cats-effect
 cats-effect copied to clipboard
cats-effect copied to clipboard
Batches of fibers may be scheduled unfairly in compute-heavy applications
This is the result of the following experiment:
- start
nfibers - each fiber has an
id - the fiber loops, infinitely incrementing an ID-bound value in a
Ref[IO, Map[String, Int]], where theStringis the fiber'sid, then yields withIO.cede.
The result is that the fibers that get started first get to do most of the incrementing (n = 20):
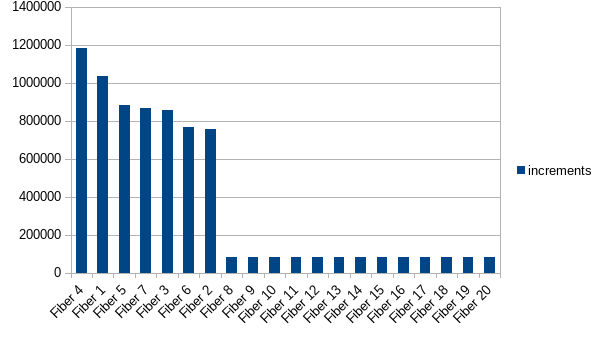
import cats.effect.{IO, IOApp, Ref}
import cats.implicits._
import scala.concurrent.duration._
object FairnessExperiment extends IOApp.Simple {
override def run: IO[Unit] = for {
ref <- Ref[IO].of(Map.empty[String, Int])
_ <- (1 to 20).map(i => loop(s"Fiber $i", ref)(0).start).toList.parSequence
_ <- (IO.sleep(1.second) >> ref.get >>= printCountsAsCsv).foreverM
} yield ()
def loop(id: String, ref: Ref[IO, Map[String, Int]])(i: Int): IO[Unit] = for {
_ <- ref.getAndUpdate(s => s.updatedWith(id)(v => Some(v.getOrElse(0) + 1)))
_ <- IO.cede
result <- loop(id, ref)(i + 1)
} yield result
private def printCountsAsCsv(counts: Map[String, Int]) = IO.delay {
val columns = counts.toList.sortBy(-_._2)
println(columns.map(_._1).mkString(","))
println(columns.map(_._2).mkString(","))
}
}
First of all, thanks for raising this issue. Is this on the 3.2.9 release?
We've actually made changes to these code paths which will be released in the 3.3 release. In the meantime, can you please use the following snapshot to repeat the experiment for the upcoming release? Thank you in advance.
"org.typelevel" %% "cats-effect" % "3.3-393-da7c7c7"
Furthermore, can you please post some details of the machine that this was run on? CPU, number of configured threads, things like that.
Thank you again.
This issue reminds me of this one https://github.com/typelevel/cats-effect/issues/1995.
That was on 3.2.9, forgot to include that, sorry. java-11-openjdk, linux.
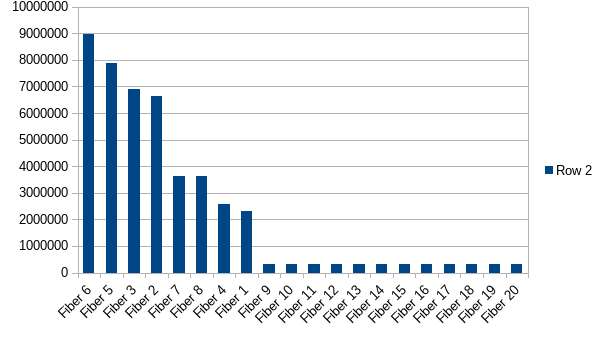
3.3-393-da7c7c7 gives me a similar result (this is after 20 seconds, there is some variance among reruns):
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i7-8650U CPU @ 1.90GHz
CPU family: 6
Model: 142
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
Stepping: 10
CPU max MHz: 4200.0000
CPU min MHz: 400.0000
I've been running it in intellij and confirmed similar results in sbt.
Just out of curiosity, inserting IO.sleep(0.nanos) instead of IO.cede seems to make the situation fairer at the cost of throughput (~20%). Edit: replacing cede with IO.blocking(()) gives me the same effect with 50%+ throughput.
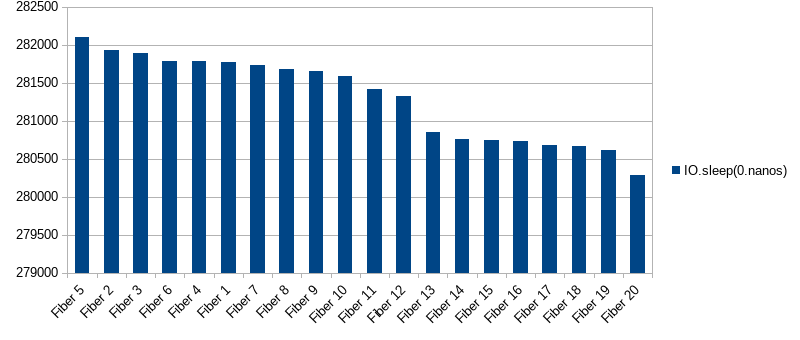
Well, it's not really that surprising. Until we have something like #2252, IO.sleep results in a round trip through a different executor and a re-enqueue on the external queue.
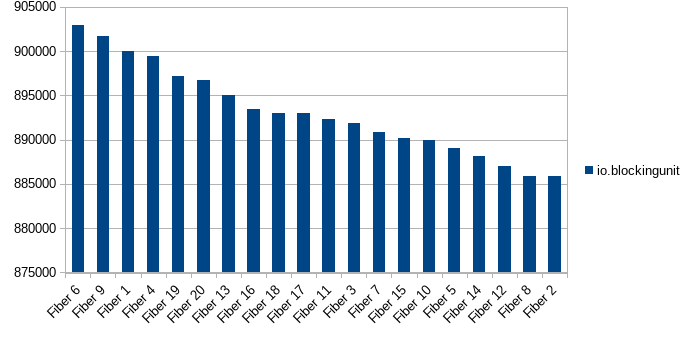
This may be more detracting than helpful, but this is a result when replacing cede with IO.blocking(()) (~50% original throughput, and no apparent preference for first Fibers)
@otto-dev Can you maybe do a run with many fibers? Like a thousand maybe? I know it's a tall ask, but it would be of tremendous help.
No tall ask at all.
1000 fibers after 20 seconds:
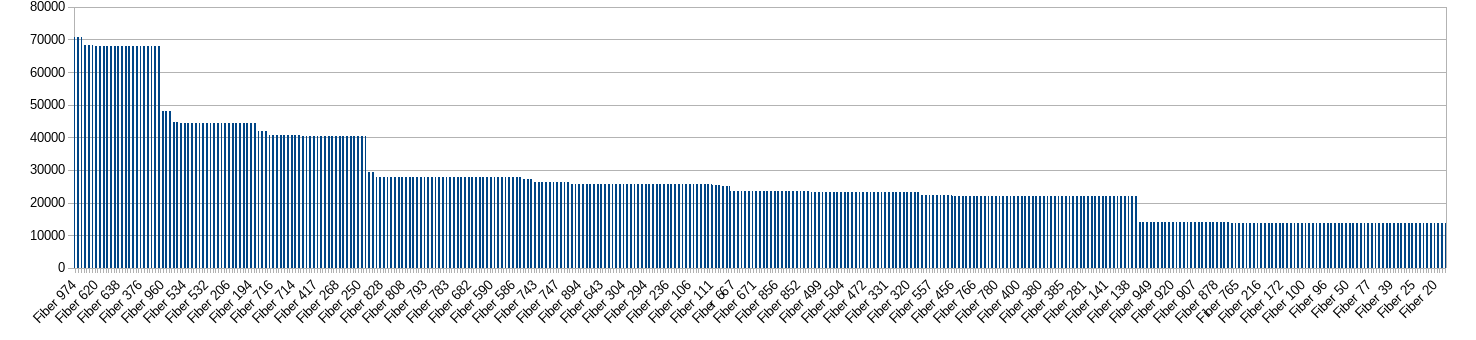
After 2 minutes:
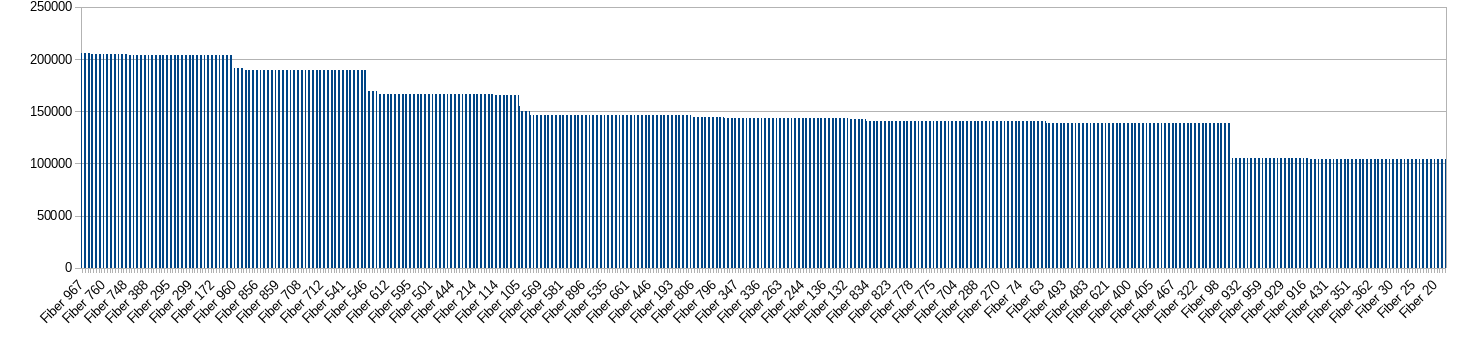
Raw data: https://gist.github.com/otto-dev/ceaa3ce765bcbfd267dc7abeb2754af0
So this issue is unlikely to affect real-world applications with many fibers.
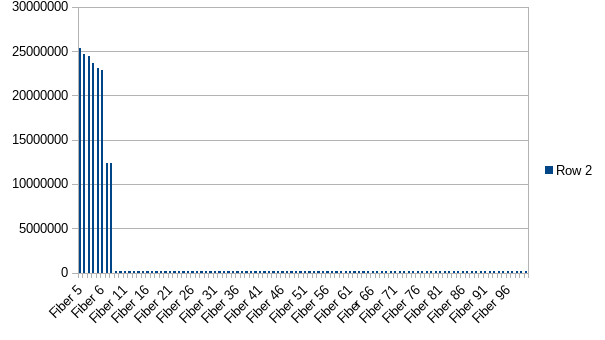
However, the imbalance remains pronounced with 100 Fibers, 2 minutes:
Very strange (and maybe informative) results with 500 fibers, 2 minutes:
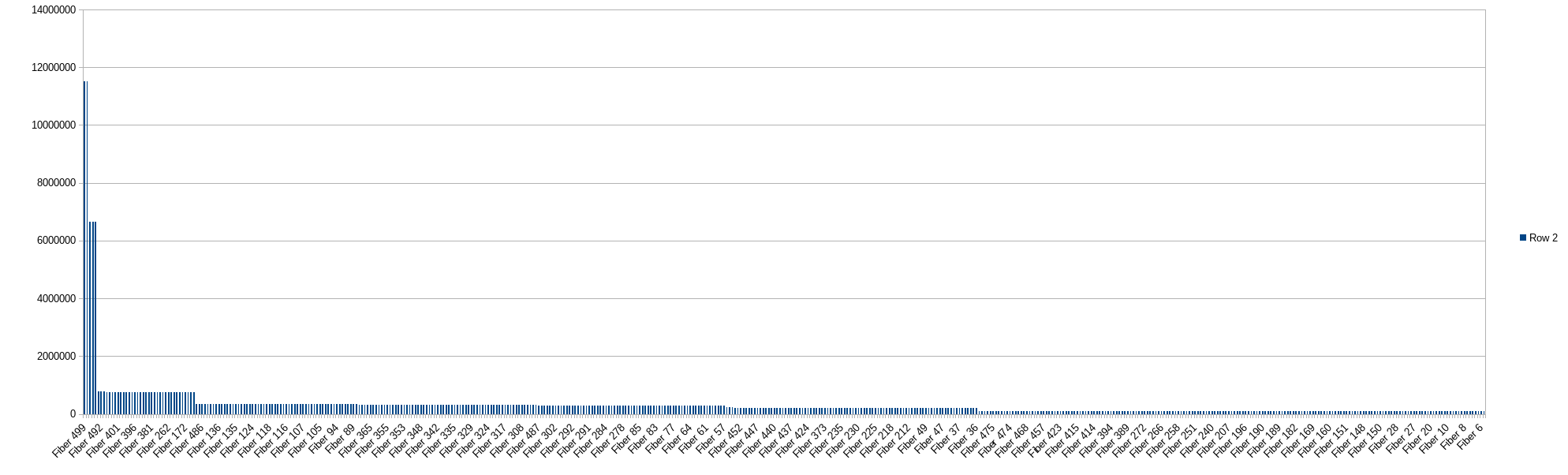 (click to expand - the two bars on the left are fiber 499 and 500! Followed by
(click to expand - the two bars on the left are fiber 499 and 500! Followed by Fiber 496,Fiber 497,Fiber 498,Fiber 490,Fiber 492,Fiber 491)
I think the last run may give a strong clue about what's going on.
(To avoid confusion, this is with cede).
@otto-dev Thank you for raising this issue, truly. We should have a longer form comment soon.
Okay so after some quick investigation, @vasilmkd and I are pretty sure we know what's going on here. tldr: the pool isn't tuned for this type of scenario, by design
Before we get into the results, just a quick bit of context. Work-stealing, by definition, trades away fairness to get higher throughput. That's just what it does. If you want perfect fairness, you need to have a single queue that all threads steal from exactly in arrival order. So in other words, FixedThreadPool. That kind of contention is extremely slow though, so using work-stealing corrupts the fairness properties somewhat in order to marginalize contention and allow workers to be more isolated. The downside is that isolated workers may therefore behave asymmetrically and we might not know it. The trick is to design the algorithm and data structure such that this doesn't happen very often in practice, or if it does happen, it doesn't last for very long.
The test given in the OP creates 20 fibers (ignoring the parSequence, which creates a few others for a while) which live forever, then spawns no more fibers and just lets those few run forever. This is a very artificial scenario, and one which the pool isn't designed to handle. All of the rebalancing and scheduling that happens on the pool, happens around task ingestion, which is a fancy way of saying "when new fibers start or async actions complete". The test isn't doing any of that though, so none of that logic triggers. Worse-still, the number of steady-state fibers in this test is below the pool's thresholds for proactive management (spilling). This means that the pool is operating in a somewhat pathological mode where you have a very small number of fibers living for a very long time, and all of those fibers were forked all at once from a single parent fiber, and no additional forking or asynchronous completion ever takes place. If any of those conditions are falsified, the pool would rebalance.
However, because all of those things are false, we end up in the situation described in the OP. For reference, here's a chart from my machine (I increased the fiber count to 40; I also removed the single-Ref contention point just to rule that out):
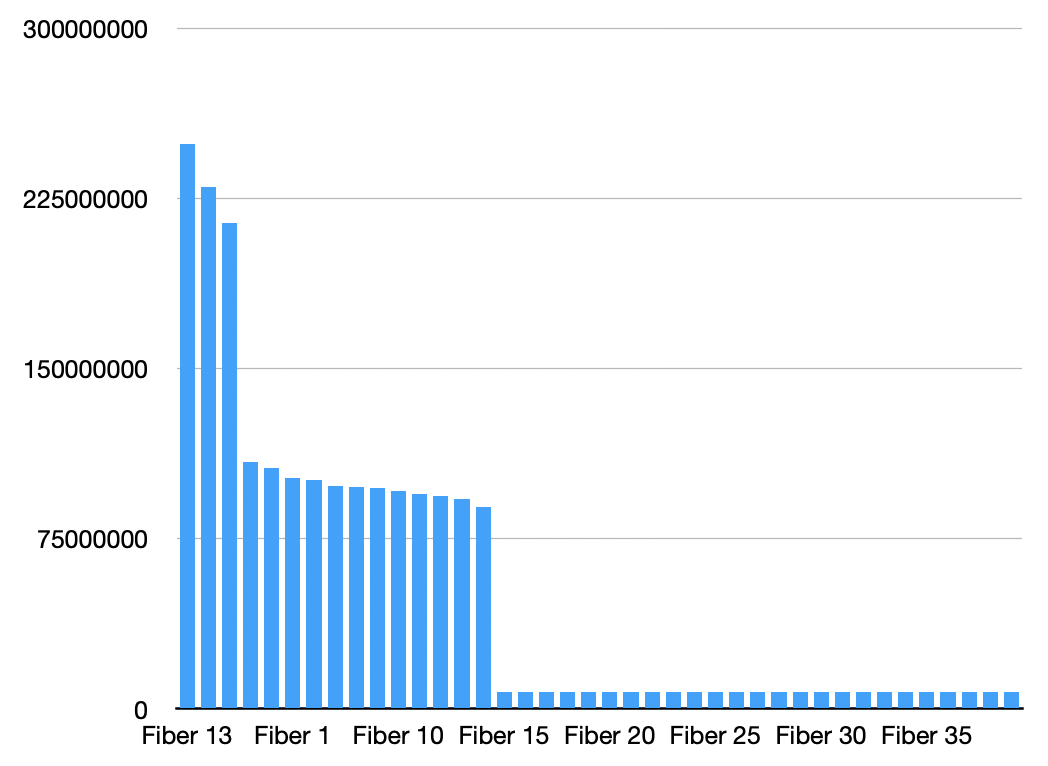
In other words, exactly replicating the OP's test. Now, let's change the test a little bit. In particular:
def loop(id: String, ref: Ref[IO, Map[String, Int]])(i: Int): IO[Unit] = for {
name <- IO(Thread.currentThread().getName())
_ <- ref.getAndUpdate(s => s.updatedWith(name)(v => Some(v.getOrElse(0) + 1)))
_ <- IO.cede
result <- loop(id, ref)(i + 1)
} yield result
So now we're counting the amount of work that the threads are doing, not the amount of work the fibers do:
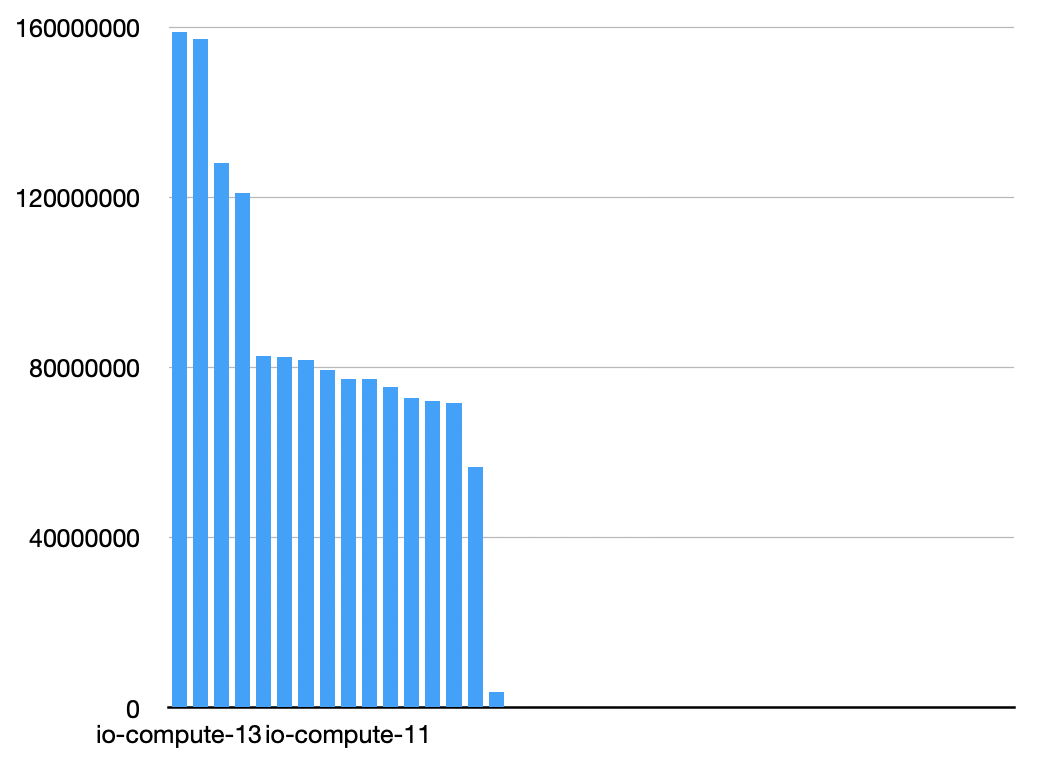
As they say on The Office, these are the same images.
What's happening here is the first worker thread basically gets completely inundated. The first few fibers it spawns end up getting sent to the other workers because they're parked at the beginning, and so they steal one at a time and begin working, but from that point forward all of the workers are busy but there are still more fibers to fork. A few additional fibers get forked on the non-primary worker due to the parSequence (which is itself forking fibers), but this is a minor effect. Most things bottle up on the first few workers, while all of the remaining workers never steal because they're all continuously busy with these permanently running and never-async-suspending fibers.
If we had more fibers being forked, they would end up getting spilled onto the external queue, which is still checked even by the pathological single-fiber-workers, which in turn would result in significantly more balancing. We can validate this assumption by increasing the fiber count to 1000, at which point we see a situation in which the most-scheduled fiber is within 3x of the least-scheduled fiber, which is much closer to what should be considered "fair" by work-stealing standards.
You would see an even more even profile if you had shorter-lived fibers that forked new ones, or new fibers coming in all the time. In other words, a runtime profile which more closely approximates a running network service. Which in turn comes all the way back to the beginning: work-stealing is optimized to trade off some fairness, with with the assumption that the usage-patterns are very much like a network service, and especially HTTP microservices. If your use-case is extremely far afield from that case (e.g. stellar observation simulations, machine learning, etc), then you may see sub-optimal results relative to what you could in theory do with a fixed thread pool. And this is exactly what the OP is demonstrating. :-)
For what it's worth, every work-stealing implementation that I'm aware of has this same tradeoff, and in fact exhibits almost identical behavior in the scenario described in the OP.
Anyway, all of this is very interesting stuff! I think this is behaving as-designed, though. I'm going to close the issue, but feel free to continue discussing!
Always good reading 🤓 If you don't mind, I'd appreciate some expanded thoughts on the topic of compute-bound workloads, for those of us who care about such things (asking for a friend ;).
If your use-case is extremely far afield from that case (e.g. stellar observation simulations, machine learning, etc), then you may see sub-optimal results relative to what you could in theory do with a fixed thread pool.
Just to clarify, what exactly does "sub-optimal" results mean in this context? That threads could be sitting idle? This is the real nightmare! Or, is it just lack of fairness.
And then, is using a work-stealing pool just wrong for this sort of thing, e.g. in favor of a fixed thread pool? Or is there a way to adjust these workloads so they are more amenable to the work-stealing pool and have performance benefits over the fixed thread pool? Considering your comment:
This means that the pool is operating in a somewhat pathological mode where you have a very small number of fibers living for a very long time, and all of those fibers were forked all at once from a single parent fiber, and no additional forking or asynchronous completion ever takes place. If any of those conditions are falsified, the pool would rebalance.
It feels tempting to find a way to artificially violate one of those conditions!
The broader question here being, what is the best way to use Cats Effect for compute-heavy, non-microservice style applications?
The broader question here being, what is the best way to use Cats Effect for compute-heavy, non-microservice style applications?
My 2 cents on this question. I would say, don't treat fibers like threads. Threads are expensive to start, expensive to join, are well behaved when they are few and pinned to a CPU core each. Fibers on the other hand, are cheap to start, cheap to join and the more you have of them, the better the performance and scheduling fairness that you get (i.e. are well behaved when you create lots of them).
If your application cannot really be written in this manner, and you can measure that you're actually running into a situation like this, you can use a java.util.concurrent.FixedThreadPoolExecutor and it will most likely perform as well or better (in terms of performance or fairness, or both). Otherwise, just don't worry about it. Work stealing is a fine default.
Finally, we are computer scientists and engineers, and we know that there are no silver bullets in our profession, just tradeoffs.
And none of this is final. Work stealing is still pretty new in effect systems, especially in Scala. We have so much to learn and tune and maybe we'll teach the runtime to tune itself one day, behaving more like a fixed thread pool on low loads and doing work stealing on higher loads. There are unfortunately too many other quality of life improvements that need to be implemented first, and docs to be written, and real world software to be deployed in production. We're generally in a very good spot performance-wise, and it will only get better over time. I wouldn't worry about it too much.
Thanks for the reply! Interesting stuff indeed. For me the important thing was to understand when/if I can expect liveliness problems with an application. My takeaway is that you only ever run into this problem if you have absolutely no asynchronous operations in your application.
It feels tempting to find a way to artificially violate one of those conditions!
Changing the fiber creation to this:
_ <- (1 to 100)
.map(i => IO.sleep(200.millis) *> loop(s"Fiber $i", ref)(0).start)
.toList
.parSequence
is enough to get this work distribution over two minutes:
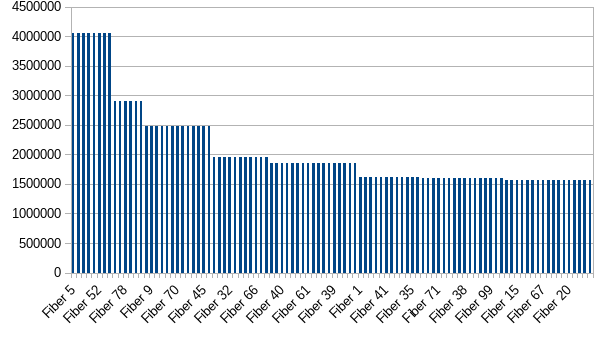
which, arguably, is fair enough (in both senses). I.e. there isn't any fiber that's totally starved.
Edit: Actually, that's all it takes? The IO.sleep(200.millis) is even parSequenced.
Edit2: Event more unexpected, changing it to .map(i => IO.blocking(()) *> loop(s"Fiber $i", ref)(0).start) is all that is required to get this distribution.
So the reason that sleep and blocking change the semantics here is they effectively remove the work-stealing pool's ability to optimize itself! More precisely, in both situations you're bouncing the fiber through a different execution context, which means that the returning continuations will come back through the external queue. The external queue is a single task source which all worker threads pull from, which should sound familiar: it's the exact same thing that FixedThreadPool does! In other words, by using sleep and blocking rather than cede, you're removing work stealing altogether, and you're basically forcing the runtime to behave as if you had done an evalOn with a fixed pool. This has some significant performance costs, as you noted.
(note: we're working on an optimization to sleep which allows it to remain within the work-stealing pool and has several advantages, including removing this particular performance hit)
Coming back to your broader question about workloads… I would say that, in general, you shouldn't have to think too hard about it. Outside of very artificial scenarios (such as the test in this thread), the pool very rapidly converges to a near-optimal task distribution, even for heavily compute-bound tasks. The worst possible scenario is where you just start n fully-synchronous (no async) fibers, where n > Runtime.getRuntime().availableProcessors(), and then you leave them running for an enormously long time and never start anything else. So in other words, what you see here. :-) Even compute-bound scenarios tend to be different than this, with internal forking (e.g. the fibers themselves calling start or par-something), async usage, etc. Any of those things end up triggering the pool to progressively rebalance itself, which in turn results in better fairness.
Even in the worst possible scenario though, what happens is all threads are active, but some fibers receive a lesser time share than other fibers. This is still okay in a sense, because the net average throughput is identical! This is a bit unintuitive, but it's important to remember that fairness and throughput are not usually connected aside from the fact that improving one often means degrading the other. In this case, the throughput is at its theoretical maxima (outside of some subtle cache eviction behaviors) regardless of whether one worker handles 99% of the fibers while every other work handles just one, or if all workers handle the same number of fibers. No compute time is being wasted, and so the total average throughput across all fibers is identical to if there were an even distribution across all workers.
In the test, this "average throughput" manifests as the sum total number of counts across all fibers. The point I'm making is the sum across all fibers is the same in the current (unbalanced distribution) situation as it would be if we could somehow wave a magic wand and make all workers have the same number of fibers.
Fairness is more closely related to responsiveness and jitter. Intuitively, you can think of it in microservice terms: a new network request comes in (which manifests as an async completion), and some worker thread needs to pick that up and respond to it. How long does it take for that fiber continuation to get time on a worker? That is fairness. But, remember, we have definitionally ruled out that scenario in our test setup, because we said "no async" and also "fork a set number of fibers and then never fork ever again". So in other words, the test in the OP does do a decent job of artificially measuring fairness, but in doing so it constructs a scenario in which fairness is irrelevant, because it's entirely throughput-bound and throughput is maximized!
If you construct a scenario in which fairness matters (which will require the use of async), you will also by definition trip the mechanisms in the pool which rebalance the workers, which in turn will ensure that fairness is preserved.
All of which is to say that the work-stealing pool is a very safe default, even for these kinds of long-running CPU-bound scenarios, simply because the fairness tradeoffs it makes are definitionally irrelevant in such scenarios. Now, I'm not going to make the claim that this is the case for all possible scenarios, because I have no proof that this is the case, but this is why you can always use evalOn and shift things over to a FixedThreadPool (or other) if you measure that it improves things.
Thank you, Vasil and Daniel for your responses! Much appreciated.
If your use-case is extremely far afield from that case (e.g. stellar observation simulations, machine learning, etc), then you may see sub-optimal results relative to what you could in theory do with a fixed thread pool.
IIUC now, I think this sounded far scarier to me than it actually is, where "may" is more like unlikely, but no guarantees and "sub-optimal results" refers to the lack of fairness and not at all a diminished throughput. Which at least for me is my foremost concern in an app like that.
I would say, don't treat fibers like threads.
💯 I'm going to internalize this :) it's a new world for everyone (microservices and scientific computing alike) and I still need to unshackle my algorithms and my mindset from the old ways!
Thanks again to everyone for the helpful thoughts and responses! Very much appreciate the input on this question, amazing how this was looked into.
Conclusion in the end: It's not a bug, it's a feature! Cats Effect optimizes for throughput if there are purely synchronous compute-based tasks, where fairness does not matter. As soon as there is a request-response type scenario (anything async), it optimizes for fairness.
by using sleep and blocking rather than cede, you're removing work stealing altogether, and you're basically forcing the runtime to behave as if you had done an evalOn with a fixed pool. This has some significant performance costs, as you noted.
Actually, that can't be the whole story, because I'm getting the fairness at no cost to performance!
The blocking(()) call is not actually part of the Fiber, but precedes it: IO.blocking(()) >> (loop(s"Fiber $i", ref)(0).start).
That's enough to create a reasonably fair work distribution, and in fact, with this version I'm seeing 10% more throughput on average (sum of all increments).
But I agree that the practical implications for this are near-zero or zero. Something seems to be going on, maybe it's possible to hunt down why one scenario is fair while the other isn't (with comparable performance), but I don't know if it's worth it.
Gist of fair version with equal performance.
I kind of got hooked on this as a learning experience and started hacking the codebase. This illustrates what's going on, in line with @djspiewak's explanation:
(computeWorkerThreadCount: Int = 2)
<io-compute-1> spawning <cats.effect.IOFiber@4c6cb4b8 RUNNING>
[io-compute-0] stealing fibers from other worker threads
[Fiber says] Computation on io-compute-0
<io-compute-1> spawning <cats.effect.IOFiber@1df412c7 RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@3aabf97a RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@134b43e3 RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@246527fb RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@19ba6b9a RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@7cbf31fe RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@35a221d1 RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@38f59261 RUNNING>
<io-compute-1> spawning <cats.effect.IOFiber@776c372a RUNNING>
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
[Fiber says] Computation on io-compute-1
All the fibers get spawned on the same thread, and the idle threads (in this case, one), only steal one fiber each, and after that consider themselves busy.
I wonder if
- You could spawn fibers on threads in a random / round-robin fashion to begin with, without significant performance impact
- or if you could trigger a periodic rebalance if all worker threads are busy
Conceptually, would this be viable? I'm getting a fairish workload with about 10% more throughput quite consistently:
--- a/core/jvm/src/main/scala/cats/effect/unsafe/WorkStealingThreadPool.scala
+++ b/core/jvm/src/main/scala/cats/effect/unsafe/WorkStealingThreadPool.scala
@@ -31,10 +31,10 @@ package cats.effect
package unsafe
import scala.concurrent.ExecutionContext
-
import java.util.concurrent.ThreadLocalRandom
import java.util.concurrent.atomic.{AtomicBoolean, AtomicInteger}
import java.util.concurrent.locks.LockSupport
+import scala.util.Random
/**
* Work-stealing thread pool which manages a pool of [[WorkerThread]] s for the specific purpose
@@ -399,7 +399,8 @@ private[effect] final class WorkStealingThreadPool(
if (thread.isInstanceOf[WorkerThread]) {
val worker = thread.asInstanceOf[WorkerThread]
if (worker.isOwnedBy(pool)) {
- worker.schedule(fiber)
+ val other = workerThreads(Random.nextInt(workerThreads.length))
+ other.schedule(fiber)
} else {
scheduleExternal(fiber)
}
Round robin would be even better. Or would this need scheduleExternal (which defeats the purpose)? Docs on scheduleExternal would indicate that it is not required.
Does not take into account potential thread-safety concerns related to the queue. (Edit: WorkStealingThreadPool.scala#L153 would indicate the assumption that there are no thread-safety concerns)
The WorkerThread#schedule method is only safe to use by the worker thread itself, due to how the LocalQueue is implemented. It is a single producer multiple consumer circular buffer, and only the owner thread is allowed to enqueue elements. Other threads are fine to dequeue from it (this is the stealing, which is around WorkStealingThreadPool.scala:153.
The pool is really tuned for high fiber workloads, and starting new fibers this way is fine, when there are many fibers. What we can do however, is determine if most/all other worker threads other than the current one are sleeping. In that case, we could start new fibers on the external queue (the queue which is shared by all worker threads) and they would be nicely distributed among the worker threads.
We're kind of scrambling to finish a couple of higher priority features at the moment, and start the 3.3.x lineage of releases. This optimization could easily come in the releases after 3.3.0. It will require some more careful thought and I want to carefully measure the outcome.
I've started off the PR process in #2514, but I'll still have to look into producing benchmarks for different scenarios firstly, and secondly whatever other contributing processes you may have.