a-PyTorch-Tutorial-to-Image-Captioning
 a-PyTorch-Tutorial-to-Image-Captioning copied to clipboard
a-PyTorch-Tutorial-to-Image-Captioning copied to clipboard
RuntimeError : CUDA error: out of memory
Thanks for your instructions and source code! I have been trying to train the model, but I have got a problem. In train.py, the bug goes like this:
in line 81 in main() decoder = decoder.to(device) ... RuntimeError: CUDA error: out of memory
File "train.py", line 81, in main decoder = decoder.to(device) _File "/home/larrydong/anaconda3/envs/pt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 432, in to return self._apply(convert) File "/home/larrydong/anaconda3/envs/pt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 208, in _apply module._apply(fn) File "/home/larrydong/anaconda3/envs/pt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 208, in _apply module._apply(fn) File "/home/larrydong/anaconda3/envs/pt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 230, in _apply param_applied = fn(param) File "/home/larrydong/anaconda3/envs/pt/lib/python3.7/site-packages/torch/nn/modules/module.py", line 430, in convert return t.to(device, dtype if t.is_floating_point() else None, non_blocking)_ **RuntimeError: CUDA error: out of memory** )
As you can see, this indicates that CUDA has run out its memory. But I have been supervising the GPU throughout my training process, this error arises before any taken of resources of my GPU.
I have searched for methods to solve this issue, includeing using with torch.no_grad(), I have also tried to set the GPU before running:
CUDA_VISIBLE_DEVICES = 0
But these methods did not help at all. the problem still exists, I could not even get the training process started.
My GPU is RTX 2080 Ti whose memory is sufficient. I just don't understand why this exists.
Looking forward to anybody's reply on this :(
RTX 2080 Ti has only 11GB of memory. This is not much but would be enough if one uses small enough batch size (16, 32, or 64). What's the batch size that you used when this error occurred? Have you tried reducing it and train the model? As you can already see from the traceback, the error starts when you move the decoder to the GPU. And which version of torch are you using?
RTX 2080 Ti has only 11GB of memory. This is not much but would be enough if one uses small enough batch size (16, 32, or 64). What's the batch size that you used when this error occurred? Have you tried reducing it and train the model? As you can already see from the traceback, the error starts when you move the decoder to the GPU. And which version of torch are you using?
Thank you for your reply! I am using batch size of 32, which seems small enough. Actually I have tried to set the batch_size 16, but it did not help, either.
The torch version is 1.2.0.
Now I have changed the version of torch to 0.4.1, and python 3.6 as the instruction goes. Now the error has changed:
File "train.py", line 332, in <module> │ main() │ File "train.py", line 117, in main │ epoch=epoch) │ File "train.py", line 163, in train │ for i, (imgs, caps, caplens) in enumerate(train_loader): │ File "/home/larrydong/anaconda3/envs/tya/lib/python3.6/site-packages/torch/utils/data/dataloader.py", l│ ine 336, in __next__ │ return self._process_next_batch(batch) │ File "/home/larrydong/anaconda3/envs/tya/lib/python3.6/site-packages/torch/utils/data/dataloader.py", l│ ine 357, in _process_next_batch │ raise batch.exc_type(batch.exc_msg) │ RuntimeError: Traceback (most recent call last): │ File "/home/larrydong/anaconda3/envs/tya/lib/python3.6/site-packages/torch/utils/data/dataloader.py", l│ ine 133, in _worker_manager_loop │ batch = pin_memory_batch(batch) │ File "/home/larrydong/anaconda3/envs/tya/lib/python3.6/site-packages/torch/utils/data/dataloader.py", l│ ine 200, in pin_memory_batch │ return [pin_memory_batch(sample) for sample in batch] │ File "/home/larrydong/anaconda3/envs/tya/lib/python3.6/site-packages/torch/utils/data/dataloader.py", l│ ine 200, in <listcomp> │ return [pin_memory_batch(sample) for sample in batch] │ File "/home/larrydong/anaconda3/envs/tya/lib/python3.6/site-packages/torch/utils/data/dataloader.py", l│ ine 194, in pin_memory_batch │ return batch.pin_memory() │ RuntimeError: cuda runtime error (2) : out of memory at /pytorch/aten/src/THC/THCCachingHostAllocator.cpp│ :271
I searched on google and found that this can be solved by reducing batch_size, but this error stil exists even I set the batch_size equals 1.
I really have no idea why this occurs :(
I'm also using a 2080 TI and have no issues. But the gpu has some problems with pytorch for cuda version after 10. Did you try to run other pytorch models and do they work?
Also it would be interesting to have a look at the output of nvidia-smi
I'm also using a 2080 TI and have no issues. But the gpu has some problems with pytorch for cuda version after 10. Did you try to run other pytorch models and do they work? Also it would be interesting to have a look at the output of nvidia-smi
Yes, I ran the image-classifiaction model based on pytorch before, but the model was much smaller than this.
The nvidia-smi is working nomarlly:
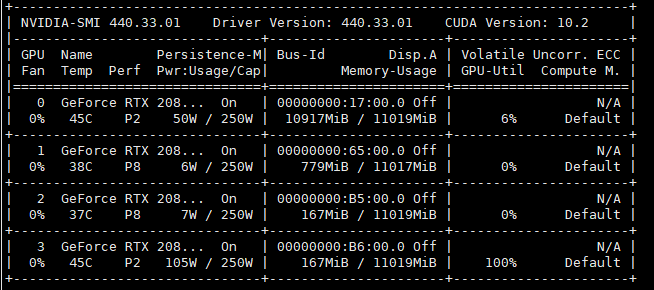
Solved.
When you have more than one cudas, you must choose a certain one to run the code.
use:
devices = 'cuda:0' if ......
instead of:
devices = 'cuda' if ......
Hey, I have been facing exactly this problem. Looks like you have solved it. I have a stupid question - where do I write "devices = 'cuda:0' ? in models.py? I am running 'python train.py --shm-size 20G' right now.