recommenders
 recommenders copied to clipboard
recommenders copied to clipboard
Validation loss increasing but validation metric is improving
I have trained a deep retrieval model for my own data (~3 million records) and I have trained 30 epochs.
I have seen that the "val_loss "decrease over the first few epochs and it is increasing afterwards while "train_loss" is decreasing all the time. However the 'val_factorized_top_k/top_k_categorical_accuracy' is improving over time.
Here are the history I got from the training
'val_loss': [8014.77734375, 7885.28125, 7907.8330078125, 7969.4365234375, 8067.931640625, 8149.6533203125, 8244.7119140625, 8333.19921875, 8430.1044921875, 8520.3896484375, 8618.4736328125, 8707.265625, 8793.5078125, 8870.9580078125, 8948.453125, 9021.32421875, 9098.4072265625, 9163.1103515625, 9231.8291015625, 9284.50390625, 9345.865234375, 9403.099609375, 9460.916015625, 9509.5234375, 9557.9970703125, 9608.4462890625, 9654.29296875, 9700.2646484375, 9740.9912109375, 9786.341796875],
'val_factorized_top_k/top_100_categorical_accuracy': [0.02200424112379551, 0.02866148203611374, 0.03169553354382515, 0.0347590446472168, 0.0349946990609169, 0.03891245275735855, 0.03905973955988884, 0.04182868078351021, 0.0411217138171196, 0.04427359625697136, 0.043596088886260986, 0.04586426168680191, 0.04568752273917198, 0.0474843867123127, 0.04692470654845238, 0.049428537487983704, 0.048957228660583496, 0.050135500729084015, 0.04992930218577385, 0.051431600004434586, 0.050695180892944336, 0.052020736038684845, 0.05146105960011482, 0.05234476178884506, 0.05199128016829491, 0.05311064049601555, 0.052374217659235, 0.053611405193805695, 0.05328737944364548, 0.05449511110782623],
Also here is the screenshot I got from the tensorboard.
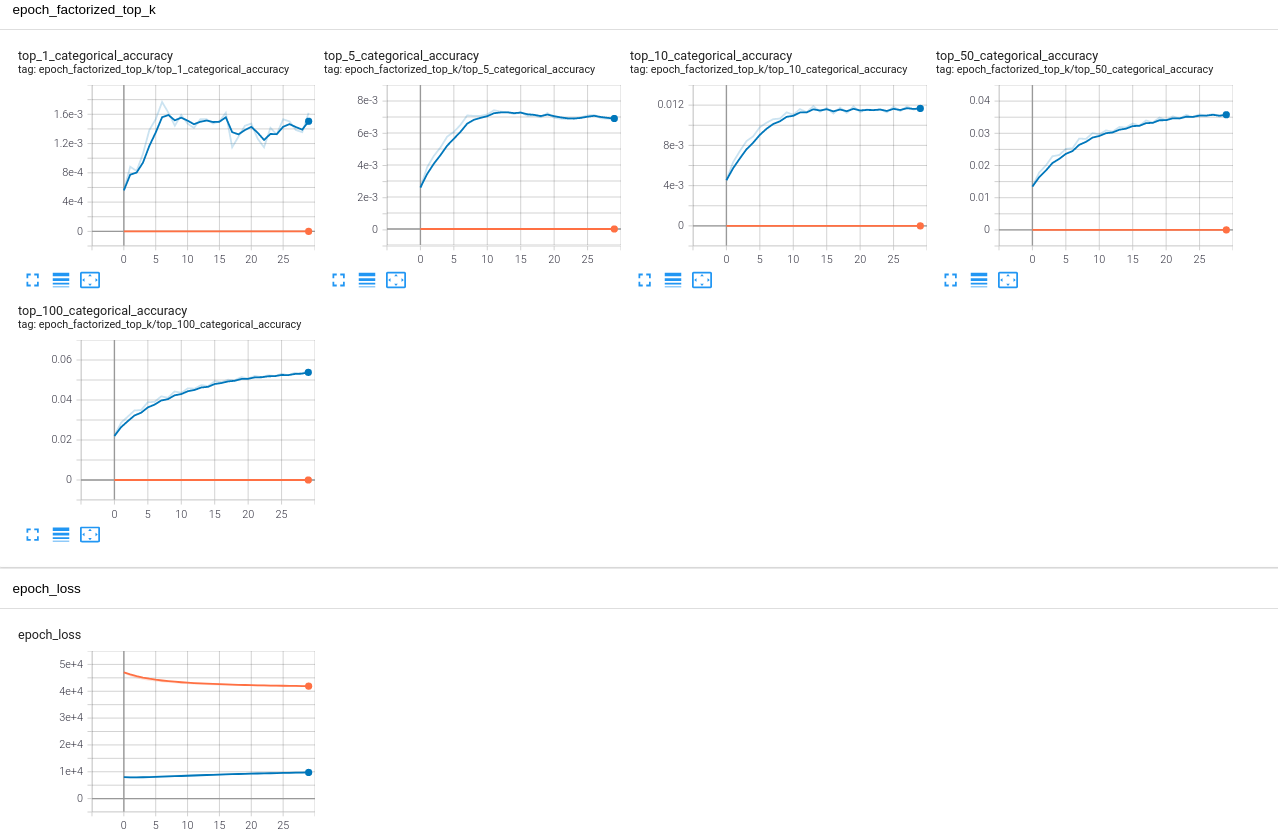
Is there any good explanation why that is the case? I am quite confused here.
I observed a similar effect and noticed others have as well. I overcame this with what follows.
- I made sure my splitting strategy was sensible in that my dev (validation) and test (evaluation) sets followed similar distributions. Since my train set is sampled from a historical interaction window up to time T and my dev/test sets are sampled from interactions for a smaller future window after time T, there exists natural interaction drift but not enough to pose issues (in my case).
- I made sure to combat overfitting by adding data, regularization, reducing model capacity, etc.
- I applied candidate_sampling_probability to minimize negative sampling candidate popularity bias. TFRS implements substantial functionality discussed in this research paper and this topic is outlined both, theoretically and practically.
- I used a multi-task network minimizing a weighted combination of retrieval and ranking loss.