LAVIS
 LAVIS copied to clipboard
LAVIS copied to clipboard
Training code for okvqa and vqav2 finetune
Thanks for the great work. Will the code related to the following table be open source soon?And does the current code support okvqa finetune?
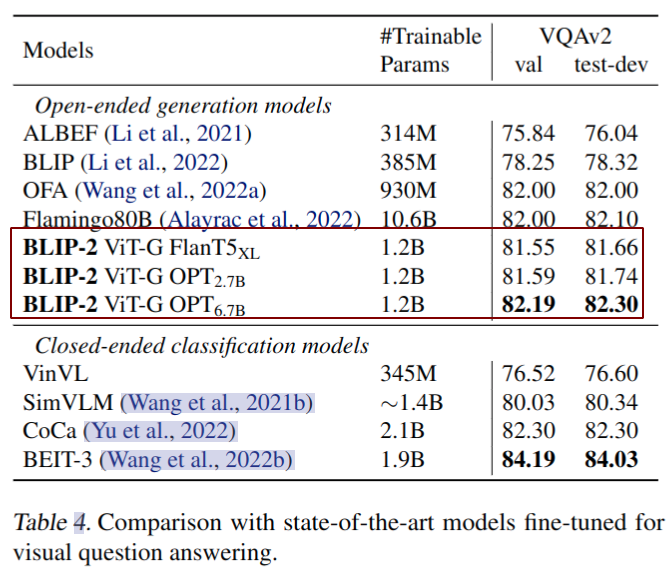
Thanks.
The current codebase supports training on these datasets. However, in terms of release on BLIP-2 VQA models, we have decided to de-prioritize it considering the limited bandwidth we have.
When we have better availability, we will work on this item. But delays are expected.
Thanks for your understanding.
The current codebase supports training on these datasets.
Hi, If found that current BLIP2 codebase need some modification for VQAv2 and OKVQA fine-tune. The modification I did:
samples["text_output"]->samples["answer"]self.max_text_length->self.max_txt_len- Repeat inputs based on the samples["n_answers"] (like BLIP1) the modified forward function in https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/blip2_t5.py#L99 as follows
def forward(self, samples):
image = samples["image"]
image_embeds = self.ln_vision(self.visual_encoder(image))
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(
image.device
)
query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
query_output = self.Qformer.bert(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
)
inputs_t5 = self.t5_proj(query_output.last_hidden_state)
atts_t5 = torch.ones(inputs_t5.size()[:-1], dtype=torch.long).to(image.device)
with torch.cuda.amp.autocast(dtype=torch.float32):
input_tokens = self.t5_tokenizer(
samples["text_input"],
padding="longest",
truncation=True,
max_length=self.max_txt_len,
return_tensors="pt",
).to(image.device)
output_tokens = self.t5_tokenizer(
samples["answer"],
padding="longest",
truncation=True,
max_length=self.max_txt_len,
return_tensors="pt",
).to(image.device)
batch_input_tokens_input_ids = []
batch_input_tokens_atts = []
batch_atts_t5 = []
batch_inputs_t5 = []
for b, n in enumerate(samples["n_answers"]):
batch_input_tokens_input_ids += [input_tokens.input_ids[b]] * n
batch_input_tokens_atts += [input_tokens.attention_mask[b]] * n
batch_atts_t5 += [atts_t5[b]] * n
batch_inputs_t5 += [inputs_t5[b]] * n
batch_input_tokens_input_ids = torch.stack(batch_input_tokens_input_ids, dim=0)
batch_input_tokens_atts = torch.stack(batch_input_tokens_atts, dim=0)
batch_atts_t5 = torch.stack(batch_atts_t5, dim=0)
batch_inputs_t5 = torch.stack(batch_inputs_t5, dim=0)
encoder_atts = torch.cat([batch_atts_t5, batch_input_tokens_atts], dim=1)
targets = output_tokens.input_ids.masked_fill(
output_tokens.input_ids == self.t5_tokenizer.pad_token_id, -100
)
inputs_embeds = self.t5_model.encoder.embed_tokens(batch_input_tokens_input_ids)
inputs_embeds = torch.cat([batch_inputs_t5, inputs_embeds], dim=1)
outputs = self.t5_model(
inputs_embeds=inputs_embeds,
attention_mask=encoder_atts,
decoder_attention_mask=output_tokens.attention_mask,
return_dict=True,
labels=targets,
)
loss = outputs.loss
return {"loss": loss}
- The blip2 okvqa finetuning config file:
model:
arch: blip2_t5
model_type: pretrain_flant5xl
load_finetuned: False
use_grad_checkpoint: True
# freeze_vit: False
freeze_vit: True
datasets:
ok_vqa: # name of the dataset builder
vis_processor:
train:
name: "blip_image_train"
image_size: 224
# image_size: 224
eval:
name: "blip_image_eval"
image_size: 224
# image_size: 224
text_processor:
train:
name: "blip_question"
eval:
name: "blip_question"
run:
task: vqa
# optimization-specific
lr_sched: "linear_warmup_cosine_lr"
init_lr: 3e-5
min_lr: 1e-5
weight_decay: 0.02
max_epoch: 7
# batch_size_train: 16
batch_size_train: 1
batch_size_eval: 8
num_workers: 4
# inference-specific
max_len: 10
min_len: 1
# num_beams: 256
num_beams: 5
num_ans_candidates: 128
# num_ans_candidates: 96
inference_method: "rank"
seed: 42
output_dir: "output/BLIP2/OKVQA"
amp: False
resume_ckpt_path: null
evaluate: False
train_splits: ["train"]
test_splits: ["test"]
# distribution-specific
device: "cuda"
world_size: 1
dist_url: "env://"
distributed: True
- In addition to the above modifications, I also modified some configurations for training on V100 GPU
- bfloat16 -> float32
- batch_size_train: 16->1
- num_beams: 256 -> 5
- freeze_vit: False -> freeze_vit: True
After the afore mentioned changes, the fine-tune accuracy on OK-VQA is 47.49.

I have several questions that I hope someone can help me:
- What is the precision of finetune of the original BLIP2 on okvqa? (I don't see any result in the paper.)
- If the accuracy is significantly higher than my reproduce accuracy (47.49), What is the possible reasons for the accuracy reduction?
@kebijuelun Hi, your answer is very useful. Is the parameter modification you mentioned a piece of V100? If I have 8 pieces of 3090, can I fine-tune the FlanT5XL model of the author’s original parameters?
@kebijuelun Hi, your answer is very useful. Is the parameter modification you mentioned a piece of V100? If I have 8 pieces of 3090, can I fine-tune the FlanT5XL model of the author’s original parameters?
The parameters is used with a V100 (32G vRAM), and I found that the max training batch size could be 8. I don't have a 3090 (24G) to test. I think even with bfloat32 training, the batchsize needs to be further reduced (such like 4 or 8).
@kebijuelun thank to your response, if I use the 3090 can use the same type "bf16", the blip2_t5.py I will need to change parameters, like"text_ouput"?
@kebijuelun thank to your response, if I use the 3090 can use the same type "bf16", the blip2_t5.py I will need to change parameters, like"text_ouput"?
I don't see any text_ouput in the blip2_t5.py. Maybe you could refer the code I mentioned before, this code can run on v100.
When migrating to 3090, you may need to modify the batch size and data type (float32->bfloat16).
@kebijuelun Hello, I want to ask again, did you fine-tune with eval_okvqa_zeroshot_flant5xl.sh? Do you have a single card or multiple cards, and how much memory do you have? I use 8 3090, 128g memory will explode, I am not sure whether it is the memory or the video memory of the graphics card.
@kebijuelun Hello, I want to ask again, did you fine-tune with eval_okvqa_zeroshot_flant5xl.sh? Do you have a single card or multiple cards, and how much memory do you have? I use 8 3090, 128g memory will explode, I am not sure whether it is the memory or the video memory of the graphics card.
- I fine-tune with the cmd:
python -m torch.distributed.run --nproc_per_node=4 train.py --cfg-path xxx.yaml - I train with 4xV100
- RAM 100G, vRAM 32G
I think the error message is needed to confirm what caused the out of memory.
@kebijuelun Hi, are you also using the prompt suggested by the paper for VQA?
@kebijuelun I tried to use your code to fine-tune FLAN-T5-xl, but the loss is always oscillating and never converge. I used the prompt "Question: {} Short Answer:" and inputed the question to the Qformer as suggested in 4.3, but it does not work as well. Can I have a look at your curve of training loss or the log? Thanks in advance :)
@kebijuelun I think the provided code does not support taking the question into the Q-Former. https://github.com/salesforce/LAVIS/issues/198
@kebijuelun Hi, are you also using the prompt suggested by the paper for VQA?
yes, I use the prompt from eval script: https://github.com/salesforce/LAVIS/blob/main/lavis/projects/blip2/eval/okvqa_zeroshot_flant5xl_eval.yaml#L41
prompt: "Question: {} Short answer:"
I tried to use your code to fine-tune FLAN-T5-xl, but the loss is always oscillating and never converge. I used the prompt "Question: {} Short Answer:" and inputed the question to the Qformer as suggested in 4.3, but it does not work as well. Can I have a look at your curve of training loss or the log? Thanks in advance :)
Unfortunately, I didn't visualize loss with tb, the training loss in log file is as follows:
{"train_lr": "0.000", "train_loss": "2.254"}
{"train_lr": "0.000", "train_loss": "2.156"}
{"train_lr": "0.000", "train_loss": "2.128"}
{"train_lr": "0.000", "train_loss": "2.109"}
{"train_lr": "0.000", "train_loss": "2.095"}
{"train_lr": "0.000", "train_loss": "2.071"}
{"train_lr": "0.000", "train_loss": "2.061"}
I think the provided code does not support taking the question into the Q-Former. #198

Hi, the question is input to LLM in this case. You can modify it to send the problem to qformer.
@kebijuelun In Table 4 of the original paper, Flan-T5xl model requires 1.2B params in fine-tuining VQAv2 task. (But, 1.1B params are required in image captioning task.) It suspects that Faln-T5xl also fine-tunes requires word + position embedding of Q-Former during VQA fine-tuning.
The original paper mentioned: In order to extract image features that are more relevant to the question, we additionally condition Q-Former on the question. Specifically, the question tokens are given as input to the Q-Former and interact with the queries via the self-attention layers, which can guide the Q-Former’s cross attention layers to focus on more informative image regions.
@kebijuelun In Table 4 of the original paper, Flan-T5xl model requires 1.2B params in fine-tuining VQAv2 task. (But, 1.1B params are required in image captioning task.) It suspects that Faln-T5xl also fine-tunes requires word + position embedding of Q-Former during VQA fine-tuning.
The original paper mentioned: In order to extract image features that are more relevant to the question, we additionally condition Q-Former on the question. Specifically, the question tokens are given as input to the Q-Former and interact with the queries via the self-attention layers, which can guide the Q-Former’s cross attention layers to focus on more informative image regions.
Have you find the solution ? I also find this question...Maybe author have fix it in instructblip?
The current codebase supports training on these datasets.
Hi, If found that current BLIP2 codebase need some modification for VQAv2 and OKVQA fine-tune. The modification I did:
samples["text_output"]->samples["answer"]self.max_text_length->self.max_txt_len- Repeat inputs based on the samples["n_answers"] (like BLIP1) the modified forward function in https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/blip2_t5.py#L99 as follows
def forward(self, samples): image = samples["image"] image_embeds = self.ln_vision(self.visual_encoder(image)) image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to( image.device ) query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1) query_output = self.Qformer.bert( query_embeds=query_tokens, encoder_hidden_states=image_embeds, encoder_attention_mask=image_atts, return_dict=True, ) inputs_t5 = self.t5_proj(query_output.last_hidden_state) atts_t5 = torch.ones(inputs_t5.size()[:-1], dtype=torch.long).to(image.device) with torch.cuda.amp.autocast(dtype=torch.float32): input_tokens = self.t5_tokenizer( samples["text_input"], padding="longest", truncation=True, max_length=self.max_txt_len, return_tensors="pt", ).to(image.device) output_tokens = self.t5_tokenizer( samples["answer"], padding="longest", truncation=True, max_length=self.max_txt_len, return_tensors="pt", ).to(image.device) batch_input_tokens_input_ids = [] batch_input_tokens_atts = [] batch_atts_t5 = [] batch_inputs_t5 = [] for b, n in enumerate(samples["n_answers"]): batch_input_tokens_input_ids += [input_tokens.input_ids[b]] * n batch_input_tokens_atts += [input_tokens.attention_mask[b]] * n batch_atts_t5 += [atts_t5[b]] * n batch_inputs_t5 += [inputs_t5[b]] * n batch_input_tokens_input_ids = torch.stack(batch_input_tokens_input_ids, dim=0) batch_input_tokens_atts = torch.stack(batch_input_tokens_atts, dim=0) batch_atts_t5 = torch.stack(batch_atts_t5, dim=0) batch_inputs_t5 = torch.stack(batch_inputs_t5, dim=0) encoder_atts = torch.cat([batch_atts_t5, batch_input_tokens_atts], dim=1) targets = output_tokens.input_ids.masked_fill( output_tokens.input_ids == self.t5_tokenizer.pad_token_id, -100 ) inputs_embeds = self.t5_model.encoder.embed_tokens(batch_input_tokens_input_ids) inputs_embeds = torch.cat([batch_inputs_t5, inputs_embeds], dim=1) outputs = self.t5_model( inputs_embeds=inputs_embeds, attention_mask=encoder_atts, decoder_attention_mask=output_tokens.attention_mask, return_dict=True, labels=targets, ) loss = outputs.loss return {"loss": loss}
- The blip2 okvqa finetuning config file:
model: arch: blip2_t5 model_type: pretrain_flant5xl load_finetuned: False use_grad_checkpoint: True # freeze_vit: False freeze_vit: True datasets: ok_vqa: # name of the dataset builder vis_processor: train: name: "blip_image_train" image_size: 224 # image_size: 224 eval: name: "blip_image_eval" image_size: 224 # image_size: 224 text_processor: train: name: "blip_question" eval: name: "blip_question" run: task: vqa # optimization-specific lr_sched: "linear_warmup_cosine_lr" init_lr: 3e-5 min_lr: 1e-5 weight_decay: 0.02 max_epoch: 7 # batch_size_train: 16 batch_size_train: 1 batch_size_eval: 8 num_workers: 4 # inference-specific max_len: 10 min_len: 1 # num_beams: 256 num_beams: 5 num_ans_candidates: 128 # num_ans_candidates: 96 inference_method: "rank" seed: 42 output_dir: "output/BLIP2/OKVQA" amp: False resume_ckpt_path: null evaluate: False train_splits: ["train"] test_splits: ["test"] # distribution-specific device: "cuda" world_size: 1 dist_url: "env://" distributed: True
In addition to the above modifications, I also modified some configurations for training on V100 GPU
- bfloat16 -> float32
- batch_size_train: 16->1
- num_beams: 256 -> 5
- freeze_vit: False -> freeze_vit: True
After the afore mentioned changes, the fine-tune accuracy on OK-VQA is 47.49.
I have several questions that I hope someone can help me:
- What is the precision of finetune of the original BLIP2 on okvqa? (I don't see any result in the paper.)
- If the accuracy is significantly higher than my reproduce accuracy (47.49), What is the possible reasons for the accuracy reduction?
Thanks for your sharing. In OKVQA, a set of answers for a single question is usually with their corresponding confidence weights. It seems you did not consider the confidence weights, do you? Looking forward to your apply.
Can anyone help me double check if the code for fine-tuning blip2_opt VQA is correct? Thanks!
def forward(self, samples):
image = samples["image"]
with self.maybe_autocast():
image_embeds = self.ln_vision(self.visual_encoder(image))
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(
image.device
)
query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
query_output = self.Qformer.bert(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
)
# image inputs and atts
inputs_opt = self.opt_proj(query_output.last_hidden_state)
atts_opt = torch.ones(inputs_opt.size()[:-1], dtype=torch.long).to(image.device)
# decoder-only model
self.opt_tokenizer.padding_side = "right"
text = [t + "\n" for t in samples["text_input"]]
input_tokens = self.opt_tokenizer(
text,
return_tensors="pt",
padding="longest",
truncation=True,
max_length=self.max_txt_len,
).to(image.device)
output_tokens = self.opt_tokenizer(
samples["answer"],
padding="longest",
truncation=True,
max_length=self.max_txt_len,
return_tensors="pt",
).to(image.device)
############ add for vqa
batch_input_tokens_input_ids = []
batch_input_tokens_atts = []
batch_atts_opt = []
batch_inputs_opt = []
for b, n in enumerate(samples["n_answers"]):
# question
batch_input_tokens_input_ids += [input_tokens.input_ids[b]] * n
batch_input_tokens_atts += [input_tokens.attention_mask[b]] * n
# image
batch_atts_opt += [atts_opt[b]] * n
batch_inputs_opt += [inputs_opt[b]] * n
batch_input_tokens_input_ids = torch.stack(batch_input_tokens_input_ids, dim=0)
batch_input_tokens_atts = torch.stack(batch_input_tokens_atts, dim=0)
batch_atts_opt = torch.stack(batch_atts_opt, dim=0)
batch_inputs_opt = torch.stack(batch_inputs_opt, dim=0)
#############
# image + question
encoder_atts = torch.cat([batch_atts_opt, batch_input_tokens_atts], dim=1)
# image + question + answer
encoder_atts = torch.cat([encoder_atts, output_tokens.attention_mask], dim=1)
# answer
targets = output_tokens.input_ids.masked_fill(
output_tokens.input_ids == self.opt_tokenizer.pad_token_id, -100
)
if self.prompt:
targets[:, : self.prompt_length] = -100 # do not apply loss to the prompt
###########
empty_targets_img = (
torch.ones(batch_atts_opt.size(), dtype=torch.long).to(image.device).fill_(-100)
)
empty_targets_question = (
torch.ones(batch_input_tokens_atts.size(), dtype=torch.long).to(image.device).fill_(-100)
)
targets = torch.cat([empty_targets_question, targets], dim=1)
# image + question + answer
targets = torch.cat([empty_targets_img, targets], dim=1)
###########
# question
inputs_embeds = self.opt_model.model.decoder.embed_tokens(batch_input_tokens_input_ids)
# image + question
inputs_embeds = torch.cat([batch_inputs_opt, inputs_embeds], dim=1)
# image + question + answer
inputs_embeds = torch.cat([inputs_embeds, self.opt_model.model.decoder.embed_tokens(output_tokens.input_ids)], dim=1)
with self.maybe_autocast():
outputs = self.opt_model(
inputs_embeds=inputs_embeds,
attention_mask=encoder_atts, # image + question + answer
# decoder_attention_mask=output_tokens.attention_mask,
return_dict=True,
labels=targets, # image + question + answer
)
loss = outputs.loss
return {"loss": loss}