Bert-Chinese-Text-Classification-Pytorch
 Bert-Chinese-Text-Classification-Pytorch copied to clipboard
Bert-Chinese-Text-Classification-Pytorch copied to clipboard
单条文本数据的预测代码
import torch
from importlib import import_module
key = {
0: 'finance',
1: 'realty',
2: 'stocks',
3: 'education',
4: 'science',
5: 'society',
6: 'politics',
7: 'sports',
8: 'game',
9: 'entertainment'
}
model_name = 'bert'
x = import_module('models.' + model_name)
config = x.Config('THUCNews')
model = x.Model(config).to(config.device)
model.load_state_dict(torch.load(config.save_path, map_location='cpu'))
def build_predict_text(text):
token = config.tokenizer.tokenize(text)
token = ['[CLS]'] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
pad_size = config.pad_size
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + ([0] * (pad_size - len(token)))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
ids = torch.LongTensor([token_ids])
seq_len = torch.LongTensor([seq_len])
mask = torch.LongTensor([mask])
return ids, seq_len, mask
def predict(text):
"""
单个文本预测
:param text:
:return:
"""
data = build_predict_text(text)
with torch.no_grad():
outputs = model(data)
num = torch.argmax(outputs)
return key[int(num)]
if __name__ == '__main__':
print(predict("备考2012高考作文必读美文50篇(一)"))
您好,这个代码运行有问题啊,报这个错。 RuntimeError: Expected object of backend CUDA but got backend CPU for argument #3 'index'
您好,这个代码运行有问题啊,报这个错。 RuntimeError: Expected object of backend CUDA but got backend CPU for argument #3 'index'
你好,我也遇到了,你解决了没?可以分享下吗? 谢谢
您好,这个代码运行有问题啊,报这个错。 RuntimeError: Expected object of backend CUDA but got backend CPU for argument #3 'index'
你好,我也遇到了,你解决了没?可以分享下吗? 谢谢
你这个问题是pytorch类型不匹配,把build_predict_text() 方法中 ids = torch.LongTensor([token_ids]) 改成 ids = torch.LongTensor([token_ids]).cuda()就行了,下面seq_len和mask同样。
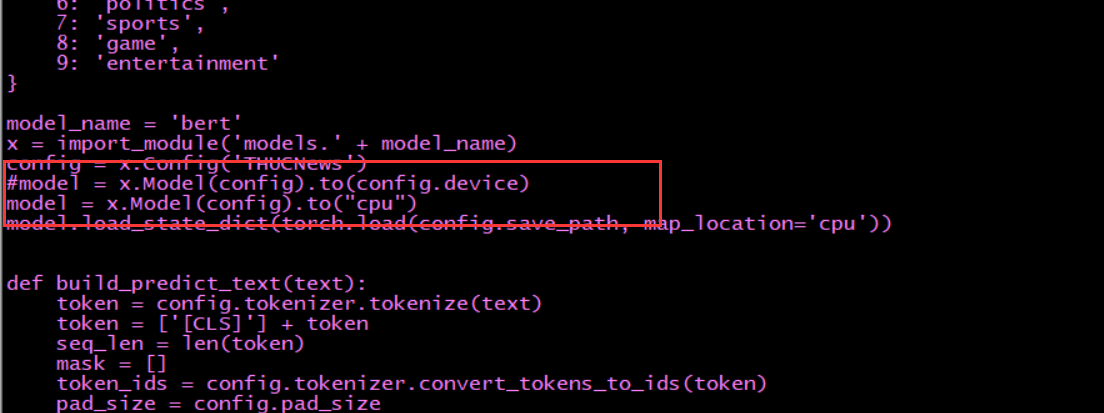 改成这个就是用cpu进行预测。
2.
改成这个就是用cpu进行预测。
2.
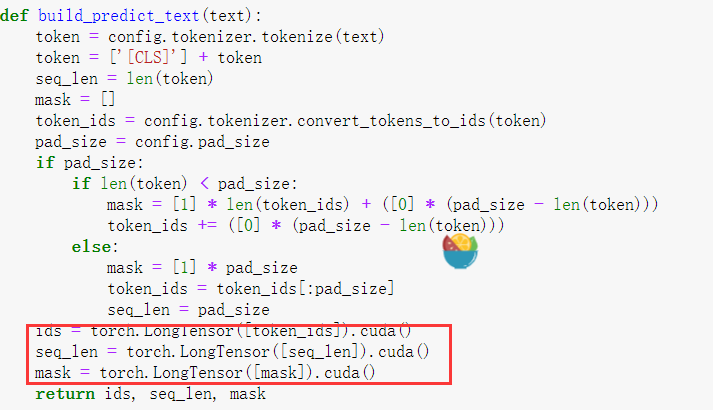 改成这个就是用gpu进行预测
改成这个就是用gpu进行预测
RuntimeError: Error(s) in loading state_dict for Model: Unexpected key(s) in state_dict: "conv_region.weight", "conv_region.bias", "conv.weight", "conv.bias". size mismatch for fc.weight: copying a param with shape torch.Size([10, 250]) from checkpoint, the shape in current model is torch.Size([10, 768]).
你好报这个错是什么原因呢?
RuntimeError: Error(s) in loading state_dict for Model: Unexpected key(s) in state_dict: "conv_region.weight", "conv_region.bias", "conv.weight", "conv.bias". size mismatch for fc.weight: copying a param with shape torch.Size([10, 250]) from checkpoint, the shape in current model is torch.Size([10, 768]).
你好报这个错是什么原因呢?
我的也是?解决了吗?
import torch from importlib import import_module key = { 0: 'finance', 1: 'realty', 2: 'stocks', 3: 'education', 4: 'science', 5: 'society', 6: 'politics', 7: 'sports', 8: 'game', 9: 'entertainment' } model_name = 'bert' x = import_module('models.' + model_name) config = x.Config('THUCNews') model = x.Model(config).to(config.device) model.load_state_dict(torch.load(config.save_path, map_location='cpu')) def build_predict_text(text): token = config.tokenizer.tokenize(text) token = ['[CLS]'] + token seq_len = len(token) mask = [] token_ids = config.tokenizer.convert_tokens_to_ids(token) pad_size = config.pad_size if pad_size: if len(token) < pad_size: mask = [1] * len(token_ids) + ([0] * (pad_size - len(token))) token_ids += ([0] * (pad_size - len(token))) else: mask = [1] * pad_size token_ids = token_ids[:pad_size] seq_len = pad_size ids = torch.LongTensor([token_ids]) seq_len = torch.LongTensor([seq_len]) mask = torch.LongTensor([mask]) return ids, seq_len, mask def predict(text): """ 单个文本预测 :param text: :return: """ data = build_predict_text(text) with torch.no_grad(): outputs = model(data) num = torch.argmax(outputs) return key[int(num)] if __name__ == '__main__': print(predict("备考2012高考作文必读美文50篇(一)"))
这预测结果相差太大了吧