detection-attributes-fields
 detection-attributes-fields copied to clipboard
detection-attributes-fields copied to clipboard
how's the result and performance?
The results are a bit better than in the paper, with ~49% mAP on all 32 attributes, and ~70% AP for pedestrian detection, on the test set of JAAD. The evaluation can be slow depending on the images, due to the decoder used. It is still reasonable for offline evaluation, but may not suit real-time applications right now.
@taylormordan I saw that this model using a resnet50 backbone and it using a head with different fields output, it shouldn't be very slow? But I found it's about 1.1 images/s on GTX1080Ti
The network itself has no performance issue, but the decoder that runs OPTICS clustering at inference (i.e., the post-processing step to get predictions from fields) can run slow on some images. I plan to have a look at it and see if it can be faster in the future, but this is the only option implemented for now.
@taylormordan thank u, I looked into the code, found that Optics is hard to understand what steps did in that? From I can see, it's simply get predictions from model output, this shouldn't be slow, but also did clustering, why it need a clustering? For what purpose?
How many thing really needed for decoder? If I don't need tracking information, I only need boxes and attrs, it should directly retrivable from model output?
The network output is a full feature map for each attribute. The decoder takes all these maps and transforms them into a set of detected pedestrians. For this, the clustering step groups the cells that correspond to the same pedestrians together to form instances.
@taylormordan OPTICS is for grouping instances, but isn't the predictin is a set of boxes?
[x1 y1 x2 y2 c s]
[x1 y1 x2 y2 c s]
[x1 y1 x2 y2 c s]
So that every box should be a instance? Why it still need a clustering?
You can view each cell of the output as a prediction, but you need a criterion to select which cells to consider. OPTICS is one way to do it, others are possible (and might be faster).
@taylormordan forgive me if I am with poor understanding, which do u mean "cell" here in tensor? which dimension can be consider as "cell"? is every cell is a box predicted?
What I called cell is any spatial location in the output feature maps. If the maps are of size C x H x W (with C channels, height H and width W), then there are HW such cells. Figure 2 from the paper may give you a better idea of what I mean if this is not clear.
@taylormordan I seems understand a little bit. still have 2 questions:
1). HW cells, how do they grouped to N instances (persons), I mean by which metric group? 2). Doens't it need a further step to do nms if grouped doesn't it? It looks more like a dense way to do such a thing.
oh, one last question:
'pose_back': 0.37709974782729616, 'pose_front': 0.19065712382244238, 'pose_left': 0.4807551450307224, 'pose_right': 0.2909739372741419,
these pose directions none of them bigger than 0.5, is that we treat the max probability one?
- The cells are grouped based on where the
centerfields point at: points close enough are clustered together into an instance with OPTICS. - We did not find the need to have NMS with OPTICS, but it may replace it. I actually plan on looking at this when I find time to do so.
Regarding the pose directions, we use four binary attributes because that is how they are annotated on JAAD, so there is no guaranty that only one of them if greater than 0.5. You can take the greatest one in this case.
@taylormordan looking forward to your exploring, if using nms replace OPTIC, will it faster than cluster?
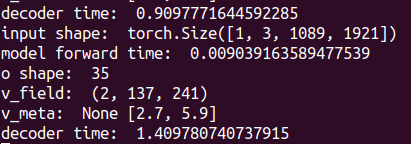
@taylormordan I found the decoder time is 100x slower than model forward time:
Hello mr.@taylormordan thank you very much for your Information, I succeed to generate the JSON file, but I need to figure out how to generate some attributes in the video or image?