kmq
 kmq copied to clipboard
kmq copied to clipboard
Kafka-based message queue
Kafka Message Queue

![]()
Using kmq you can acknowledge processing of individual messages in Kafka, and have unacknowledged messages
re-delivered after a timeout.
This is in contrast to the usual Kafka offset-committing mechanism, using which you can acknowledge all messages up to a given offset only.
If you are familiar with Amazon SQS, kmq implements a similar message processing
model.
How does this work?
For a more in-depth overview see the blog: Using Kafka as a message queue, and for performance benchmarks: Kafka with selective acknowledgments (kmq) performance & latency benchmark
The acknowledgment mechanism uses a marker topic, which should have the same number of partitions as the "main"
data topic (called the queue topic). The marker topic is used to track which messages have been processed, by
writing start/end markers for every message.
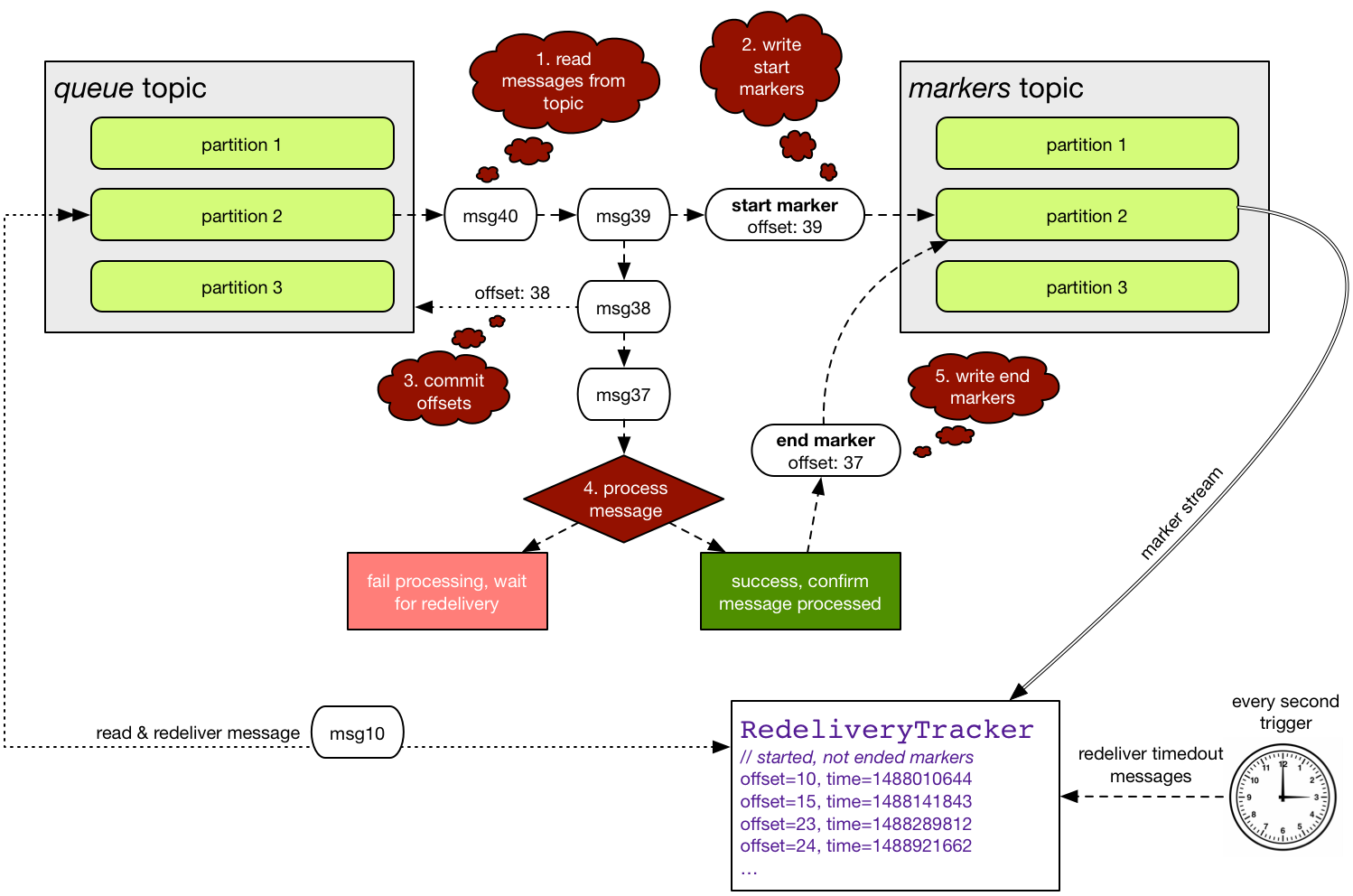
Using kmq
An application using kmq should consist of the following components:
- a number of
RedeliveryTrackers. This components consumes themarkertopic and redelivers messages if appropriate. Multiple copies should be started in a cluster for fail-over. Uses automatic partition assignment. - components which send data to the
queuetopic to be processed - queue clients, either custom or using the
KmqClient
Maven/SBT dependency
SBT:
"com.softwaremill.kmq" %% "core" % "0.2"
Maven:
<dependency>
<groupId>com.softwaremill.kmq</groupId>
<artifactId>core_2.13</artifactId>
<version>0.2</version>
</dependency>
Note: The supported Scala versions are: 2.12, 2.13.
Client flow
The flow of processing a message is as follow:
- read messages from the
queuetopic, in batches - write a
startmarker to themarkerstopic for each message, wait until the markers are written - commit the biggest message offset to the
queuetopic - process messages
- for each message, write an
endmarker. No need to wait until the markers are written.
This ensures at-least-once processing of each message. Note that the acknowledgment of each message (writing the
end marker) can be done for each message separately, out-of-order, from a different thread, server or application.
Example code
There are three example applications:
example-java/embedded: a single java application that starts all three components (sender, client, redelivery tracker)example-java/standalone: three separate runnable classes to start the different componentsexample-scala: an implementation of the client using reactive-kafka
Time & timestamps
How time is handled is crucial for message redelivery, as messages are redelivered after a given amount of time passes
since the start marker was sent.
To track what was sent when, kmq uses Kafka's message timestamp. By default this is messages create time
(message.timestamp.type=CreateTime), but for the markers topic, it is advisable to switch this to LogAppendTime.
That way, the timestamps more closely reflect when the markers are really written to the log, and are guaranteed to be
monotonic in each partition (which is important for redelivery - see below).
To calculate which messages should be redelivered, we need to know the value of "now", to check which start markers
have been sent later than the configured timeout. When a marker has been received from a partition recently, the
maximum such timestamp is used as the value of "now" - as it indicates exactly how far we are in processing the
partition. What "recently" means depends on the useNowForRedeliverDespiteNoMarkerSeenForMs config setting. Otherwise,
the current system time is used, as we assume that all markers from the partition have been processed.
Project status
Version 0.2.1 (5 Sep 2017)
- Kafka & dependency updates
Version 0.2 (19 Jun 2017)
- redelivery component optimizations
- bug fixes
Version 0.1 (24 Apr 2017)
- initial release