stanford_alpaca
 stanford_alpaca copied to clipboard
stanford_alpaca copied to clipboard
about v100 save model
I use the 8 v100 train the model, the saved model is error, the size of model is :
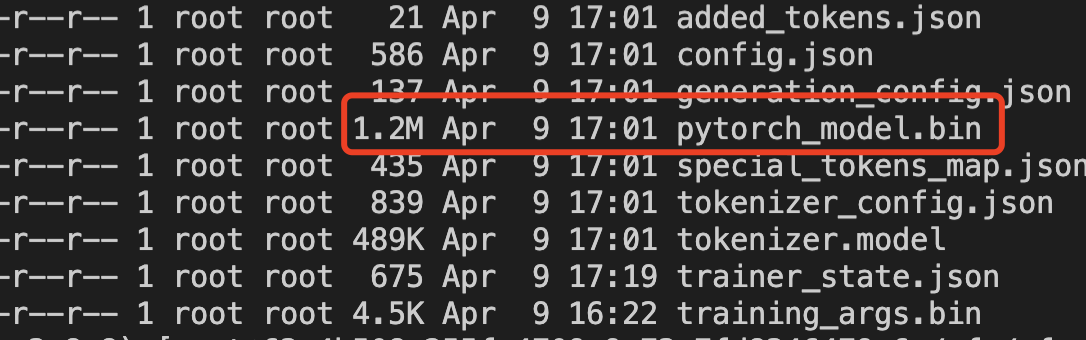
the command is as follows
torchrun --nproc_per_node=1 --master_port=12345 train.py
--model_name_or_path /cfs/cfs-4q3ifcxl/saminyang/model_torch/LLaMA/7B/convert
--data_path ./data/test.json
--bf16 False
--output_dir output/7B_chinese
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 False
--deepspeed ./deepspeed-cfg/ZeRO-3.json
but
hey man, how much GPU memory your device uses. My devices are two A10 with 48GB, but there is an OOM error.
You can use alpaca-lora. Here I have curated latest fine tuned libraries and models awesome-llms. It can be trained on consumer devices having 24 GB of GPU.
if you are using: https://github.com/tatsu-lab/stanford_alpaca/blob/main/train.py,
then
in line 218: replace trainer.save_model(output_dir=training_args.output_dir)
with
checkpoint_dir = os.path.join(training_args.output_dir, "checkpoint-final")
trainer.deepspeed.save_checkpoint(checkpoint_dir)
then, checkpoint-final will contains zero_to_fp32.py after the training is done.
just run python zero_to_fp32.py . pytorch_model.bin
for more information, look here: https://huggingface.co/transformers/v4.10.1/main_classes/deepspeed.html#getting-the-model-weights-out