solana
 solana copied to clipboard
solana copied to clipboard
rpc request timed out and stuck
the current instance type
aws ec2
r6i.8xlarge
disk
gp3 2048
script to run
#!/bin/bash
#mainnet sol
export SOLANA_METRICS_CONFIG="host=https://metrics.solana.com:8086,db=mainnet-beta,u=mainnet-beta_write,p=password"
exec solana-validator \
--identity ~/validator-keypair.json \
--vote-account ~/vote-account-keypair.json \
--known-validator 7Np41oeYqPefeNQEHSv1UDhYrehxin3NStELsSKCT4K2 \
--known-validator GdnSyH3YtwcxFvQrVVJMm1JhTS4QVX7MFsX56uJLUfiZ \
--known-validator DE1bawNcRJB9rVm3buyMVfr8mBEoyyu73NBovf2oXJsJ \
--known-validator CakcnaRDHka2gXyfbEd2d3xsvkJkqsLw2akB3zsN1D2S \
--only-known-rpc \
--no-port-check \
--full-rpc-api \
--enable-cpi-and-log-storage \
--ledger /data/SOL/ledger \
--enable-rpc-transaction-history \
--rpc-port 8899 \
--dynamic-port-range 8000-8020 \
--entrypoint entrypoint.mainnet-beta.solana.com:8001 \
--entrypoint entrypoint2.mainnet-beta.solana.com:8001 \
--entrypoint entrypoint3.mainnet-beta.solana.com:8001 \
--entrypoint entrypoint4.mainnet-beta.solana.com:8001 \
--entrypoint entrypoint5.mainnet-beta.solana.com:8001 \
--expected-genesis-hash 5eykt4UsFv8P8NJdTREpY1vzqKqZKvdpKuc147dw2N9d \
--no-voting \
--log /data/SOL/ledger/solana-validator.log \
--wal-recovery-mode skip_any_corrupted_record \
--limit-ledger-size
problem lies in
1、Upgrade to Mainnet - v1.10.32 latest sh -c "$(curl -sSfL https://release.solana.com/v1.10.32/install)" 2、After restarting and running for a while, when I use the interface to request port 8899, it has been stuck with no data
curl -s -X POST -H "Content-Type: application/json" -d '{"jsonrpc":"2.0","id":1, "method":"getEpochInfo"}' http://localhost:8899|jq

Is there any solution to my problem?
I encountered the same issue with the same hardware and the 1.10.32 version.
It seems like the hardware resources are sufficient, but the rpc request got stuck after the node running for a while.
@dudebing99 Have you solved it now, my current node is not back to normal yet
Nope. I've no idea how to solve the problem. Restart the node and it will work normally only for a while ...
In the same situation as me, I don't know how to solve the problem, and the official discord didn't reply to my question.
I've been doing this for three days, same problem, up for half an hour, then dead with no error.Using r6i.12xlarge is the same problem.
The testnet seems well, but the mainnet has the problem. I tried for sevseral versions but none worked.
@airstring I don't know how to solve this problem, is your node still normal?
@Tab-ops I changed the type to r6i.12xlarge.The process will not stop and will always be normal.But sometimes the service is accessible and sometimes it is not.
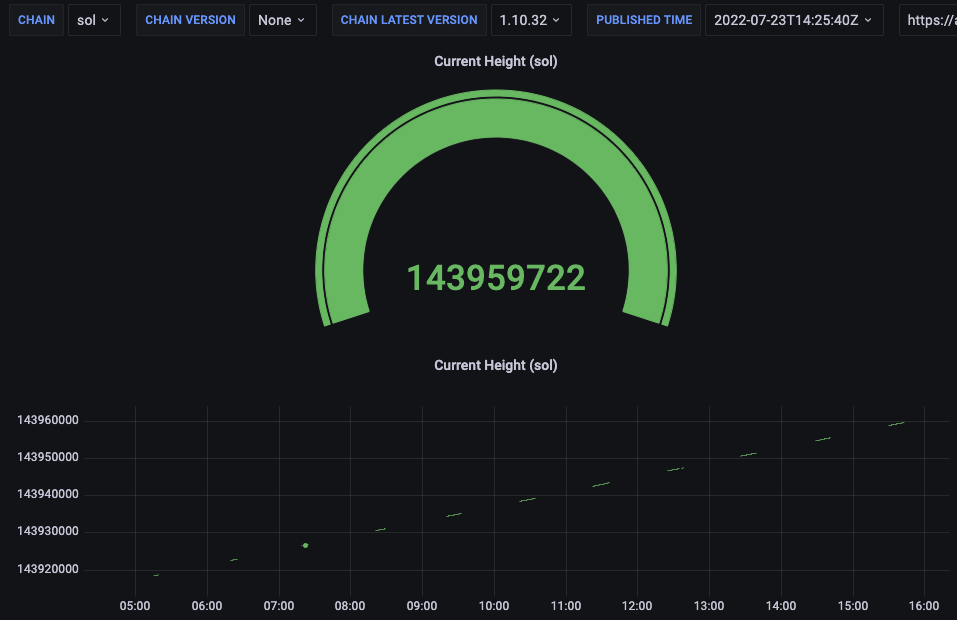
i ended up just creating a cron job to restart the process every 2 hours. Not ideal but better than nothing
It makes no sence without data integrity for me, besides it lasts too long before the rpc service ready while restarting the node.
yeah, this bandaid probably isn't for everybody. Was just trying something to make it a tiny bit better until the problem is fixed
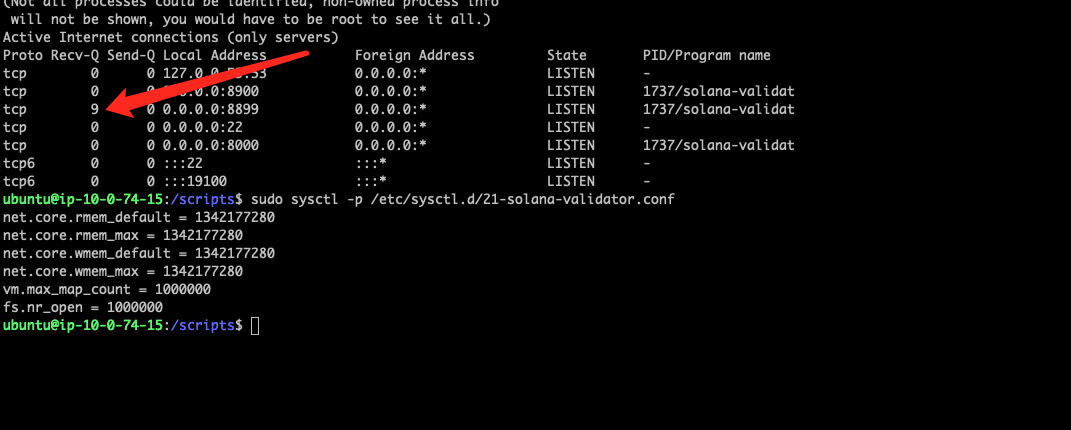
I thought it was the problem of my UDP buffer size, but it didn't seem to be the case, and I adjusted the system parameters according to the official operation. My Recv-Q value is very high, and it feels like this affects my rpc response
Have any of you checked your validator logs to determine if your node is still progressing and making roots? ie. is this a validator issue or an RPC service issue
Also, what version were you upgrading from?
@CriesofCarrots Upgrading from version Mainnet - v1.10.29, feels like it's under attack, sync is slow, and rpc interface doesn't respond
please help us @jeffwashington @mvines @garious @CriesofCarrots @jstarry @jackcmay @solana-labs We have been out of service for over a week now,please help !!!!!
It would be helpful to know if any older versions have the same issue. Can you try versions v1.10.31 and lower to see when the issue started?
Any other information about the behavior of your server / request logs before the issue starts would be helpful too
I haven't seen this in any of our servers yet, I've asked to the RPC operators if any has hit it again.
Hey we were experiencing this on 1.10.28, 1.10.32 and 1.10.34 and it had started around 7/27.
Our Node:
CPU: AMD Epyc 7313 (16 Cores)
RAM: 512GB
Disk: 4TB+ NVME SSD
Account indexes: spl-token-mint, spl-token-owner, program-id
Account index exclude: kinXdEcpDQeHPEuQnqmUgtYykqKGVFq6CeVX5iAHJq6 (only)
After looking at our data, 2 things were happening at the same time.
1. Our WS usage increased significantly as shown below (nothing to do with Validator):
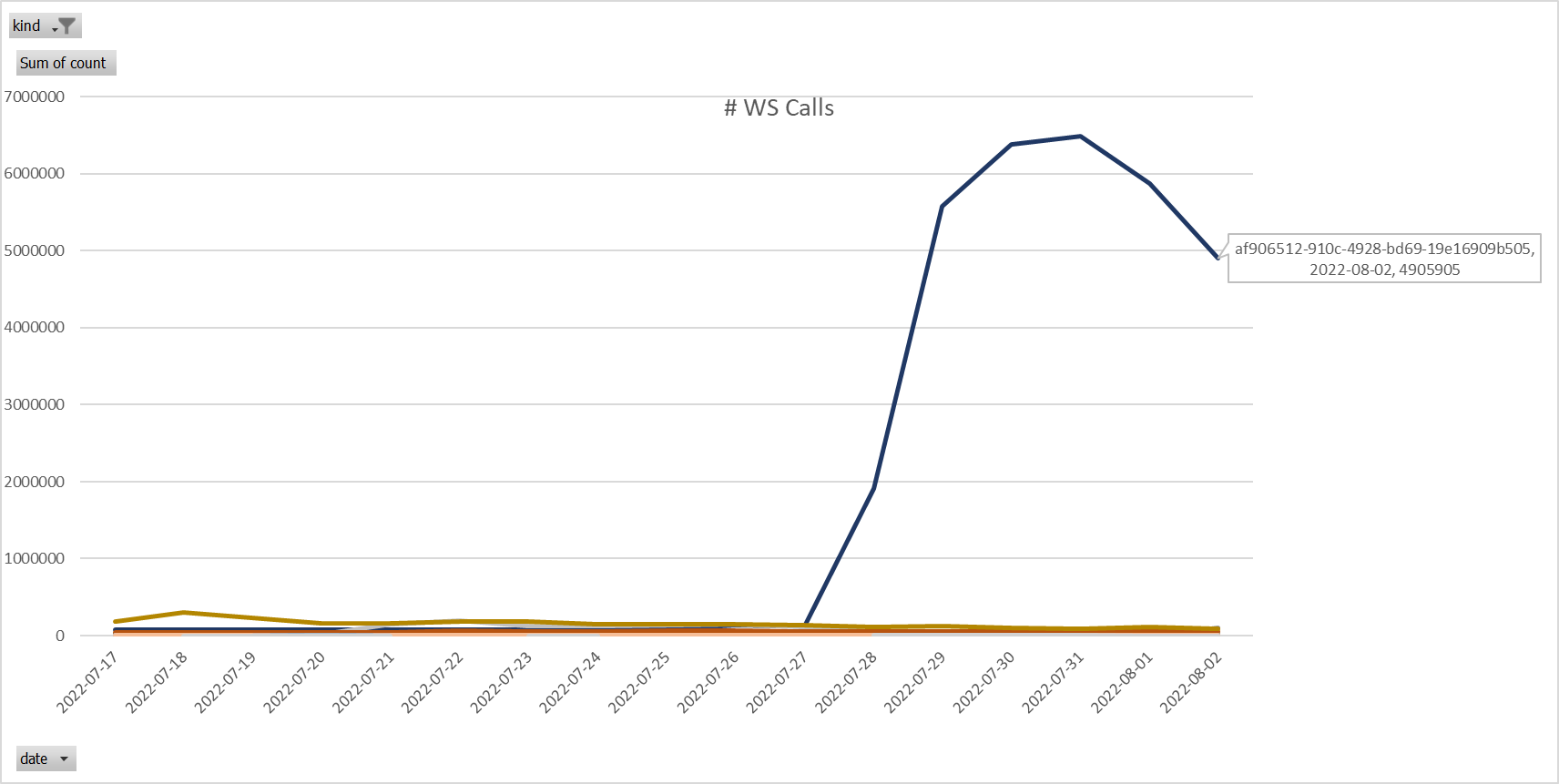
This was due to a rogue customer. We addressed this.
2. Our nodes were running OOM even at 512GB RAM which caused pauses/crashes:
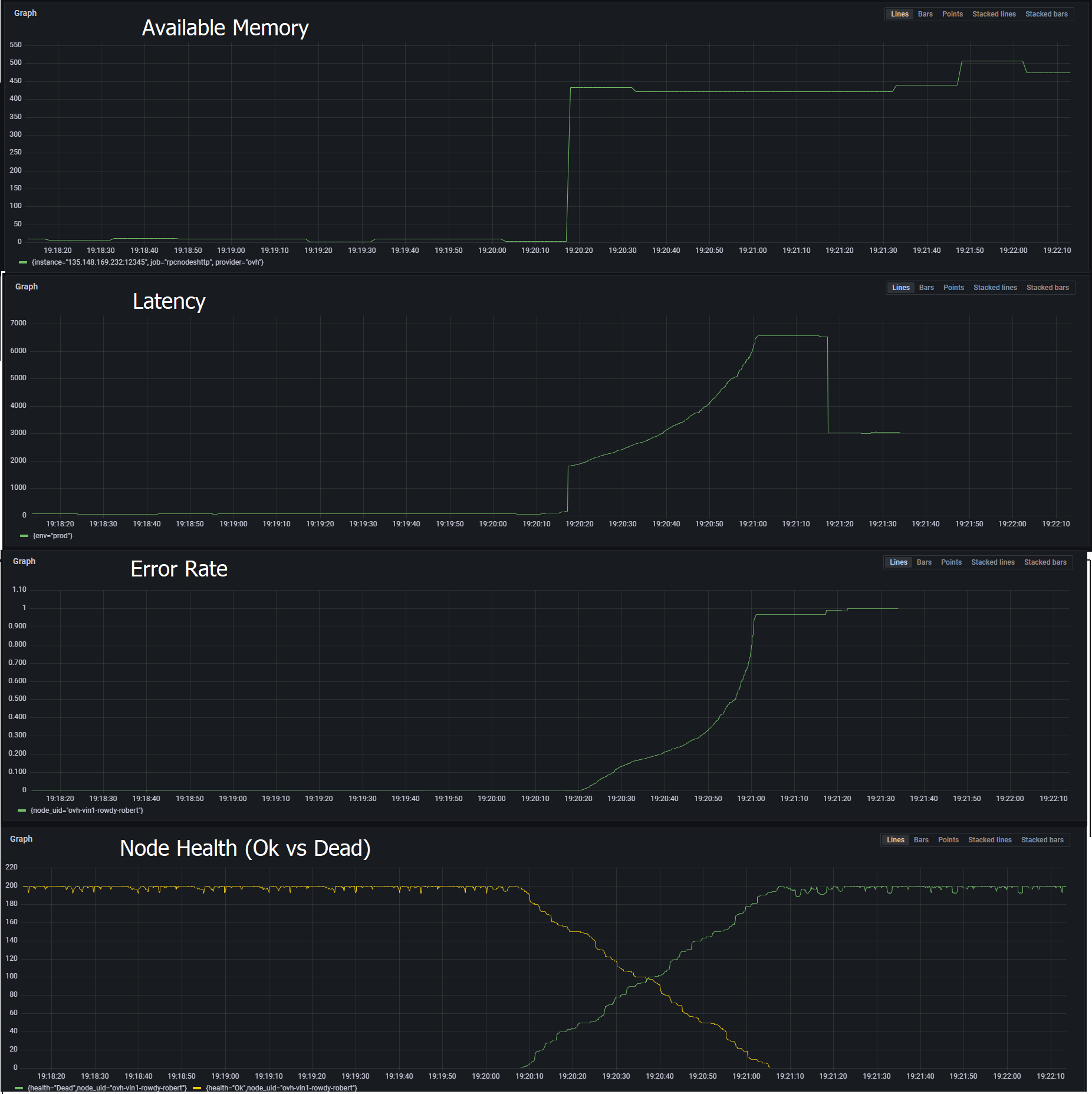
We have since increased SWAP space to 200GB which has subsided our pausing/crashing problems.
Solution?
We are now just making sure we have enough memory (including SWAP) to ensure these pauses/crashes don't happen. All nodes are running 1.10.34. It seems to be working thus far but may just be a bandaid for a much larger problem. The fact that we're over 600-700GB in memory usage (RAM + SWAP) consistently (and growing) may point to a memory leak of some sort?
Hopefully this helps.
please help us @jeffwashington @mvines @garious @CriesofCarrots @jstarry @jackcmay @solana-labs We have been out of service for over a week now,please help !!!!!
Have you solved it?
@ultd , do you have any data about the specific RPC requests your node was serving when you saw the issue?
@airstring Our self-built node has been deleted, and we are now using the managed node service