recommenders
 recommenders copied to clipboard
recommenders copied to clipboard
[Question] Using Temperature and Hard Negative Mining for Retrieval Models
I've read in a couple of papers that mention that careful tuning the temperature hyperparameter is critical for retrieval quality
Quoting from the paper

From what i understand about the temperature, setting it to >1 specially in encoder decoder setting is done after the training, to make the output probability distribution become more uniformly distributed, to have more diverse outputs, here i found the temperature is used within the training and usually set from papers experiments to a number below 1 --> ~0.2
My question here is after setting it to 0.2 we're actually making the model become more confident in its prediction so the gradient magnitude is becoming smaller, so the changes aren't that dramatic due to the softmax loss function (only when the true label is predicted, but if it's not the case it has more dramatic changes, as the true output will be pushed to 0 )
Sample True Labels = [0, 1, 0] Logits = [9, 0.5, 3] Softmax = [0.99, 0.0002, 0.002] Temp = 0.2 Logits after Temp = [45, 2.5, 15] Softmax after temp = [1.0, 3e^-19, 9e^-14]
On the other end, if it's > 1 I'm not sure what would be the intuition then, but we'll be damping the softmax for our prediction even if it's true,
In that case compared to the true labels, the gradients magnitude will become so big, so not sure about the intuition behind that and how it can be tuned (when i tried tuning the temperature, i saw warnings that some divisions encountered zero)
Also I'm not sure how hard negatives would be useful in that case?
Have anyone managed to successfully tune it and got good accuracy out of it? what is the range you have tried?
This is a great question @OmarMAmin, and one that only recently have I got round to experimenting with. The first thing to be clear on is that this is describing the case where the embeddings are normalised.
If the output of your query and candidate towers are not normalised, then the temperature parameter is redundant This is because the embeddings can be scaled arbitrarily during training.
If the embeddings are L2-normalised then the range of scores for a query/candidate pair will lie within the interval [-1,1].
In my experience this is too restrictive to produce a reasonable distribution for the softmax.
Notably, if using candidate_sampling_probability for bias correction, log(1e-6) = -13.81, which lies far beyond this interval.
In this case a starting value for the temperature might be around t = 1/14 = 0.07, but this parameter should probably be tuned.
So in short the paper is suggesting that normalising the embeddings improves trainability, but that a temperature is needed to scale the output distribution, and I suspect this should roughly scale to around the logarithm of the minimum candidate probability, but I haven't tuned this parameter yet myself.
Thanks @patrickorlando, Got it that they are related, so temperature tuning, normalization, and candidate sampling probability are actually coupled somehow 👍
Will look into it, and share the results if i was able to get it right
@OmarMAmin I can share my experience, although I mostly rely on automated hyperparameter search, based on Keras Tuner.
So the normalization that the paper mentions I added at both Towers. I build a Keras Tuner script based on this tutorial I made almost every hyperparameter tunable, in reasonable value intervals. Like embedding dimensions, number of layers, regularization types and coefficients, activation functions, include BN or not, etc. + temperature. I am using the Tuner for half a year now and it always produced a parameter setting that was better than I could come up with (both offline top-K accuracies and online A/B tests). I mostly used Bayesian Optimization.
@hkristof03 thanks so much for mentioning this, I came back as well to report a significant improvement after tuning the architecture, what i did
- I made a shared embedding layer between query and candidate towers (prev items in the query tower share embeddings with item_id in the candidate tower) -> i guess this allows for the towers to interact early on somehow, instead of only interacting in the dot product (thanks to @maciejkula )
- I implemented mixed negative sampling paper, and I guess as they mention it improved the quality of the recommendations (giving more exposure to relevant long tail items, haven't quantified the contribution of each popularity tier to the accuracy, but will do so)
- I tuned the temperature parameter (actually found the right range ~0.005 which i wasn't exploring before) --> this was the most impactful step i guess.
| Model | HitRate@10 |
|---|---|
| Before Improvement | 25% |
| After Improvements | 50% |
I've an easier use case where the item corpus is around 4000 (it's easier to get these gains, and I'm expecting others once i add more relevant features), but what i like about the two tower, is the inference speed, that's why I'm not using ranker directly
Thanks @patrickorlando and @maciejkula for your help
@OmarMAmin
- Do you have a related topic here where you discussed this? I'm planning to implement the involvement of the previous items as well, but I was thinking about how to aggregate the embeddings. May I ask, how did you do it and in case what other methods do you know about?
- Would you share the code?
Thanks for sharing your results @OmarMAmin, I'll definitely be tuning the temperature parameter!
you're welcome @patrickorlando, tbh not sure if it was the main contribution, and not mixed negative sampling and the embedding sharing, but I guess mixed negative sampling just made the right temperature value be near to my search space somehow.
@hkristof03 I wanted to share the issue where that was discussed but didn't find it unfortunately, but it was shared as a piece of advice, without any experimental results.
For the prev embedding aggregation, I used global average pooling, in the youtube paper, they mentioned that they tried multiple aggregation scenarios (i.e. max pooling) but wasn't that impactful that much but the paper was around 2016, I guess we can improve the aggregation with recent techniques, I tried GRU but didn't improve the results that much (and the training time got impacted, so i didn't explore the parameters that much), I'm going to try attention aggregation.
There's a paper that got good accuracy by using attention on top of different features instead of just concatenating the embeddings.
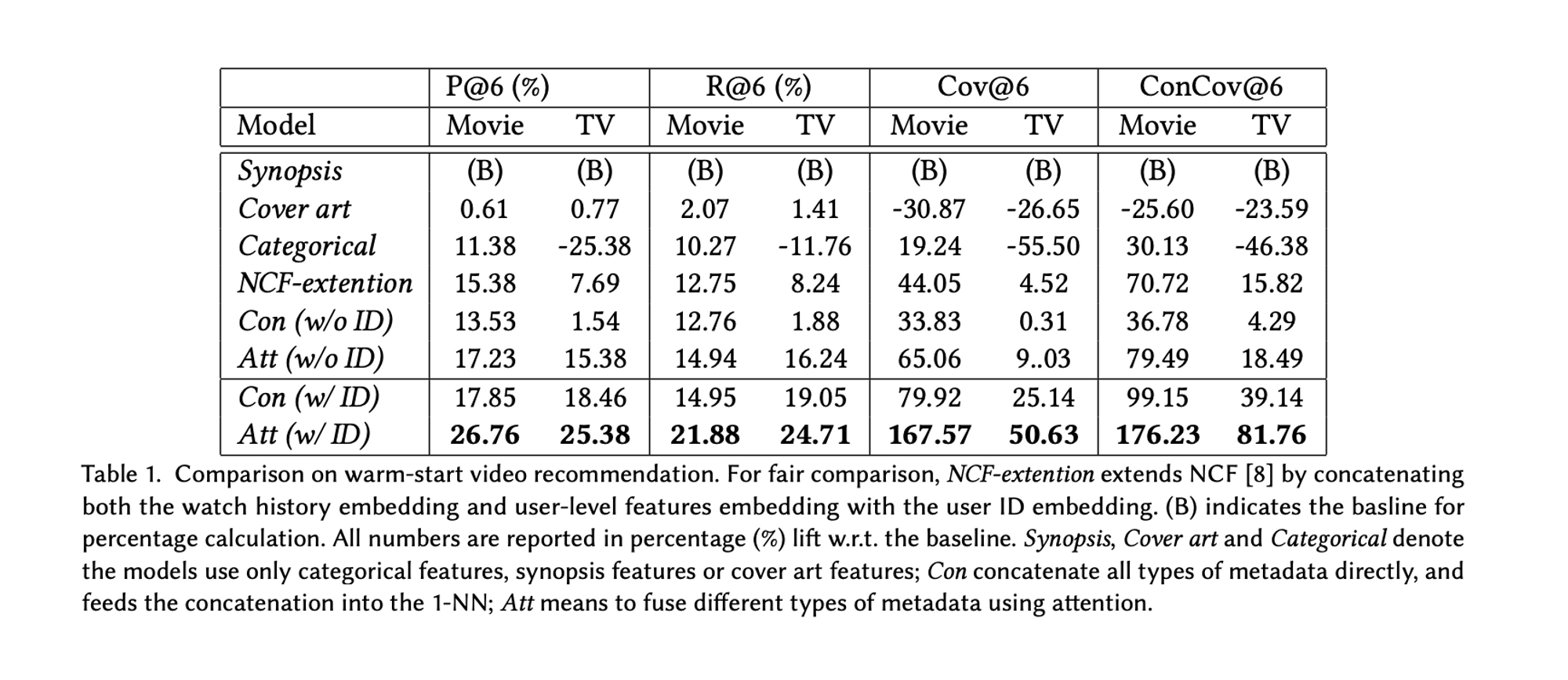
As I see the docs:
"candidate_embeddings: [num_candidates, embedding_dim] tensor of candidate
representations. Normally, num_candidates is the same as
num_queries: there is a positive candidate corresponding for every
query. However, it is also possible for num_candidates to be larger
than num_queries. In this case, the extra candidates will be used an
extra negatives for all queries."
And also based on the paper , I guess the item corpus should be mapped to embeddings, from which B' candidates are randomly selected and concatenated to the B candidates, then they are simply passed to the Retrieval task. For the embedding mapping, did you compute it once at every epoch or at each batch?
It'd be sth like that, when you call the Retrieval Task, you need to have
- The embeddings including the random negatively sampled negatives
- The candidate sampling probability adjusted based on both batch sizes (uniform negatives batch size, original batch size) as in discussed here
The code isn't that optimized, and I'm not 100% sure that this is the correct way :)
def compute_loss(self, features, training=False):
query_embeddings = self.query_model({
a: features[a] for a in self.query_features
})
candidate_embeddings = self.candidate_model({
a: features[a] for a in self.candidate_features
})
## mixed negative sampling
if self.mixed_negative_sampling is not None:
# sampling a uniform negatives from unique candidate features
uniform_negatives = self.unique_candidate_features.sample(self.batch_size)
# calculate the batch embeddings
negatives_embeddings = self.candidate_model(uniform_negatives)
candidate_embeddings = tf.concat([candidate_embeddings, negatives_embeddings], axis=0)
negative_ids = uniform_negatives[self.unique_candidate]
# these probabilities are corrected for the batch sizes
candidate_probability = tf.concat([features['candidate_probability'],
tf.convert_to_tensor(uniform_negatives['candidate_probability'])],
axis=0)
candidate_ids = tf.concat([features[self.unique_candidate],
tf.convert_to_tensor(negative_ids)], axis=0)
return self.task(query_embeddings, candidate_embeddings, compute_metrics= not training,
candidate_sampling_probability=candidate_probability,
candidate_ids=candidate_ids,
sample_weight=sample_weight)
I noticed that you are not passing the training=False parameter to your query and candidate models. If you are using layers that behaves differently during training and testing, this is wrong.
query_embeddings = self.query_model({a: features[a] for a in self.query_features}, training)
candidate_embeddings = self.candidate_model({a: features[a] for a in self.candidate_features}, training)
I have a few questions.
self.unique_candidate_features.sample(self.batch_size)What data structure is this, that have a sample method?- What is
self.unique_candidate?
I implemented MNS as well, however when I turn it on the training does not start if I decorate the train_step() and test_step() functions with @tf.function
def compute_loss(
self,
features: tf.Tensor,
training: bool = False,
compute_metrics: bool = True
) -> tf.Tensor:
"""
:param features:
:param training:
:param compute_metrics:
:return:
"""
# We only pass the user related features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise, the discrepancy in input structure would
# cause an error when loading the query model after saving it.
candidate_embeddings = self.candidate_tower(features, training)
cs_probs = features[self.feature_csp]
sw = 'sample_weight' in features.keys() and training
if self.mixed_negative_sampling:
item_embeddings = tf.concat(
[self.candidate_tower(batch, training) for batch in self.item_dataset],
axis=0
)
indices = tf.range(tf.shape(item_embeddings)[0])
random_indices = tf.random.shuffle(indices)[:self.batch_size_uniform]
global_negatives = tf.gather(item_embeddings, random_indices)
candidate_embeddings = tf.concat(
[candidate_embeddings, global_negatives], axis=0
)
cs_probs_uni = tf.constant(
1.0 / item_embeddings.shape[0],
dtype=tf.float32,
shape=self.batch_size_uniform
)
cs_probs = tf.concat([cs_probs, cs_probs_uni], axis=0)
return self.retrieval_task(
query_embeddings=self.query_tower(features, training),
candidate_embeddings=candidate_embeddings,
compute_metrics=not training,
candidate_sampling_probability=cs_probs,
sample_weight=features['sample_weight'] if sw else None
)
def call(self, features: tf.Tensor, training: bool = False) -> tf.Tensor:
return tf.concat([
self.query_tower(features, training),
self.candidate_tower(features, training)
], axis=1
)
@tf.function
def train_step(self, features):
with tf.GradientTape() as tape:
loss = self.compute_loss(
features, training=True, compute_metrics=False
)
if self.losses:
regularization_loss = tf.add_n(self.losses)
else:
regularization_loss = tf.constant([0.0])
total_loss = loss + regularization_loss
gradients = tape.gradient(total_loss, self.trainable_variables)
self.optimizer.apply_gradients(
zip(gradients, self.trainable_variables)
)
# track just the loss function
return loss
@tf.function
def test_step(self, features, compute_metrics: bool):
# The factorized_metrics argument is used to retrace this function
# when a new set of candidates is computed for evaluation
loss = self.compute_loss(
features, training=False, compute_metrics=compute_metrics
)
if self.losses:
regularization_loss = tf.add_n(self.losses)
else:
regularization_loss = tf.constant([0.0])
total_loss = loss + regularization_loss
return loss, regularization_loss, total_loss
Without MNS, the training works with @tf.function, but when I turn on MNS it doesn't - the training doesn't start and just hangs for eternity. When MNS is turned on and I remove the decorator, the training runs but it is super slow.
@patrickorlando Do you have an idea what can cause this? I would appreciate an advice!
I managed to make it work with @tf.function, by taking out the computations from the compute_loss() function, and passing the global negatives and the corresponding sampling probabilities with the dataset.
However, by computing the candidate embeddings for the whole item corpus (I have around 20k items) at every batch iteration, the number of iterations / sec went down from ~72 to 2.
@OmarMAmin have you experienced similar training time degradation?
Is there anything to do to improve on this? I was thinking that maybe it is enough to re-compute the candidate embeddings after x batches, or once at every epoch. But as the candidate tower's embedding representations change after every gradient update, I doubt if this would work.
@hkristof03, I randomly sample from the corpus using a tf.data.Dataset and then I merge it in using
uniform_negatives = item_ds.cache().repeat().shuffle().batch(uniform_negative_batch_size)
train_with_mns = tf.data.Dataset.zip(train_ds, uniform_negatives)
You don't need to run it for your whole corpus for every batch.
Thanks @patrickorlando for sharing your knowledge with the TF library! It improved on my implementation a lot.
@hkristof03 would you mind sharing some sample code where you use keras tuner to tune the towers and specifically the temperature? I'm having some trouble figuring out how to tune the temperature
@patrickorlando clarification question (I'm a newbie), looks like you sample the candidates prior to training. If my training ds is [query_id, candidate_id], and sampling from the candidate features only have [candidate_id], could I still zip the dataset and pass it to the model?
welcome @zH0me87,
looks like you sample the candidates prior to training
They are not sampled prior to training. This is a tf.data.Dataset, which is a pipeline. The code above specifies that we want to sample batches randomly from the items dataset. The actual sampling happens during training as batches are requested from the dataset generator.
The zip function will return tuples of the two datasets outputs ([query_id, candidate_id], [candidate_id]), your two-tower model class has to implement the code to handle the extra negatives.
@hkristof03 would you mind sharing some sample code where you use keras tuner to tune the towers and specifically the temperature? I'm having some trouble figuring out how to tune the temperature
I also have difficulty applying Kerastuner for the recommendation system. Is there a code snippit or relevant guides for this apart from the Kerastuner documentation? @patrickorlando are you using the kerastuner for optimization?
Many thanks in advance :)
@jillwalker99 I cannot share the code this time as it is private, but I am planning to write a series about the framework that I developed on top of TF recommenders in the future.
But basically I just went through the Keras Tuner tutorials. I usually define a DictConfig from yaml (using Hydra for convenience) from which I build the model instance. Then the same way as in the tutorial you define a function where you set the model's parameters in the DictConfig with HyperParameters, where you set reasonable intervals and possible values. Temperature will be just one hyperparameter. I always save the resulting DictConfig-s back to yaml and to a separate experiment directory from which with a separate parser function I can create a parallel coordinates plot with HiPlot, to check which parameter combinations resulted in good performance metrics.
@hkristof03 Thanks for the great discussion. I implemented the mixed sampling and bias correction on a toy model based on movielens data. In this case, the recall_rate doesn't improve after adding extra random negative samples, but the performance should depends on the specific business scenario and dataset. You may already solve the problems. I hope this helps.