addons
 addons copied to clipboard
addons copied to clipboard
your ciou customer op according to the ciou paper seems to have the same mistake the paper have.
System information
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
- TensorFlow version and how it was installed (source or binary):
- TensorFlow-Addons version and how it was installed (source or binary):
- Python version:
- Is GPU used? (yes/no): no Describe the bug your ciou customer op according to the ciou paper seems to have the same mistake the paper have.
A clear and concise description of what the bug is.
in the ciou paper <<Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression>> https://arxiv.org/abs/1911.08287 , the deviation of v w.r.t w and h was descriped below:
 but after my manual calculation the deviation of v w.r.t w was below:
but after my manual calculation the deviation of v w.r.t w was below:
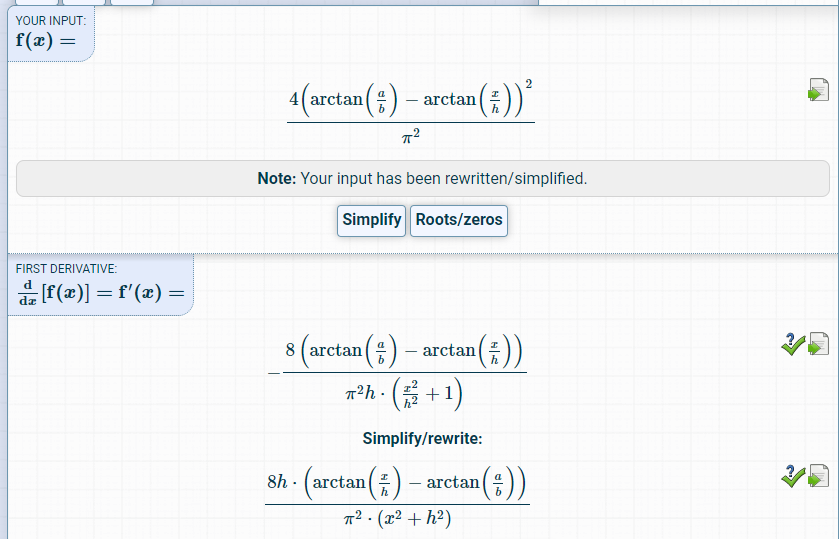 that means the dv/dw should have a negative sign, and the dv/dh should not.
that means the dv/dw should have a negative sign, and the dv/dh should not.
your ciou customer op is in https://github.com/tensorflow/addons/pull/914/files the key codes about ciou op are below:
def _get_v(
b1_height: CompatibleFloatTensorLike,
b1_width: CompatibleFloatTensorLike,
b2_height: CompatibleFloatTensorLike,
b2_width: CompatibleFloatTensorLike,
) -> tf.Tensor:
@tf.custom_gradient
def _get_grad_v(height, width):
arctan = tf.atan(tf.math.divide_no_nan(b1_width, b1_height)) - tf.atan(
tf.math.divide_no_nan(width, height)
)
v = 4 * ((arctan / math.pi) ** 2)
def _grad_v(dv):
gdw = dv * 8 * arctan * height / (math.pi ** 2)
gdh = -dv * 8 * arctan * width / (math.pi ** 2)
return [gdh, gdw]
return v, _grad_v
return _get_grad_v(b2_height, b2_width)
gdw = dv * 8 * arctan * height / (math.pi ** 2) miss a negative sign gdh =-dv * 8 * arctan * width / (math.pi ** 2) should remove the negative sign
the correct code should be :
def _get_v(
b1_height: CompatibleFloatTensorLike,
b1_width: CompatibleFloatTensorLike,
b2_height: CompatibleFloatTensorLike,
b2_width: CompatibleFloatTensorLike,
) -> tf.Tensor:
@tf.custom_gradient
def _get_grad_v(height, width):
arctan = tf.atan(tf.math.divide_no_nan(b1_width, b1_height)) - tf.atan(
tf.math.divide_no_nan(width, height)
)
v = 4 * ((arctan / math.pi) ** 2)
def _grad_v(dv):
gdw = -dv * 8 * arctan * height / (math.pi ** 2)
gdh = dv * 8 * arctan * width / (math.pi ** 2)
return [gdh, gdw]
return v, _grad_v
return _get_grad_v(b2_height, b2_width)
Code to reproduce the issue here is my manual deviation test:
import tensorflow as tf
PI=tf.math.asin(1.)*2
with tf.GradientTape() as tape:
w=tf.Variable(0.5,dtype=tf.float32)
h=tf.Variable(0.1,dtype=tf.float32)
v = 4/PI/PI* tf.square(tf.math.atan(tf.math.divide_no_nan(1., 1.))-tf.math.atan(tf.math.divide_no_nan(w, h)))
theory= 4/PI/PI* 2*(tf.math.atan(1./1.)-tf.math.atan(tf.math.divide_no_nan(w, h)))*(-1)*h/(h**2+w**2)
grad_dv_dw=tape.gradient(v, w)
print(theory.numpy(),grad_dv_dw.numpy())
z=math.pi/4
PI=tf.math.asin(1.)*2
with tf.GradientTape() as tape:
w=tf.Variable(0.5,dtype=tf.float32)
h=tf.Variable(0.1,dtype=tf.float32)
v = 4/PI/PI*tf.square(tf.math.atan(tf.math.divide_no_nan(1., 1.))
-tf.math.atan(tf.math.divide_no_nan(w, h)))
grad_dv_dwdh=tape.gradient(v, [w,h])
print('scale:',(tf.square(w) + tf.square(h)).numpy())
theorical_dv_dw=(-1.)*h*8/tf.pow(PI,2)*(tf.math.atan(tf.math.divide_no_nan(1., 1.))
-
tf.math.atan(tf.math.divide_no_nan(w, h)))/(tf.square(w) + tf.square(h))
theorical_dv_dh=w*8/tf.pow(PI,2)*(tf.math.atan(tf.math.divide_no_nan(1., 1.))
-
tf.math.atan(tf.math.divide_no_nan(w, h)))/(tf.square(w) + tf.square(h))
print("tf dv/dw dv/dh",[_.numpy() for _ in grad_dv_dwdh])
print('theorical dv/dw dv/dh:',theorical_dv_dw.numpy(),theorical_dv_dh.numpy())
tensorflow console shows:
0.18331422 0.18331422
scale: 0.26
tf dv/dw dv/dh [0.18331422, -0.9165711]
theorical dv/dw dv/dh: 0.18331422 -0.9165711
but when i switch yolov3 ciou algorithm from tensorflow.addon (https://github.com/tensorflow/addons/pull/914/files#diff-f980d3eb2d746478b7664e652682ab3c62b24b7644559b9d5d4849087ec25d91) to mine own one, the model converge in the first epoch, but get nan in the second epoch~~something wents wrong! your code runs well but is not consistent with manual caculation,hope you guy check that whether it is a bug,or i do something wrong. thanks
btw, your customer op works well, while other implementation using tf.stop_gradient function to eliminate the scale factor (w2+h2), suffer in NaN. Provide a reproducible test case that is the bare minimum necessary to generate the problem.
Other info / logs
Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.
Maybe you should tell the paper's author about it. I used a custom gradient in order to align with paper.
hi, thank your for you reply, i have post it to the author's github the same time i post here~~~ https://github.com/Zzh-tju/DIoU/issues/19 i post here, because your customer gradient implementation of ciou works better than other implementations using tf.stop_gradient, i think maybe you know the relationship of the deviation equation and the code of def _grad_v(dv) inside _get_v function, you do the coding on purpose~~ would you please check the deviation above?~~~is the deviation of v w.r.t w wrong? can you see the weird different between the deviation of v w.r.t w and the code inside def _grad_v(dv)?
TensorFlow Addons is transitioning to a minimal maintenance and release mode. New features will not be added to this repository. For more information, please see our public messaging on this decision: TensorFlow Addons Wind Down
Please consider sending feature requests / contributions to other repositories in the TF community with a similar charters to TFA: Keras Keras-CV Keras-NLP