Fixed proper dataset shuffling
Continuation of #3728
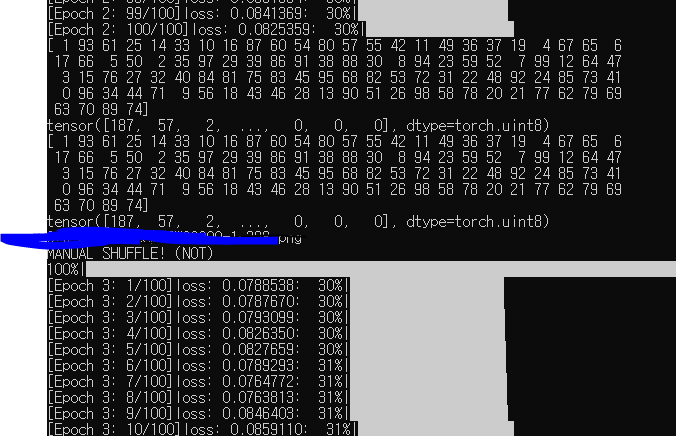 Turns out I wasn't hallucinating and torch.randperm was giving a fixed list as training continued. ([1, 93, ...]) This doesn't happen every time - I am suspecting that this is caused on full VRAM, or conflicting with multiprocess such as running image previews mid-training.
So I swapped the function with a numpy one and it's working smoothly, even working properly when torch.randperm fails to become random.
Turns out I wasn't hallucinating and torch.randperm was giving a fixed list as training continued. ([1, 93, ...]) This doesn't happen every time - I am suspecting that this is caused on full VRAM, or conflicting with multiprocess such as running image previews mid-training.
So I swapped the function with a numpy one and it's working smoothly, even working properly when torch.randperm fails to become random.
The commit message should be fixed - this fix also applies to hypernetworks.
do your image process cycle exactly matches with dataset length? also using fixed seed generation and settings? I agree that we need independent rng for shuffling, since its being fixed when we create image preview.
I found the error where dataset length and image generation were equal. But the random fail also happened when it was not equal. Weird stuff. Also used fixed seed and settings.
It seems to work, at least for me. I modified the code during training and after a thousand steps it generated more usable images. Thanks, and I hope it will be in the master as soon as possible.
Can you use new Random object from python random, with fixed seed generation, then permutate from it? We'll need to make reproducable results, i.e. fix seeds used for result to reproduce same result.
simply
from random import Random, randrange
# in __init__
self.seed = randrange(1<<32)
self.random = Random(self.seed) # initialize as None
# in shuffle
self.indexes = np.array(self.random.sample(range(self.dataset_length), self.dataset_length))
# add method to fix in future
def fix_seed(seed = None):
self.seed = seed if seed is not None else randrange(1<<32)
self.random = Random(self.seed)
This is more of a torch problem, not an algorithm change. I have seen the problem with 100 training images and saving image per 100 steps or 107 steps on a RTX 3070, with logging each step to csv. I don't think this can be reproduced with simple random objects.
No, I mean it would be better to have random information, and unique rng that is only used for dataset shuffling. In this way, we can reproduce training in same dataset + same rate + same setup (well not with dropout...), which might help research in future.
Can't think of a way to make an endless random permutation with seeds, so if you happen to make one, you'll have to set a fixed amount of training steps. Anyway that's unrelated to what this PR is trying to solve