Move libawkward.so (etc) into its own package
Let's do this together, and we can use it as the point where we migrate to cibuildwheel. I expect together we'll be faster than if we did it separately.
We can share screen in Zoom, but we might want to also use Atom/TeleType or the VSCode equivalent you use. (I haven't used VSCode before.) Otherwise, we could pass suggestions back and forth on a Google Doc, while only one of us is entering changes.
Yes, this will be more complicated than it was at the beginning of the year...
@agoose77 This is the issue I was thinking of.
To catch up @henryiii on something we talked about in the Awkward-Dask meeting: @martindurant is thinking about a suite of string functions, like everything in np.char.* but with UTF-8 capabilities, vectorized across Awkward Arrays. (This might be a killer app for Awkward in industry.) The short path to implementing this is through Rust because Rust has a good UTF-8 library, in which questions like "what does it mean to capitalize?" have already been thought through. and it would be higher performance than multi-pass NumPy-based implementations like this equality operation.
Strings are a high-level ak.behavior in Awkward Array, but foundational ones that should included when one does pip install awkward (unlike, say, Lorentz vectors, for which there's pip install vector awkward). Rust complicates the build procedure, and a clean way of avoiding that would be to put them in a separate PyPI (and conda-forge) package: awkward-string-kernels. Since strings are foundational, awkward would strictly depend on awkward-string-kernels.
Naturally, that reminded me of this project, of externalizing the compiled code into a package that awkward strictly depends on. An advantage that @martindurant brought up, which I hadn't thought of, is that any potential contributor who doesn't need to touch kernels or C++ would get those binaries from PyPI/conda-forge and be able to operate on a pure Python awkward codebase. With v2, that includes a much larger fraction of the codebase.
As an overview, the eventual project would involve the following pieces, which could all be separate packages:
awkward-string-kernels, as described above; probably a Rust-compiled shared object library with a ctypes interface that a Python part interacts with: that Python provides behaviors forak.beahviors.awkward-cpu-kernels, which are "nearly C," using C++ only for numerical type templating. If there's ever any desire to make them pure C, that wouldn't be difficult for most of them (replacing templates with#define: yuck!) but would be a problem for the sorting and uniqueness kernels (which use the C++ standard library). I doubt it's necessary, though: C++ compilers are ubiquitous. This part does not use pybind11.libawkward: three features are fully written in C++ (11) and rely on it for performance: ArrayBuilder, LayoutBuilder, and AwkwardForth. This part uses pybind11. We had been talking aboutawkward-cpu-kernelsandlibawkwardbeing part of the same package, but the two pieces come apart easily and they differ in how seriously they use C++ features, and onlylibawkwardneeds pybind11. What do you think about them being separate?awkward-cuda-kernels, which should be a separate package because it's optional (the only optional one in this list). It has yet different build constraints: it needs CUDA and nvcc.- All the rest of Awkward Array, starting in version 2.0, can be pure Python.
pip install awkwardwould pull in everything butawkward-cuda-kernelsas strict dependencies, andpip install awkward[cuda]would pull in CUDA.
This pattern suggests generalization: awkward-cpu-kernels has a lot of "nearly C" functions and a few that make use of the C++ standard library, which are also hard to imagine porting to CUDA, so maybe that splits up into awkward-cpu-kernels and awkward-sorting-kernels. The awkward-string-kernels likewise may be difficult to port to CUDA, so making it granular like this could help to explain which things can be done on the GPU and which can't: i.e. "awkward-cuda-kernels implements all awkward-cpu-kernels, but not any of the specialized ones."
Each of the kernels packages could have its own kernels specification, in the same YAML format, which awkward uses to generate ctypes interfaces (with more information than a header file: the "in vs out" of each array argument is important).
Oh, and I should probably also mention that each of the packages that the awkward package depends on would be pinned to identical version numbers, since the coupling between kernels, ArrayBuilder/LayoutBuilder/AwkwardForth, and downstream Awkward Array behavior is tight, not loose. Since matching versions is important, they would probably all be built from this one GitHub repo, so that they have shared version control.
(But it would also be advantageous for them to have separate CI, since we don't want to have to wait for recompilation when we're making Python changes, and we're imagining future contributors to be much more active on the Python part. Maybe that adds too much complexity, though.)
More on this later, but a few quick thoughts:
Rust shouldn't be too much of an issue, but it will be a bit of "good trouble", I expect. There's been quite some interest in Rust - Brett Cannon, a core dev for CPython and SC member has written the Python Launcher for Unix in Rust. There have also been a few projects moving to Rust. I don't think there have been too many packages on PyPI using Rust, but I expect that to change. We might have to pioneer the usage of Rust here, but it could be very helpful for other projects. (And Rust is a fantastic lowish-level language, I'd take it over C any day :) )
C++ internals with a C interface is perfectly fine. Don't try to hack together templates by hand with macros. :)
This reminds me that different packages from the same file might be an important thing to consider for scikit-build, as well as possibly interfacing to native language build systems (Rust, Go). I expect there will be a general grouping into separate repositories based on build/ci needs, and the (small number) of repos will then have some number of packages in each. Parts that don't get changed as often ideally could have a slower version number than the Python wrappers, etc, which change more frequently. (I wish boost-histogram had been split this way).
(About Rust in particular, I strongly wanted to make Awkward 1.0 my first Rust project, since we determined that it had to have a compiled part, but I chose C++ for compatibility reasons. Those compatibility reasons being completely misguided is a large part of why we're moving most of it into Python now. But in a parallel universe somewhere, the kernels, ArrayBuilder, LayoutBuilder, and AwkwardForth are all implemented in Rust. Maybe starting with awkward-string-kernels in Rust would be a first step toward reconvergence with that alternate world...)
I found this issue when discussing a similar topic on Gitter, so I thought I'd move that discussion here!
Since matching versions is important, they would probably all be built from this one GitHub repo, so that they have shared version control.
I haven't much experience of non-monorepo development for a project like this. From a CI perspective, I imagine it's going to make much more sense to use a monorepo.
But it would also be advantageous for them to have separate CI, since we don't want to have to wait for recompilation when we're making Python changes, and we're imagining future contributors to be much more active on the Python part.
I agree with this. If we nicely package each component into its own Python package, we can implement the CI without too much difficulty, I think. As you say, this is much more important now that most of Awkward development shouldn't need to touch the C++ layer.
There are some additional pros, as I see them:
- Much quicker build times + CI feedback times
- Smaller wheels (~3MB vs 14.5MB) - some installers can perform parallel downloads, making this faster too
- Simpler build system - we could move the Python-only project to flit / pdm rather than setuptools :)
Most of the cons I think are outlined here, including upfront work to reconfigure the repo.
I saw this when I was prioritizing issues. This thread started in 2020, and how it would be dealt with now is rather different than it was then.
The date when all v1 code will be dropped and we release a version numbered "2.0.0" is set: Dec 1, 2022 (exactly 2 years after 1.0.0, see roadmap).
Right now, we build 46 wheels in each release, which is a total of 576 MB per release. Each wheel is 10‒15 MB (though
cp3*-cp310-macosx_10_9_universal2 is 21 MB). On my Linux, libawkward.so is 8.2 MB and libawkward-cpu-kernels.so is 1.6 MB. The kernels in v2 won't be much smaller (we'll be able to remove a few trivial kernels now that we can use more NumPy, but not the complex ones), but libawkward.so will be considerably smaller.
To get a sense of this, I did rough surgery on the codebase, removing what I know will be removed and just patching things up so that import awkward works (without any other testing—the actual transition will require care!). In this rough v2 environment, the number of lines of C++ code is
% cloc include/awkward src/libawkward src/python
53 text files.
53 unique files.
0 files ignored.
github.com/AlDanial/cloc v 1.82 T=0.05 s (1013.7 files/s, 429753.4 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 24 1151 553 10687
C/C++ Header 29 1136 1090 7851
-------------------------------------------------------------------------------
SUM: 53 2287 1643 18538
-------------------------------------------------------------------------------
compared to the current (1.9.0rc2) environment:
% cloc include/awkward src/libawkward src/python
173 text files.
173 unique files.
0 files ignored.
github.com/AlDanial/cloc v 1.82 T=0.22 s (787.9 files/s, 477788.7 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 84 5600 467 71849
C/C++ Header 89 4264 5217 17514
-------------------------------------------------------------------------------
SUM: 173 9864 5684 89363
-------------------------------------------------------------------------------
Compilation time for localbuild.py in the rough v2 environment is 38 sec using all (12) threads + 17 sec using one thread = 55 seconds. Compilation time for pip install . in the rough v2 environment is 43 sec using all (12) threads + 12 sec using one thread = 55 seconds. (Note: the total time is accurate, from time, the breakdown into parallel + sequential is a by-hand stopwatch.)
Compilation time for localbuild.py in the current (1.9.0rc2) environment is 106 sec using all (12) threads + 120 sec using one thread = 226 seconds. Compilation time for pip install . in the current (1.9.0rc2) environment is 89 sec using all (12) threads + 53 sec using one thread = 142 seconds.
The size of libawkward-cpu-kernels.so stays the same at 1.6 MB (naturally; it wasn't changed), but the size of libawkward.so drops from 8.2 MB down to 1.2 MB.
Here are some compressed sizes within a sample wheel:
>>> os.path.getsize("awkward-1.9.0rc2-cp39-cp39-manylinux_2_12_x86_64.manylinux2010_x86_64.whl")
11621633
>>> f = zipfile.ZipFile("awkward-1.9.0rc2-cp39-cp39-manylinux_2_12_x86_64.manylinux2010_x86_64.whl")
>>> print("\n".join(x for x in f.namelist() if x.endswith(".so")))
_ext.cpython-39-x86_64-linux-gnu.so
libawkward-cpu-kernels.so
libawkward.so
awkward/_ext.cpython-39-x86_64-linux-gnu.so
awkward/libawkward-cpu-kernels.so
awkward/libawkward.so
Okay, first issue: the shared libraries seem to be in there twice. Only the ones in awkward/ are actually accessed.
>>> for x in f.namelist():
... if x.endswith(".so"):
... print(x, f.getinfo(x).file_size, f.getinfo(x).compress_size, sep="\t")
...
_ext.cpython-39-x86_64-linux-gnu.so 10824112 3018096
libawkward-cpu-kernels.so 1586488 324808
libawkward.so 8205224 2132871
awkward/_ext.cpython-39-x86_64-linux-gnu.so 10824112 3018096
awkward/libawkward-cpu-kernels.so 1586488 324808
awkward/libawkward.so 8205224 2132871
The sum of compressed shared libraries (including that 2× duplication!) comprise 94% of the total size of the wheel. The contribution from compressed Python code is insignificant.
The shared libraries built on my computer are within 10% of the uncompressed sizes (including the _ext), and this is how they shrink when dropping v1 symbols:
_ext: 11791328 → 1317816, which is 11% as big (uncompressed)libawkward-cpu-kernels.so: 1611304 → 1610080, which is 100.07% as big (uncompressed)libawkward.so: 8508904 → 1205216, which is 7% as big (uncompressed)
Assuming code removal and compression factorize 🤷♂️, the code removal would reduce wheel size to
(0.06 + 0.94*(1317816 + 1610080 + 1205216)) / (0.06 + 0.94*(11791328 + 1611304 + 8508904)) = 0.1886
19% of their current size. Instead of a release costing 576 MB, a release will cost 109 MB.
If we also fix the 2× duplication, it would reduce wheel size to 9.4% of their current size, or 54 MB per release.
Instead of this wheel being 11 MB, it would be 1 MB.
A few conclusions:
- The reason I like
localbuild.pyis because it allows for incremental builds. In particular, if you don't change any header files, you get to skip most of the 120 sec of single-threaded linking. In v2, that part is just 17 sec and the compilation time becomes dominated by the very parallel compilation of cpu-kernels. Developers with a lot of cores will be able to compile from scratch in under a minute. Ifpip install -ecan be made to work, we could get rid oflocalbuild.pyand always compile throughpip, always from scratch, because only C++ changes would require a minute of waiting, and that's not so bad. Most development is in Python now, anyway. - We can reduce wheel size by a factor of 2 right now.
- When the v1 code is finally dropped on Dec 1, 2022, they will be 54 MB per release, or 1 MB for a typical wheel. I would say that's small enough to not have to worry about splitting the packages into a part that depends on architecture and a part that depends on Python version. There would still be a file-size benefit to doing so, but I don't think it warrants the complexity.
What do you think?
~@jpivarski can this be closed, now?~
I re-read the comments, and I think there is still merit to this, actually. The assumption underpinning this is that most work on Awkward isn't touching the compiled portions any more. To summarise where we're at now:
Resources
With the v2 split, we lose the first-order concerns about file-size (our builds are now ~3MB w/ duplication). However, deleting the compiled portion of the wheel naively drops the distribution size entirely to ~550kB (assuming no compiled changes). Of course, this is multiplicative; we would be able to release a pure-Python wheel and thus drop the per-platform scaling factor. I'm increasingly thinking about trying to reduce the resources that projects use from PyPI et al., so if we can do something here (even if we're only talking MBs), it might be worth it. Splitting awkward into awkward and libawkward would likely see us releasing awkward more frequently, and occasionally releasing patch versions of libawkward. We are free to synchronise the two if needs be, i.e. for a new feature release in awkward.
Release / CI duration
Even with the new v2 build process, our releases take hours (we don't use ccache in cibuildwheel). It would be nice to reduce this for multiple reasons (UX, resource usage, etc).
Note that we could at least remove the build time costs by instead caching the built binary artefacts with a hash of their sources, and drop ccache (for simplicity). The question is whether the work to do this is better than explicitly separating the compiled and non-compiled sources.
In a random run of build-test, we had:
- Win: 6m33s of 9m1s on compiled code
- Mac: 4m24s of 9m37s on compiled code
- Linux: 2m37s of 5m43s on compiled code
Our CI could move to something like ~2.5-5.5 minutes per job across archs, meaning approx ~2x faster (very hand wavy).
Meanwhile, I don't have any hard numbers, but our releases would essentially become tens-of-minutes instead of 3.5 hours, unless we also had to modify the compiled portion. I say this because our release time is dominated by the alt-builds, which I assume Is nearly entirely the setup + compilation via emulation.
Development burden
Splitting out the compiled portion of awkward (even if we use a monorepo) means we could move to flit without waiting for scikit-core-build (which will inevitably improve the compiled build toolchain, when it's ready). It's only a small issue, but I'd like to be able to use pip install -e . e.g. to ensure that the numba entry-point is working, and to avoid having my IDE get confused between awkward/ and src/awkward/.
Unless we count complexity as a negative, the value of splitting libawkward (the C++ part) out of awkward (the Python part) as two PyPI (and conda-forge?) packages has always been positive. The question is whether the positive is significant enough to prioritize right now.
- Compilation time and CI time: used to be a bigger deal than it is now, though being able to test the Python parts without recompiling the C++ parts is always going to be somewhat faster. If it's now a factor of 2, I wouldn't say that's an argument on its own.
- Deployment time: getting a release out in minutes, rather than 4 hours, would be a Very Big Deal.
- PyPI disk space (quota): used to be a bigger deal than it is now.
- Eliminating
localbuild.pyand usingpip install -e .instead: a Very Big Deal. I've been looking forward to this for a long time, without even having the problem of an IDE getting confused, though I can see how this would happen. I haven't triedpip install -e .after v1 was dropped: I don't know if this is still a problem. But if we splitlibawkwardfromawkward, then it would definitely work on the Python part. - filt: wasn't this going to be hatchling? Uproot uses hatchling, and it would probably be easier if they were the same.
Addressing this would also have the side-benefits of reexamining some things. One is that it seems like the wheels are producing libawkward.so and libawkward-cpu-kernels.so outside the awkward directory (in site-packages). That's not intended, and I'm not sure if it's platform-dependent. The .so files were supposed to all be inside the awkward directory, to minimize the possibility of name-clobbering (though names containing "awkward" are rather unlikely, which was a motivating point in favor of the project's name).
Another is that libawkward.so, libawkward-cpu-kernels.so, and _ext.asdl;fkja;dfklj.so no longer need to be separate libraries. At least, libawkward.so and libawkward-cpu-kernels.so don't need to be separate because different "kernels" backends are not going to be swapped out at the shared library level (as was originally envisioned). Now the CUDA kernels are JIT-compiled in CuPy, and it will never be the case that we want some kernels other than the CPU kernels and also not the CPU kernels: the CPU kernels will always need to be available.
So at least libawkward.so and libawkward-cpu-kernels.so can be a single shared library file. But further, there isn't a strong reason for this to be a distinct library from the Python module itself, since we're not providing a C++ interface as a linkable library. (Instead, we're providing a C++ interface as header-only source code.) What we do need is to be able to access pure C functions with dlopen. The Numba implementation of ArrayBuilder calls into extern "C" functions in libawkward.so with external function pointers—it has to work this way to hide ArrayBuilder's dynamic types from Numba. Right now, our kernels are called by ctypes. They're compiled into the Python library anyway and could be pybind11-wrapped, though the binding code would have to be automatically generated because there are a lot of kernels, and those calls would have to release the GIL (which we get automatically with ctypes). But I think it must be possible to get a ctypes module associated with a Python extension module and access its extern "C" functions, possibly in a more simple way than we do now.
If we're pulling things apart to make two packages, putting it back together in such a way that the libawkward package (or awkward-core?) consists of a single extension module and no free-floating shared libraries would simplify deployments and further reduce C++ build times and disk space (though that's a smaller concern now than it used to be). Currently, some symbols appear in all three .so files.
Now for the complication: if we have two packages, awkward-core and awkward, and the Python one is updated more frequently than the C++ one (which is the whole point, after all), then they will have different version numbers to sync. The version compatibilities can be managed as strict dependencies by PyPI/conda-forge, but these dependencies should probably also be human-computable so that it's easy to spot an incompatibility if you know the pattern: perhaps awkward-core and awkward should always agree in major and minor number, but not necessarily revision number? So awkward-core 2.1.X can be used with awkward 2.1.Y for any (or the latest) X and Y, but X and Y are not required to be equal. Releasing 2.2.0 would mean that a new awkward-core and awkward are both needed, even if one is not changing.
In this scheme, awkward-core would have no dependencies (not even NumPy!) and awkward 2.1.Y would have (in addition to NumPy),
awkward-core >= 2.1.0, < 2.2
Normally, putting an upper bound on a dependency is a bad thing, but that's because we're releasing both packages, controlling when they get released, and there's a tight coupling between the two. This is reason number 5 in @henryiii's When it's okay to set an upper limit.
No matter how carefully we do it, there will always be a time-gap between when awkward-core is released and when awkward is released. I suppose pip is smart enough now that someone who tries to install in the window when one is released and the other isn't, pip will install the latest consistent pair. Depending on how pip works, it might be a good idea to deploy awkward 2.2.0 first, then awkward-core 2.2.0 afterward, so that someone who tries to pip install awkward will get the last 2.1.Y until awkward-core is deployed. It might also be necessary to deploy the awkward-core source distribution last, so that someone trying to pip install in this window doesn't get a compiler error because their binary wheel isn't uploaded yet.
One more complication: although we edit the C++ code much less often nowadays, @ioanaif is working on kernels for vectorized matrix multiplication right now. Perhaps we should think about these packaging improvements, but implement them after @ioanaif is done.
filt: wasn't this going to be hatchling? Uproot uses hatchling, and it would probably be easier if they were the same.
I prefer hatchling, I just talk about flit_core sometimes (I'm really referring to new PEP 621 builders).
One is that it seems like the wheels are producing libawkward.so and libawkward-cpu-kernels.so outside the awkward directory (in site-packages). That's not intended, and I'm not sure if it's platform-dependent.
Yes, I was looking to tackle that at the same time. I took a look earlier, and the Win wheels don't have the same number of objects outside of the awkward subdirectory. I noticed that, at least on my machine for python3 setup.py bdist_wheel, the get_outputs() method isn't called, also.
So at least libawkward.so and libawkward-cpu-kernels.so can be a single shared library file.
Yes, it's really a matter of convenience. I'm in favour of keeping them the same; we aren't encouraging anyone to link against these, and the sizes are small. Meanwhile, release complexity goes up ever so slightly the more packages we build.
The version compatibilities can be managed as strict dependencies by PyPI/conda-forge, but these dependencies should probably also be human-computable so that it's easy to spot an incompatibility if you know the pattern
Yes, we do need to think about this part. In principle, I think we have an easier job of semvering the CPU-kernels part, which has a very limited interface and is effectively a bunch of free-standing functions; the API surface is fairly small, and most features can just be new kernels. The libawkward part removes this simplicity. I am not against synchronising versions between the two packages; JupyterLab e.g releases a set of MAJOR.0.0 packages for each major release. However, I wouldn't want this coupling to be so tight that we resemble e.g. jaxlib; if releasing an awkward version requires a new awkward-core, then we're back to long release builds. We don't have much data here; most of our releases on PyPI are new minor versions; we don't patch much. I'd probably prefer to cap on the major version here, which is a much, much broader compatibility range. Effectively we need to choose some level of compatibility commitment and then stick to it. I'm not against leaving the upper bound unset, but I also don't know about the kind of downstream problems that users of semi-managed platforms like HPC environments have to face; if we introduce unpinned dependencies, does that break their assumptions? Note that this would only affect users who don't update their awkward version, but update awkward-core for whatever reason. It's good that you've tagged @henryiii; it will be nice to get a few opinions on this from different stakeholders. I'm a convert to the pinning-skepticism (tongue-in-cheek) in Python, but I'm not someone who's applied it in practice in a library used by as many as Awkward.
One more complication [...]
The details of how we manage the workflow of developers who touch the compiled portion would need to be worked out. We could do anything from
- have a PR label that turns on building of the compiled parts (to use in the testing of the Python module)
- have the workflow check the branch diff to see if compiled code has been modified
Looking at the data, expecting to make the point that we don't touch C++ all that much anymore:
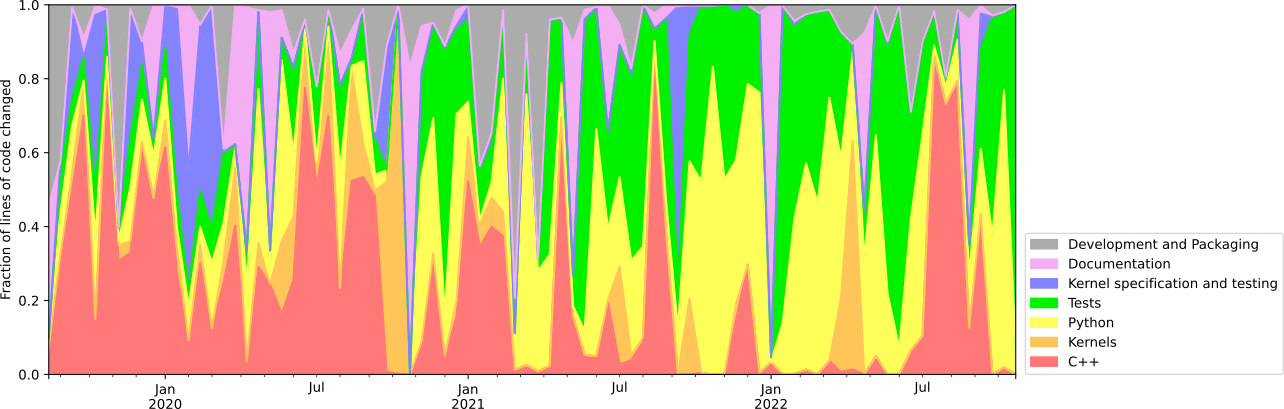
It's true that 2019‒2020 saw a lot of C++ and kernel changes (v1 development) and 2021‒2022 saw a lot of Python and test file changes (v2 development). Your final removal of the v1 code is the last little peak on September 10, 2022, but there's a lot of C++ work earlier in the summer. It was @ManasviGoyal's development of GrowableBuffer and LayoutBuilder, as well as @ianna's adjustment of the C++ code to use the new GrowableBuffer and remove v1 dependencies from the C++ code that survived into v2. That was a substantial amount of C++ work, recently, though we don't have reason to expect something like that to happen again.
It's also neat to see that there was a lot more test development for v2 than for v1 (shout-out to @ioanaif).
It would be too much to write here how this plot was made, except to say that the time-granularity is 2 weeks per time-bin, "lines changed" means the max of insertions and removals (so a changed line counts as much as a removed or added line), and this is how file names were classified:
def classify(x):
if (
re.match("^\{?\..*", x)
or re.match("^\{?dev/", x)
or re.match("^\{?studies/", x)
or re.match("^\{?requirements.*\.txt", x)
or re.match("^\{?test-requirements.*\.txt", x)
or x in [
"CMakeLists.txt", "Doxyfile", "MANIFEST.in",
"VERSION_INFO", "codecov.yml", "cuda-build.sh", "dlpack", "localbuild.py", "noxfile.py", "pybind11", "pyproject.toml", "rapidjson",
"runtime.txt", "setup.cfg", "setup.py", "simdjson", "src/awkward/_typeparser/type-grammar.lark",
]
):
return "Development and Packaging"
elif re.match("^\{?dependent-project/.*", x) or re.match("^\{?docs.*/.*", x) or x in [
"CITATION.cff", "CONTRIBUTING.md", "LICENSE", "QUICKSTART.md", "README-pypi.md", "README.md",
]:
return "Documentation"
elif (
re.match("^\{?src/awkward.*\.py\}?$", x)
or re.match("^\{?awkward1.*\.py\}?$", x)
or re.match(".*\{awkward1 => awkward\}.*\.py\}?$", x)
or x in ["src/{awkward1_cuda_kernels => awkward_cuda_kernels}/__init__.py", "{cuda-kernels => src}/awkward1_cuda_kernels/__init__.py"]
):
return "Python"
elif (
re.search("cpu-kernels/", x)
or re.search("cuda-kernels/", x)
or re.match(".*\.cu\}?$", x)
or re.match(".*(getitem|identities|operations|reducers|sorting|gpu_kernels|kernel-dispatch|kernels?)\.h\}?$", x)
):
return "Kernels"
elif re.match(".*\.xml\}?", x) or re.match("^\{?kernel-specification.*", x) or x in [
"kernel-test-data.yml", "test-data.yml", "test-data.yml => kernel-test-data.yml"
]:
return "Kernel specification and testing"
elif re.match(".*\.cpp\}?$", x) or re.match(".*\.h\}?$", x):
return "C++"
elif re.match("^\{?tests.*", x):
return "Tests"
else:
raise AssertionError(x)
Over in #1778 I took a look at what this split might look like. It's actually fairly straightforward.
@jpivarski that's a fun graph. I enjoy the exponential-like decay of the C++ activity (if you squint hard enough to ignore the flurry of activity before v1→v2).
@jpivarski - nice! BTW, we do have some C++ code as strings embedded in Python ;-)
That's okay. Those code strings embedded in Python are, by definition, only usable by Python with a C++ JIT available, so it's a different sort of thing than the C++ that we want to isolate in awkward-core. Actually, those embedded Python strings are implementation details. The reason for isolating C++ in awkward-core and Python in awkward, as much as is possible, is to make the project easier to think about from the outside—i.e. public interface. We want the GrowableBuffer and LayoutBuilder C++ in awkward-core because that's the place for downstream developers to look for C++ code. Downstream developers won't be able to use the strings embedded in Python.
So that's why the criterion applies to the cpp-headers directory and not the embedded strings. (If some things ought to move from embedded strings into cpp-headers to be visible to downstream developers, then that's anther thing.)