kube-fluentd-operator
 kube-fluentd-operator copied to clipboard
kube-fluentd-operator copied to clipboard
Supporting Multi Process Workers
Hi @jvassev @vsakarov , Any plans to support workers config under "<system>" directive and "<worker N-M>" directive as fluentd already supports it?
https://docs.fluentd.org/deployment/multi-process-workers
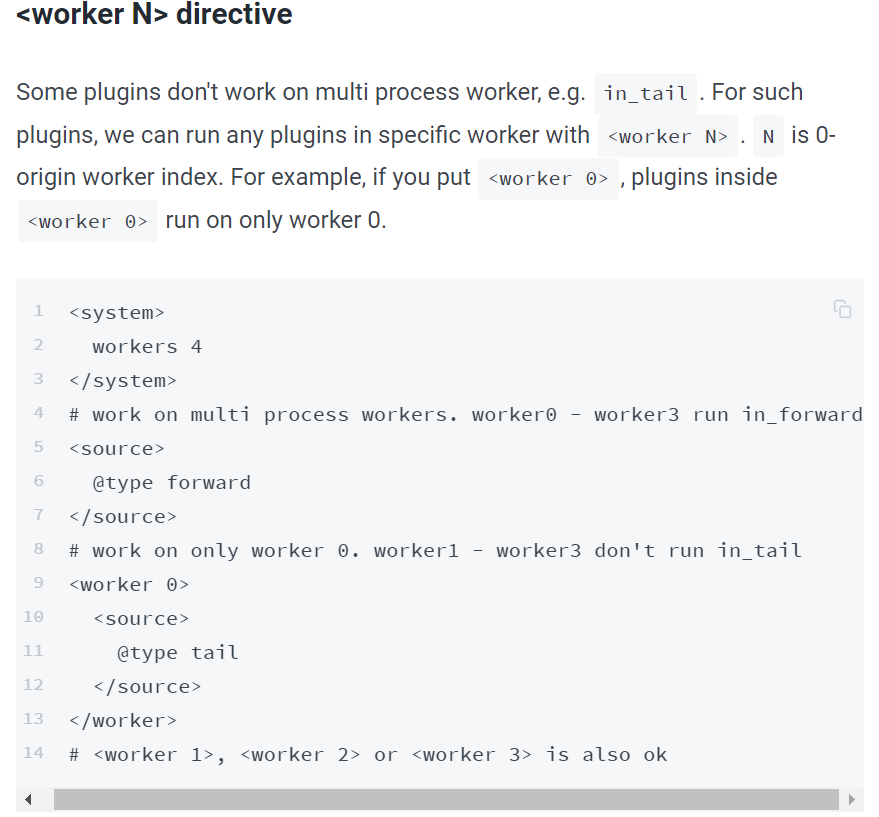
Hi,
I am still trying to figure out a way to do so. The problem I'm facing is that there is a single <source> : the /var/log/containers/*.json and it afaik it's not possible to "split" a single source across worker.
The only solution I can think of is to generate a fixed number of source and point them to a subset of log files, for example:
<worker 0>
<source>
@type tail
path /var/log/containers/0*.log
# path /var/log/containers/1*.log
# ... 16 workers as the containerID is just a hex
# path /var/log/containers/f*.log
</source>
</worker>
What's your take on this?
Hi, IMO, tailing only few log files per worker as per above proposal would be overkill. According to performance analysis of fluentd, tail and forward together can comfortably work on 75k-80k lines per second per worker. So my proposal would be to implement it like below...
- Upgrade to Fluentd 1.4 - This gives us the
<worker N-M>directive support. It would be much easier to implement multi-worker scenarios with this. There are couple plugins which do not support 1.4 yet, specifically fluent-plugin-google-cloud, fluent-plugin-vertica and fluent-plugin-verticajson. We need to see how to overcome this. - Configuration param to control multi-worker support and number of workers. We can reserve 3 workers for tail alone (1 for all
/var/log/containers/*, 1 for all other/var/log/*sources and 1 foruser-defined sources). We should take all parsing and processing out of these workers to improve performance. - Parsing, processing, adding k8s metadata and out/copy plugins should run on other workers ( By default we can have 6 workers (3 for tail and 3 for parsing, processing and out/copy)). Before starting fluentd daemon, the workers must be mentioned (in our case failsafe.conf), otherwise workers don't start and it can't be modified through /api/config.reload.
Let me know what you think.
@jvassev Any thought on this? It will be difficult to support multi-worker model without upgrading to fluentd 1.4, but I don't see fluent-plugin-google-cloud supporting it soon (I can work on fluent-plugin-vertica and fluent-plugin-verticajson to make them compatible).
Hi @apu1111, Sounds like a plan. It seems like upgrade to 1.4 is long overdue now.
How can we make sure that plugins which are not worker-safe still work - event if performance is worse?
As for the few plugin that you mentioned which cant work in 1.4, I am fine with temporarily disabling them. Their users can still deploy previous versions.
Hi @jvassev , Cool. I will start working on this then. According to the plan, I will start with upgrading to Fluentd 1.4 and then move to making sure all the plugin works fine with multi-worker. Next task will be to add the config options and changing the code to make it work.
If fluentd doesn't complain about a plugin during starting in multi-worker mode, we can assume the plugin supports multi-worker, because each plugin needs to implement a specific method called "multi_workers_ready?" to be multi-worker ready and by default this method is absent. Otherwise testing each and every plugin would be difficult and time consuming.
I will check with these plugin owners again on the plans but most likely we have to disable them until they upgrade to 1.4.
Will get back once I am able to make some progress.
@apu1111 how can we parsing processing with different workers? When I am doing it , it says that the tags are not used/matching since the tail is running in worker0
@apu1111 how can we parsing processing with different workers? When I am doing it , it says that the tags are not used/matching since the tail is running in worker0
You need to use forward directive to emit the logs from one worker to another.