cobrix
 cobrix copied to clipboard
cobrix copied to clipboard
Optimization of input file split
Background
I have fixed length of 200 bytes file with 100 multi segments present in copybook with 2k columns. It is taking almost 12 hours for just 1gb of file.
Feature
Can you add feature for input file split in mb for all file formats, currently it is working for record format =VB, where input_split_size_mb
I tried to adjust block size in spark code, but cobrix taking default cluster block size.
Proposed Solution [Optional]
Solution Ideas
- Allow this input_split_size_mb for all file formats
- How to take custom block size specified in spark configuration. Ex:spark.conf.set(“dfs.blocksize”,”32m”)
Hi what's your code snippet?
Cobrix should be more efficient for F format than V or VB formats. Not sure why you are having performance issues.
Hi @yruslan ,
I am using cobrix 2.6.3 version and please see cobrix options
Please let me know, how to optimize job?
You can try:
- Removing the 'segment_id_level0' option just to see if there are any performance improvements.
- When the number of columns is so big, Spark can spend a lot of time creating the execution plan. You can try remove further processing (flattenning etc) for now to see if it improves the performance.
The idea of the above exercises is to understand what impacts the performance - data decoding or other transformations.
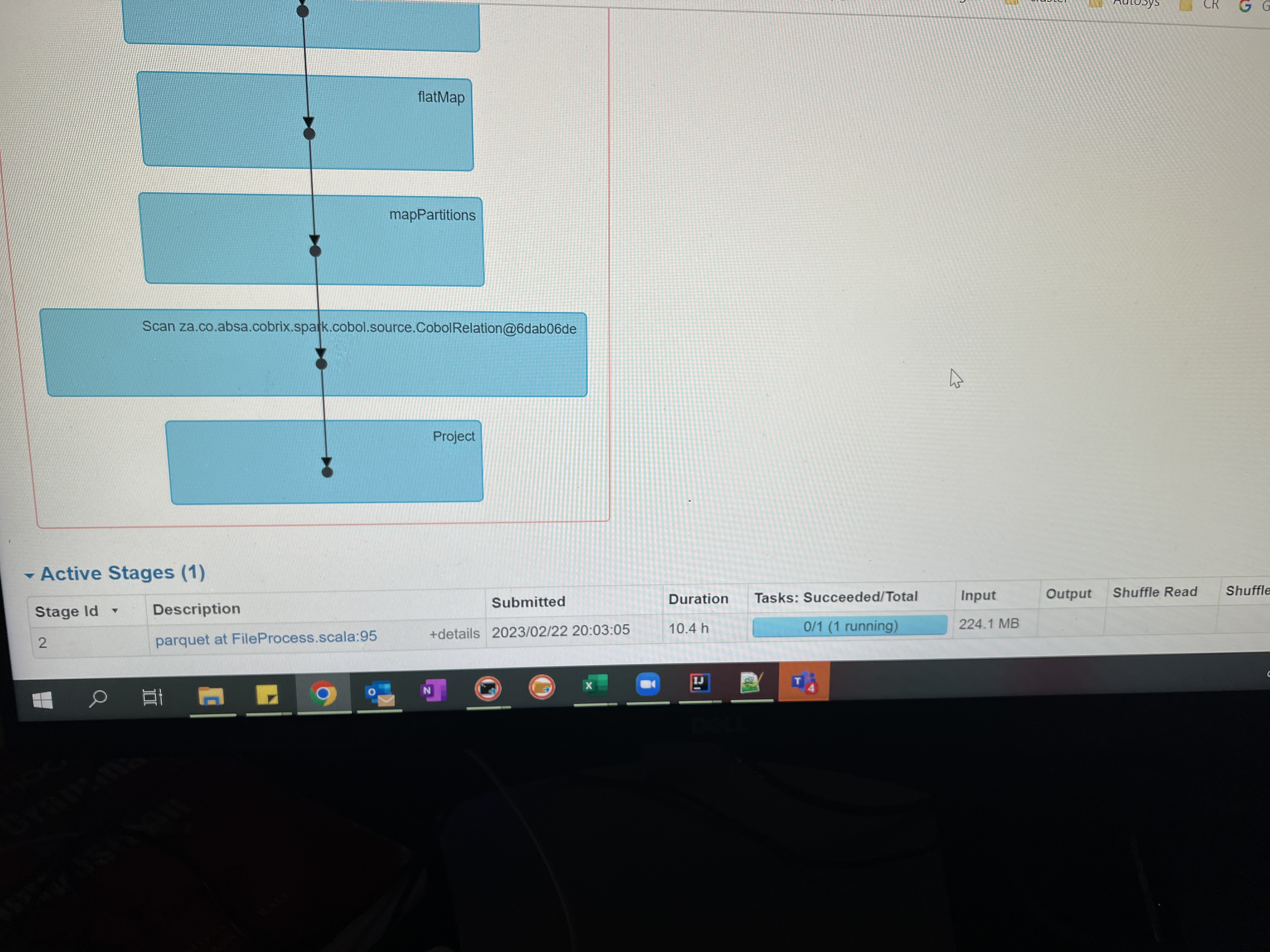
The screenshot shows only 8 segment mappings. Are there 8 segments or 100?
Otherwise the code looks good.
Hi @yruslan
Due to security reasons, I can’t publish copybook here, but file 200 bytes fixed length with 100 multi segments, I grouped to 8 segments, under 8 segments secondary split happens.