Gradient clipping in train tab
Providing gradient clipping to user. It's used to handle exploding gradient. I thought it might help for too-large learning rate in hypernetwork training, but it doesn't seem so. Using 0.0001 lr with 0.00001 norm produces different result from just using 0.00001 lr though, so there might be some way to use this. But for now, this is just exposing one of torch's feature with UI. This feature is for hypernetwork and textual embedding and supports learning rate syntax.

Here's 1-2-1 swish dropout at lr 0.0001 without gradient clipping (old screenshot):
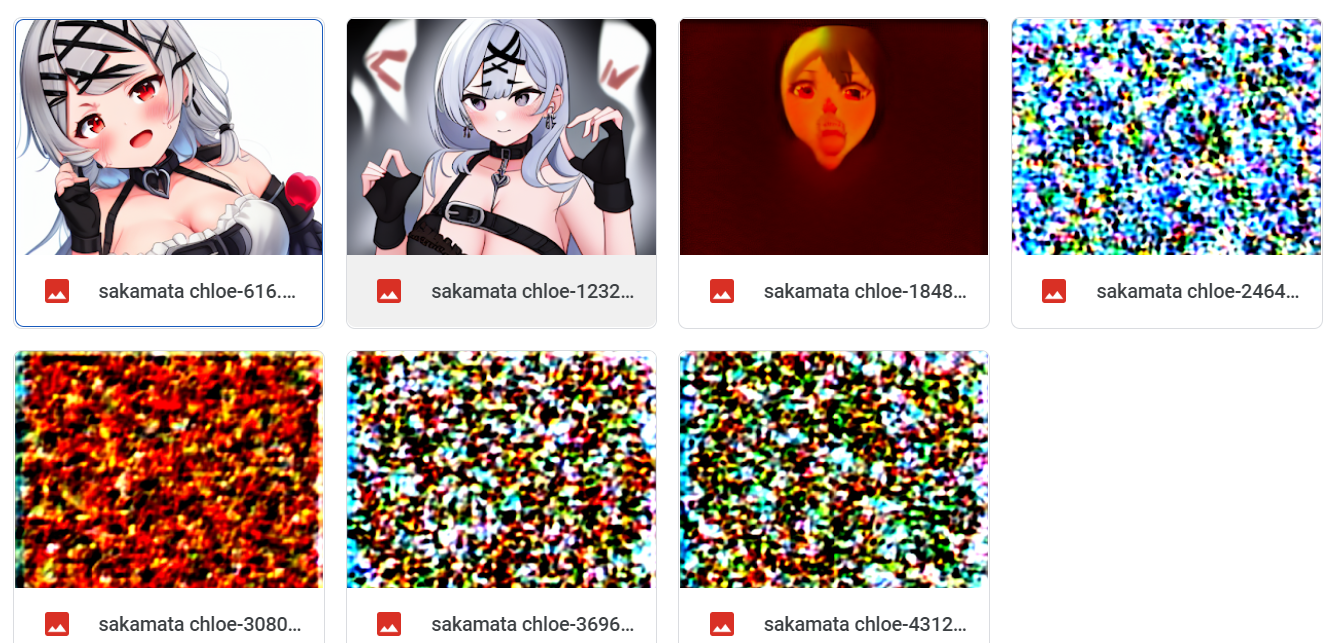
Here's 1-2-1 swish dropout at lr 0.0001 with norm clipping at 0.1:
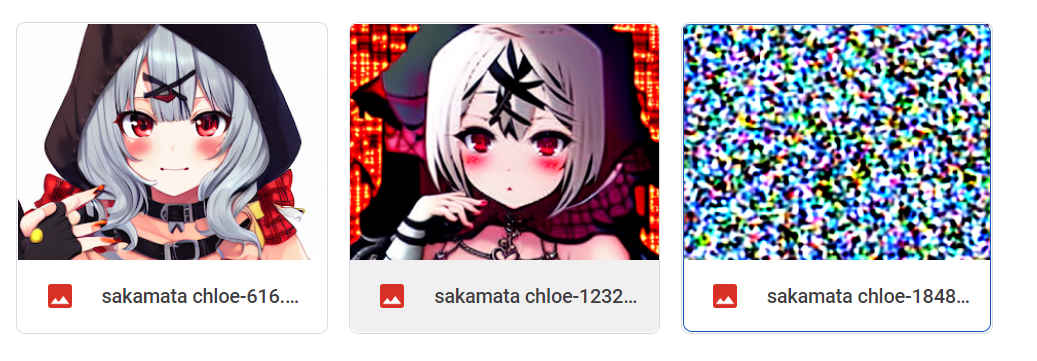
Here's 1-2-1 swish dropout at lr 0.0001 with norm clipping at 0.01:
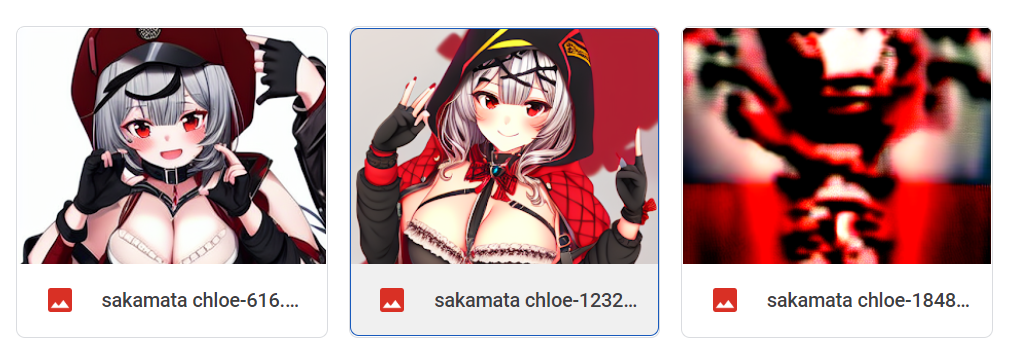
Here's 1-2-1 swish dropout at lr 0.0001 with norm clipping at 0.001:

Here's 1-2-1 swish dropout at lr 0.0001 with norm clipping at 0.0001 (same as lr):
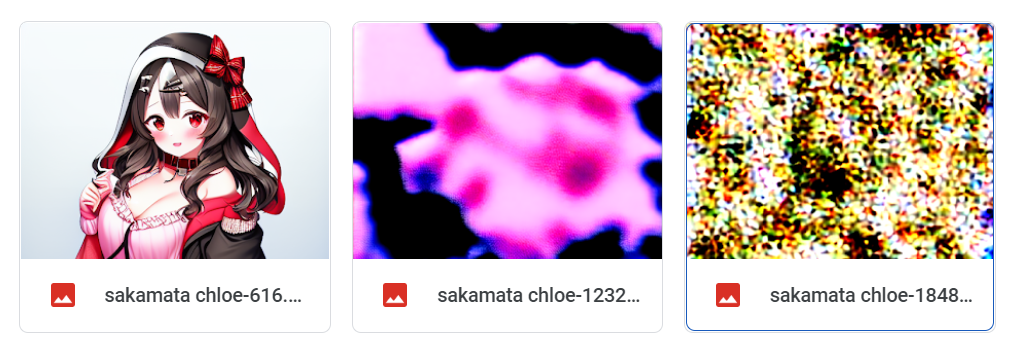
Here's 1-2-1 swish dropout at lr 0.0001 with norm clipping at **0.00001** (lower than lr):
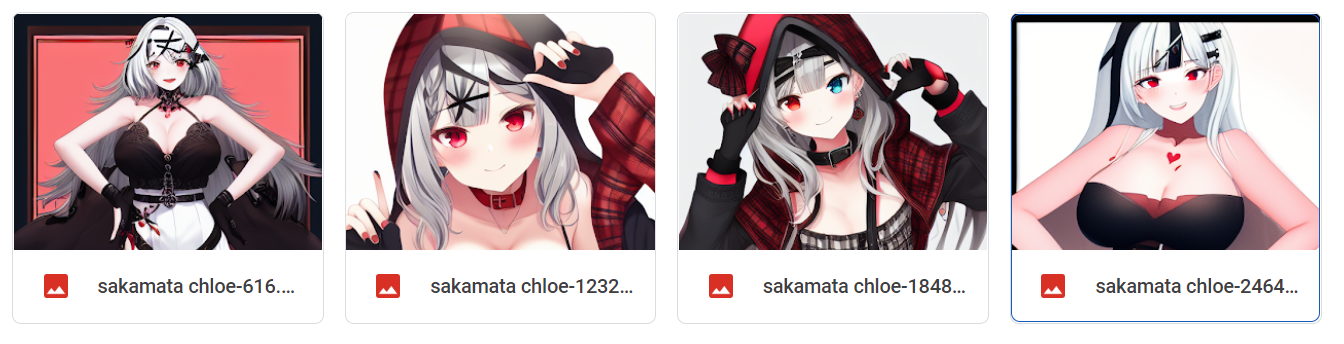
Here's 1-2-1 swish dropout at lr **0.00001** without norm clipping (lower lr than before):
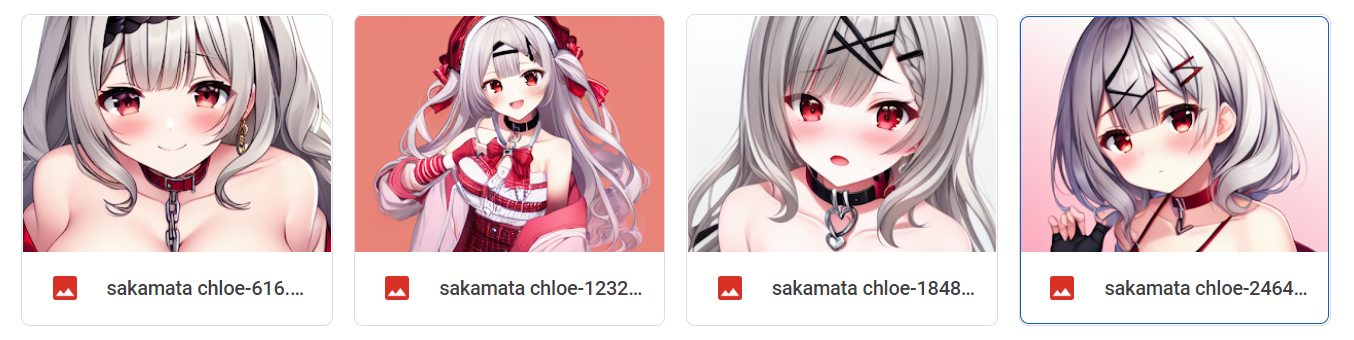
You won't typically suffer much from exploding gradients after the model is stable and it's just fine-tuning, unless the lr is absurdly large. I don't think it will change results by much
You won't typically suffer much from exploding gradients after the model is stable and it's just fine-tuning, unless the lr is absurdly large. I don't think it will change results by much
If I understand it correctly, hypernetwork fine-tuning is done by creating another model which will fine-tune the main model. The hypernetwork model itself is a new model thus unstable, and since its output would be the weight tuning, it's very sensitive thus the learning rate is suggested to be very low.
Still, the tests I did mostly shows that the clipping wasn't helpful. Probably there really wasn't any significant exploding gradient during training, but lr was still too large for it to converge or even made it diverge into noise instead. Well, with the noise being artificial and thus loss not being meaningful, it's hard to tell if it's converging without generating an image and check it manually, or using an actual evaluation metric.
How much more effective will the training be with textual embedding? Is it faster to reach the goal or is it able to bring out more detail and interpretation?
How much more effective will the training be with textual embedding? Is it faster to reach the goal or is it able to bring out more detail and interpretation?
It's a safeguard for exploding gradients. It won't improve training effectivity unless you're having that problem.
You can also use it to limit the training drift, by setting it very low around your learning rate, but idk how that will help. I did that in my 6th example (2nd to last). It worked? But it was still worse than actually reducing learning rate (last example), because my learning rate was indeed too high for hypernetwork and for my dataset (as pointed out by aria1th in the prior discussion).
If I understand it correctly, hypernetwork fine-tuning is done by creating another model which will fine-tune the main model. The hypernetwork model itself is a new model thus unstable, and since its output would be the weight tuning, it's very sensitive thus the learning rate is suggested to be very low.
You can read more about the hypernetwork in the blog (https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac), but don't consider them a new model, it's only a new module (in the Pytorch concept of module) for the existing model, which is already stable. With the very low learning rate, gradient explosion becomes even less probable to happen
You can read more about the hypernetwork in the blog (https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac), but don't consider them a new model, it's only a new module (in the Pytorch concept of module) for the existing model, which is already stable. With the very low learning rate, gradient explosion becomes even less probable to happen
I see. So it's different from the 2016 one. It's a shared weights applied to crossattention layers. So it really touches none of the main model weights.
Yes, with low learning rate, gradient explosion is unlikely to happen. I just thought maybe it's what prevents higher learning rate, but no. It can alter the learning though, by limiting it. So yeah this only exposes the feature for users to play with it. I won't insist for it to get merged, since even I have yet to find it useful.
Did you find something else out with your tests? Maybe some improvements?
Btw, to manage the logic to select the gradient clipping mode, you could simplify the code with something like this: https://github.com/victorca25/traiNNer/blob/12d006fd44ed304e4178839c53b1f3d95ca25dcb/codes/models/base_model.py#L774
I haven't experimented further. I've simplified it, if I get what you meant correctly.