CommNet
 CommNet copied to clipboard
CommNet copied to clipboard
PyTorch implementation of CommNet
Communication Neural Network (CommNet)

Ported to PyTorch from Torch. This network enables neural network based agents to communicate for cooperation.
Training
To train the network
python train.py
Levers Task
Each agent must pull a different lever after 2 communication passes. Since the agents have to cooperate, levers game is a sanity check for the implementation.
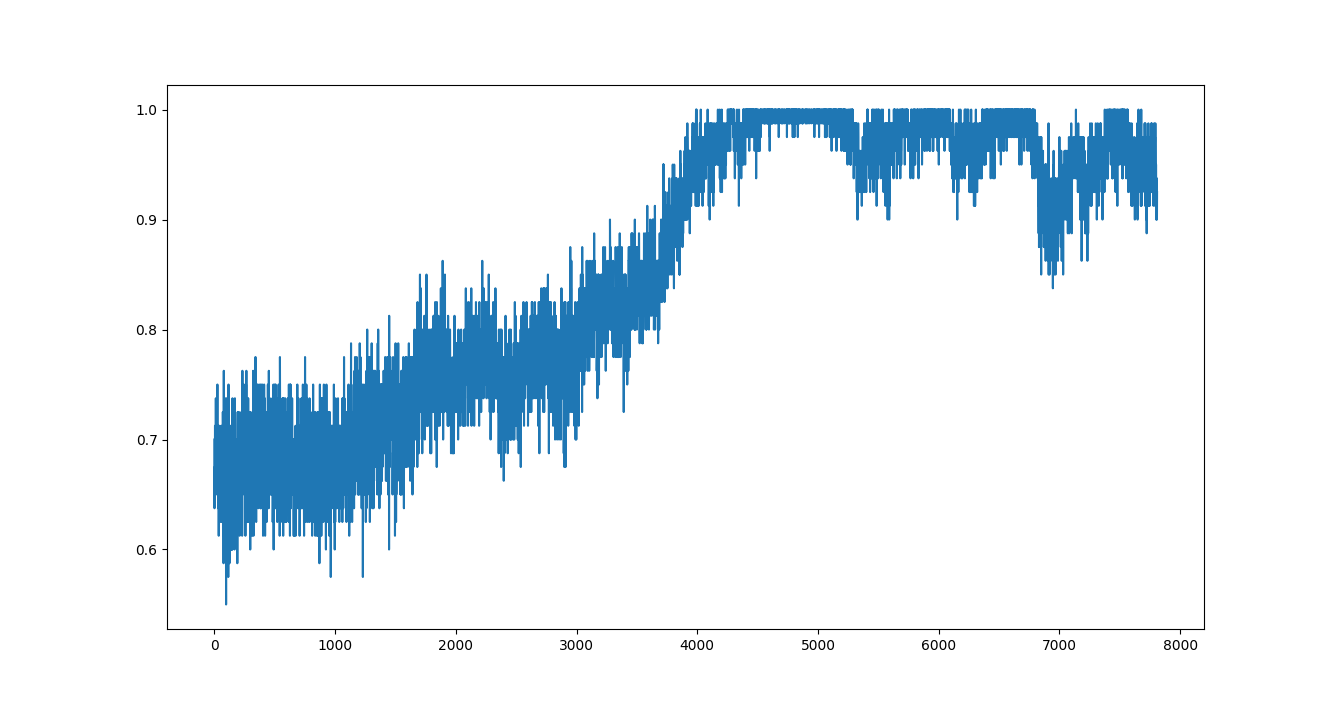
Weights
The weights file included in this repo is trained on the first 5 agents out of a pool of 10 models.
Options
opts = {
# model-related options
'model': 'mlp', # mlp | lstm | rnn, (apparently `mlp == rnn` ?)
'hidsz': HIDSZ, # the size of the internal state vector
'nonlin': 'relu', # relu | tanh | none
'init_std': 0.2, # STD of initial weights
'init_hid': 0.1, # weight of initial hidden
# unshare_hops
'encoder_lut': False, # use LookupTable in encoder instead of Linear [False]
# encoder_lut_size
# comm-related options
'comm_mode': 'avg', # operation on incoming communication: avg | sum [avg]
'comm_scale_div': 1, # divide comm vectors by this [1]
'comm_encoder': 1, # encode incoming comm: 0=identity | 1=linear [0]
'comm_decoder': 1, # decode outgoing comm: 0=identity | 1=linear | 2=nonlin [1]
'comm_zero_init': True, # initialize comm weights to zero
# comm_range
'nactions_comm': 0, # enable discrete communication when larger than 1 [1]
# TODO: implement discrete comm
# dcomm_entropy_cost
'fully_connected': True, # basically, all agent can talk to all agent
# game releated
'nmodels': N_MODELS, # the number of models in LookupTable
'nagents': N_AGENTS, # the number of agents to look up
'nactions': N_LEVERS, # the number of agent actions
# training
'optim': 'rmsprop', # optimization method: rmsprop | sgd | adam [rmsprop]
'lrate': 1e-3, # learning rate [0.001]
# 'max_grad_norm': # gradient clip value [0]
# 'clip_grad': # gradient clip value [0]
# 'alpha': # coefficient of baseline term in the cost function [0.03]
# 'epochs': # the number of training epochs [100]
'batch_size': BATCH_SIZE, # size of mini-batch (the number of parallel games) in each thread [16]
# 'nworker': # the number of threads used for training [18]
'reward_mult': 1, # coeff to multiply reward for bprop [1]
# optimizer options
'momentum': 0, # momentum for SGD [0]
'wdecay': 0, # weight decay [0]
'rmsprop_alpha': 0.99, # parameter of RMSProp [0.97]
'rmsprop_eps': 1e-6, # parameter of RMSProp [1e-06]
'adam_beta1': 0.9, # parameter of Adam [0.9]
'adam_beta2': 0.999, # parameter of Adam [0.999]
'adam_eps': 1e-8, # parameter of Adam [1e-08]
}
actor = CommNet(opts)
TODO
-
[x] Implement LSTM module
-
[x]
'comm_mode': 'avg'is broken -
[ ] Implement discrete communication through action
-
[x] Hyperparameter tuning