, while not overly impacting how long it takes for a PR to reach release status.
As @instinct-vfx said, slowing down the release cadence doesn't mean slowing down on development. And I will point out that if someone wants a feature badly, then that person can communicate that to the future TBD TSC members.
And @maxnbk, I was also imagining something like you described (though I'm not sure if you imply that releases would either contain features or bugfixes, but not both... Anyway, that's details.).
Righto, my thoughts in quasi random order:
To @maxnbk 's idea of releasing every other fortnight (btw "every other" is an Americanism that left me confused for longer than I care to admit!). I don't mind it, but the problem with this is that currently, I'm the sole maintainer (in reality), and it's more of a case of get-it-done-when-I-can. So until there are maintainers plural, a more scheduled release approach will not work. I'd suggest we leave discussion around scheduled releases until if/when that becomes practically possible.
I generally agree with points raised in this thread. I like small releases personally, because it makes tracking down what happened in what version very straightforward. However, I also agree that larger and less frequent releases have their advantages. Specifically I do think larger releases help in terms of general communication and impression of stability. Also, what hasn't been mentioned yet is that it should result in more studios running a common version of rez at any given time.
Here's what I don't like about larger releases though:
- if a studio wants a fix sooner than the next release, they'll need to either pull from master or pull a specific commit. Now we're in a situation where it's much harder to describe "where" a studio was when their version of rez broke. Rather than saying, "this feature stopped working in 2.105.4", we say, "it stopped working in the master I pulled a few weeks ago", or, "it stopped working at this commit hash."
- If a studio uses a version of rez based on a commit, we need to be careful about commits and ensure that a commit isn't actually a partial implementation of a fix. Ideally that should never be the case, but there's no assurance, and this is just something else to worry about. Currently we don't have this worry because people pull versions, not commits.
I wonder then, what we might be able to do in order to have the best of both worlds. What if we had two kinds of releases? We could follow the current release method, but let's call these versions (eg) 2.104.5.beta. Then, in the TSC meetings, and at regular intervals (once a month perhaps), we agree on which version most people are/should be using. We then do a "production" release for this version (eg "2.105.1"). This release doesn't add anything new, it just tags the repo at the appropriate commit (which would be the latest beta < the production version), and generates a set of release notes that collates all the changes since the last production release.
So it'd look something like this:
# in commit order
* (<- master)
* 2.108.2.beta
* 2.108.1.beta
* 2.108.0.beta
* 2.107.1 <- production release
* 2.107.0.beta
* 2.106.1.beta
* 2.106.0.beta
* 2.105.1 <- production release
* 2.105.0.beta
* ...
Here the 2.107.1 release would:
- have release notes that collate all changes since 2.105.1;
- have "source diff" link that shows diff wrt 2.105.1
Of course, the releases would not appear in github in this order (releases are shown in order of creation date), they might appear like so:
# in date order
* 2.107.1
* 2.108.2.beta
* 2.108.1.beta
* 2.108.0.beta
* 2.105.1
* 2.107.0.beta
* 2.106.1.beta
* 2.106.0.beta
* 2.105.0.beta
I'm ok with this though, it conveys that betas are the latest releases, and non-beta are the "most recent good and stable" version.
The only thing that's a bit odd is how the production releases are all a .1 patch - that's required because otherwise 2.105.0.beta > 2.105.0 (in rez versioning terms).
Thoughts?
Hm. While this would mostly adress this specific issue it would make things worse in regards to perceived stability and communication for everything except non-beta tagged releases. I am also rather strongly against using the specific term beta in this context. This should only be used if there is an actual difference. Typically i would expect non beta releases to be actually tested or pass certain criteria to be labled production. If the only difference is an arbitrary TSC decision that seems wrong to me.
I just had a different thought (as i am not generally opposing the idea of the approach just the way it would be implemented). Tags and Releases are a different concept in Github. How about having tags for all in between releases and releases for actual releases. A common naming scheme have often seen is having a build number. So it could be:
2.105.0 <- release 2.105.0.001 <- Tag (created upon merging a PR) 2.105.0.002 <- Tag (created upon merging a PR) 2.105.0.003 <- Tag (created upon merging a PR) 2.105.1 <- release 2.105.1.001 <- Tag (created upon merging a PR) 2.105.1.002 <- Tag (created upon merging a PR) 2.105.1.003 <- Tag (created upon merging a PR) 2.106.1 <- release 2.106.1.001 <- Tag (created upon merging a PR) 2.106.1.002 <- Tag (created upon merging a PR) 2.106.1.003 <- Tag (created upon merging a PR)
I have not fully thought this through, i just had that idea while reading your post.
This way you get tags for everything, but releases with changelog for every n-th tag as an actual release. We can reference a breakpoint by tag and still get only releases in the releases page. It would also make the order strictly incremental as they would be created (and displayed) in order (of PR merge).
I dunno, how are you going to get the production testing done on 2.105.0 to be able to make it a proper release in the first place? I suspect people won't install tags, they'll just install the previous release, and the tags will just become a notional concept that don't really have any practical use. Why would you install a tag when you don't really know what it is?
I don't think agreeing on a prod release in the TSC meeting would be arbitrary. It would be based on feedback over the last month about what versions studios are using and how stable they're reporting them to be. Now, there's a similar argument to what I just mentioned though - how many studios are even going to be using these beta/whatever releases, would they not just tend to use the last prod release? I would say to that that, again, an actual release represents a lower barrier of entry to use than a tag. An actual release has release notes and can simply be downloaded directly from github. Those seem like minor things but I suspect they'll matter in terms of what gets used.
The trick here, I think, is to have easy access to smaller releases, so that we get enough real-world testing in to then be able to make larger, extra stable releases at semi-defined intervals.
On Sat, Mar 19, 2022 at 9:18 AM Thorsten Kaufmann @.***> wrote:
Hm. While this would mostly adress this specific issue it would make things worse in regards to perceived stability and communication for everything except non-beta tagged releases. I am also rather strongly against using the specific term beta in this context. This should only be used if there is an actual difference. Typically i would expect non beta releases to be actually tested or pass certain criteria to be labled production. If the only difference is an arbitrary TSC decision that seems wrong to me.
I just had a different thought (as i am not generally opposing the idea of the approach just the way it would be implemented). Tags and Releases are a different concept in Github. How about having tags for all in between releases and releases for actual releases. A common naming scheme have often seen is having a build number. So it could be:
2.105.0 <- release 2.105.0.001 <- Tag (created upon merging a PR) 2.105.0.002 <- Tag (created upon merging a PR) 2.105.0.003 <- Tag (created upon merging a PR) 2.105.1 <- release 2.105.1.001 <- Tag (created upon merging a PR) 2.105.1.002 <- Tag (created upon merging a PR) 2.105.1.003 <- Tag (created upon merging a PR) 2.106.1 <- release 2.106.1.001 <- Tag (created upon merging a PR) 2.106.1.002 <- Tag (created upon merging a PR) 2.106.1.003 <- Tag (created upon merging a PR)
I have not fully thought this through, i just had that idea while reading your post.
This way you get tags for everything, but releases with changelog for every n-th tag as an actual release. We can reference a breakpoint by tag and still get only releases in the releases page.
— Reply to this email directly, view it on GitHub https://github.com/nerdvegas/rez/issues/1247#issuecomment-1072860441, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAMOUSUFR6EGXUR5XRPIUZTVAT6KZANCNFSM5Q2MBEEA . Triage notifications on the go with GitHub Mobile for iOS https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675 or Android https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub.
You are receiving this because you were mentioned.Message ID: @.***>
Hm. I am not sure actually. I can see how people might not install tags. Will they be more likely to install releases tagged beta though? And if they don't then we will not get a lot of production feedback and testing of beta releases would not really make non-beta releases a whole lot better, no?
I am really not fond of the term "beta" there and i also really don't like the idea of releases not being in order (though that might just be ocd)
I'm not sold on beta either tbh, I was just using that to illustrate the concept, to be clear.
Micro tagging or micro releasing are pretty much the same IMO and they have the same problems. And micro releasing + creating release bundles is probably worst then micro releases alone. Not only would it add extra work, it would also require extra mental overhead and load just to process what's going on.
I think that if a user wants a fix really badly, he will probably fork the repo to fix the issue, create a PR, etc. That means they can install the fix from their fork and then go back to the official releases once the fix is officially released. That's the beauty of open sourced code. Also, any user that doesn't use an official release shouldn't be "supported". We can't garantee that everything will work if they picked a specific commit instead of a known version. Or If someone has a critical bug, that person can always revert to the previous version that worked for them. Additionally, I tend to think that most users of open source projects don't go as far as using non release versions.
As for "If a studio uses a version of rez based on a commit, we need to be careful about commits and ensure that a commit isn't actually a partial implementation of a fix.", as my previous reply said, it should be the other way around. If someone wants to pick a specific commit to use on their prod, it's up to them to make sure what they chose works.
Using GitHub releases is an interesting idea. Are releases always associated with a tag this way you can automate downloads just using Git clone, tag checkout, and install.py? or is release data only available via the GitHub API and Web UI?
Another point that I don't think has been made for larger, more deliberate releases is that it would help create some uniformity between user installs. Right now, you could go to a dozen different sites and there is a good chance that a different version of rez is in production at each site. From the standpoint of developing and sharing an ecosystem of other tools or services around rez, and even for rez itself, it creates a much larger maintenance burden.
As far as a specific release cadence, it would ideally be closely aligned with the update cadence for users. How often can we reasonably expect users to install new versions of rez, test them, and put them into production? They likely aren't going to do that every week, right? Monthly is probably about the highest frequency you could reasonably expect I imagine. The cadence would just be for planned minor releases. It would still allow you to push out patch releases for critical bugs or regressions outside of the normal cadence.
As far as automating changelog and release notes, that would likely be easier if rez adopted some form of Conventional Commits, so that commits could be reliably parsed in a structured way.