cube-studio
 cube-studio copied to clipboard
cube-studio copied to clipboard
Grafana模块监控异常

日志如下:
t=2022-06-09T14:16:26+0800 lvl=eror msg="Request Completed" logger=context userId=0 orgId=1 uname= method=GET path=/api/datasources/proxy/1/api/v1/query_range status=502 remote_addr=10.168.2.252 time_ms=30002 size=0 referer="http://10.168.2.252/grafana/d/all-node/all-node?orgId=1&refresh=5s" t=2022-06-09T14:16:26+0800 lvl=eror msg="Data proxy error" logger=data-proxy-log userId=0 orgId=1 uname= path=/api/datasources/proxy/1/api/v1/query_range remote_addr=10.168.2.252 referer="http://10.168.2.252/grafana/d/all-node/all-node?orgId=1&refresh=5s" error="http: proxy error: dial tcp 10.43.83.231:9090: i/o timeout" t=2022-06-09T14:16:26+0800 lvl=eror msg="Request Completed" logger=context userId=0 orgId=1 uname= method=GET path=/api/datasources/proxy/1/api/v1/query_range status=502 remote_addr=10.168.2.252 time_ms=30001 size=0 referer="http://10.168.2.252/grafana/d/all-node/all-node?orgId=1&refresh=5s" t=2022-06-09T14:16:31+0800 lvl=eror msg="Alert Rule Result Error" logger=alerting.evalContext ruleId=1 name="System load alert" error="alert execution exceeded the timeout" changing state to=alerting
查到一个贴子:https://grafana.docs.cern.ch/4._Troubleshooting/2-proxy-error-context-canceled/
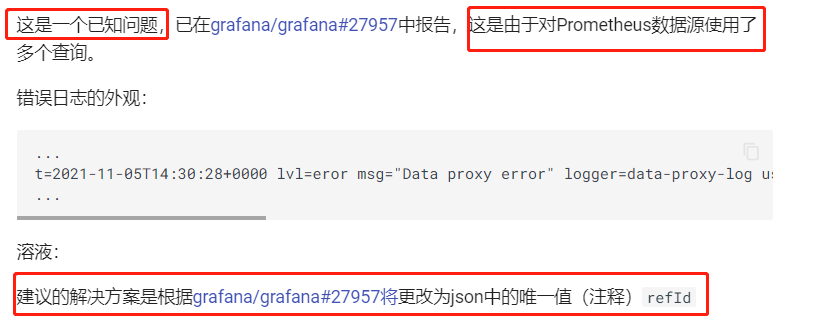 还是不大明白,这个贴子说的是让改哪个js代码?
还是不大明白,这个贴子说的是让改哪个js代码?
grafana 可以看到界面包含了几个地方的功能需要: 1、每个机器的采集器是否正常 包含node-export/dcgm-exporter(gpu) 2、prometheus是否正常,可以在prometheus里面看数据是否正常 3、查看grafana是否正常,主要是看板的配置 4、最后是网关带来了grafana的url访问
从你的截图里面看,应该grafana链接不上prometheus,所以怀疑是你的prometheus未正常启动
prometheus正常启动着呢
 日志里面有一些警告,不知道有没有影响
level=warn ts=2022-06-14T04:58:58.12469297Z caller=klog.go:86 component=k8s_client_runtime func=Warningf msg="/app/discovery/kubernetes/kubernetes.go:262: watch of *v1.Endpoints ended with: too old resource version: 3201509 (3202538)"
level=info ts=2022-06-14T05:00:03.954078526Z caller=compact.go:496 component=tsdb msg="write block" mint=1655172000000 maxt=1655179200000 ulid=01G5G9ADRC0DSEC1K1KEM5TZ81 duration=3.301850879s
level=info ts=2022-06-14T05:00:04.202635464Z caller=head.go:536 component=tsdb msg="head GC completed" duration=108.122048ms
level=info ts=2022-06-14T05:00:09.252410301Z caller=head.go:583 component=tsdb msg="WAL checkpoint complete" first=173 last=175 duration=5.049629249s
日志里面有一些警告,不知道有没有影响
level=warn ts=2022-06-14T04:58:58.12469297Z caller=klog.go:86 component=k8s_client_runtime func=Warningf msg="/app/discovery/kubernetes/kubernetes.go:262: watch of *v1.Endpoints ended with: too old resource version: 3201509 (3202538)"
level=info ts=2022-06-14T05:00:03.954078526Z caller=compact.go:496 component=tsdb msg="write block" mint=1655172000000 maxt=1655179200000 ulid=01G5G9ADRC0DSEC1K1KEM5TZ81 duration=3.301850879s
level=info ts=2022-06-14T05:00:04.202635464Z caller=head.go:536 component=tsdb msg="head GC completed" duration=108.122048ms
level=info ts=2022-06-14T05:00:09.252410301Z caller=head.go:583 component=tsdb msg="WAL checkpoint complete" first=173 last=175 duration=5.049629249s
kubeflow-prometheus-adapter运行正常

日志报这个错 E0614 06:59:25.408045 1 provider.go:229] unable to update list of all metrics: unable to fetch metrics for query "{name="DCGM_FI_DEV_GPU_UTIL",exported_pod!="",exported_namespace="service"}": Get "http://prometheus-k8s.monitoring.svc:9090/api/v1/series?match%5B%5D=%7B__name__%3D%22DCGM_FI_DEV_GPU_UTIL%22%2Cexported_pod%21%3D%22%22%2Cexported_namespace%3D%22service%22%7D&start=1655189875.407": dial tcp 10.43.83.231:9090: i/o timeout
