a-PyTorch-Tutorial-to-Image-Captioning
 a-PyTorch-Tutorial-to-Image-Captioning copied to clipboard
a-PyTorch-Tutorial-to-Image-Captioning copied to clipboard
Attension Network explanation?
Thanks for you tutorial! I found in READEME.md and code:
def forward(self, encoder_out, decoder_hidden):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:param decoder_hidden: previous decoder output, a tensor of dimension (batch_size, decoder_dim)
:return: attention weighted encoding, weights
"""
att1 = self.encoder_att(encoder_out) # (batch_size, num_pixels, attention_dim)
att2 = self.decoder_att(decoder_hidden) # (batch_size, attention_dim)
att = self.full_att(self.relu(att1 + att2.unsqueeze(1))).squeeze(2) # (batch_size, num_pixels)
alpha = self.softmax(att) # (batch_size, num_pixels)
attention_weighted_encoding = (encoder_out * alpha.unsqueeze(2)).sum(dim=1) # (batch_size, encoder_dim)
return attention_weighted_encoding, alpha
You implement the attension function $f_att(a_i, h_{t-1}$ as below:
added and ReLU activated. A third linear layer transforms this result to a dimension of 1
And I want to know is this your own method or you fellow a paper(could you give me a link)? And will a concat of att1 and att2 be better?
@roachsinai This is the result of Show, Attend and Tell paper here. It is stated at the top of the tutorial. Moreover, you can visualize this diagram I drew for how the attention is calculated. Hope it helps!
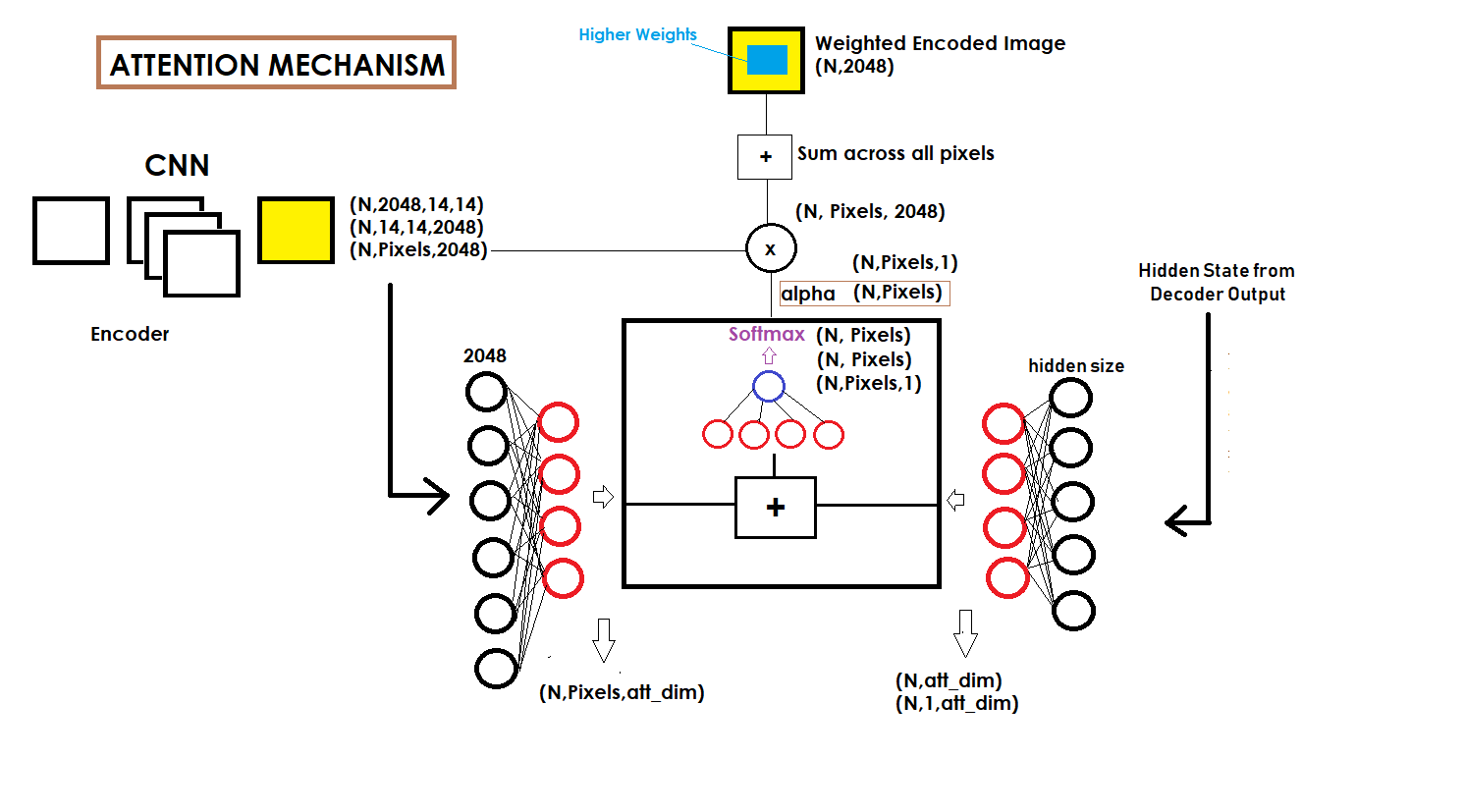
Thanks for your reply. Yes, I read that paper. And seems it didn't show the detail of how to calculate
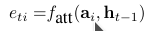
And in paper referenced by 《Show, Attention and Tell》says We parametrize the alignment model f(a in that paper) as a feedforward neural network which is jointly trained with all the other components of the proposed system.
And I find some definition of function f as below:
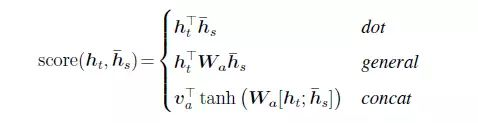
So, just want to know the pros of att1 + att2 let you chose it.
This is just another way of calculating the attention. It doesn't have to be the same as the proposed above. You can realize that all have the encoder output and the previous decoder output. So it's just a matter of what operation you are using. In "Show Attend and Tell" paper, they proposed the addition operation. You should check with @sgrvinod as well for your answer.
Hi @roachsinai and @fawazsammani, thanks for the question. When I wrote the code, I originally wanted to concatenate instead of add, because that sounds more intuitive to me.
But then I looked at the paper author's repo, where he seems to be initializing the parameters Wc_att, Wd_att, U_att for addition, based on their sizes. I may be wrong since I don't know Theano at all. I also found the same in this repo.
Now, addition definitely seems more restrictive to me than concatenating - why mix and dilute them? But it probably forces the model to learn such that the nth parameter/dimension of att1 and att2 vectors indicate the same particular thing, and their interaction helps decide the importance of the pixel for the next word. But if I were to guess, I think concatenating would work at least as well as adding.
I'm guessing both would be valid and work well, and perhaps even Bahdanau's machine translation model is also used with both methods, but I've only seen concatenation in my NLP experience.
Let me know if you try it, and I'll add a note in my tutorial.
@sgrvinod if you were to concatenate them, then based on the 3rd equation above that @roachsinai attached, would you need to pass the encoder output and the previous decoder output through a linear layer first? Or we can probably just concatenate the decoder output tensor to the encoder output tensor directly without passing them through a linear layer?
Hi, just a question, does your code support DecoderWithoutAttention? Or if I want to implement this, how should I alter the code? I am thinking to change this softmax to average but I am not sure it is correct. Thanks.
Hi @zsquaredz ,
My code doesn't support it. I haven't tried image captioning without attention, but off the top of my head, I'd -
-
Not get rid of the linear layers in the pretrained encoder, since we don't need pixel-wise representations anymore. I'd use the output of the final linear layer as the encoding.
-
Concatenate this encoding to each input word in the ground truth caption, feed them into the decoder to predict the next word.
-
Alternatively, use the encoding as the initial hidden state, and feed the input words alone into the decoder to predict the next word.
-
If we don't have the attention component, we don't need the for loop where we're manually decoding only the effective batch size. You could instead just use
pack_padded_sequence()utility. See the note at the end of this section.
Overall, I'd say it simplifies things significantly.
If you're looking for the "quickest" fix to my code that might work, you could try setting attention_weighted_encoding to the average encoding across all pixels encoder_out[:batch_size_t].mean(dim=1) in this line, and discard alpha.
@sgrvinod thanks for the wonderful code and tutorial. I had a question on the attention part. As per my understanding, the flattened encoder output is (N,196,2048) and the attention weights (alpha) is (N,196). So, every pixel in a channel is multiplied by a weight and this weight remains the same for corresponding pixels in all the channels. My question is, can we have an alpha matrix-like (N, 2048) where every channel gets multiplied by a different weight and all the pixels in a particular channel share the same weight.
Can you please explain how one approach is better than the other?