rust
 rust copied to clipboard
rust copied to clipboard
Improve performance of stable sort
This reworks the internals of slice::sort. Mainly:
- Introduce branchless swap_next_if and optimized sortX functions
- Speedup core batch extension with sort16
- Many small tweaks to reduce the amount of branches/jumps
This commit is incomplete and MUST NOT be merged as is. It is missing Copy detection and would break uniqueness preservation of values that are being sorted.
This initially started as an exploration to port fluxsort to Rust. Together with ideas from the recent libcxx sort improvement, namely optimal sorting networks, this PR aims to improve the performance of slice::sort.
Before submitting this PR, I wanted good answers for these two questions:
- How can I know that it works correctly?
- How can I know it is actually faster?
Maybe I've used it wrong, but I did not find a comprehensive set of tests for sort in the std test suite. Even simple bugs, manually added to the existing code, still passed the library/std suite. So I embarked on creating my own test and benchmark suite https://github.com/Voultapher/sort-research-rs. Having a variety of test types, pattern and sizes.
How can I know that it works correctly?
- The new implementation is tested with a variety of tests. Varying types, input size and test logic
- miri does not complain when running the tests
- Repeatedly running the tests with random inputs has not yielded failures (In its current form. While developing I had many bugs)
- Careful analysis and reasoning of the code. Augmented with comments.
- debug_asserts for invariants where doing so is reasonably cheap
- Review process via PR
- Potential nightly adoption and feedback
How can I know it is actually faster?
Benchmarking is notoriously tricky. Along the way I've mad all kinds of mistakes, ranging from false randomness. Not being representative enough. Botching type distributions and more. In it's current form the benchmark suite tests along 4 dimensions:
- Input type
- Input pattern
- Input size
- hot/cold prediction state
input type
I chose 5 types that are to represent some of the types users will call this generic sort implementation with:
i32basic type often used to test sorting algorithms.u64common type for usize on 64-bit machines. Sorting indices is very common.StringLarger type that is not Copy and does heap access.1kVery large stack value 1kb, not Copy.f12816 byte stack value that is Copy but has a relatively expensive cmp implementation.
Input pattern
I chose 11 input patterns. Sorting algorithms behave wildly different based on the input pattern. And most hight performance implementation try to be some kind of adaptive.
- random
- random_uniform
- random_random_size
- all_equal
- ascending
- descending
- ascending_saw_5
- ascending_saw_20
- descending_saw_5
- descending_saw_20
- pipe_organ
For more details on the input patterns, take a look at their implementation.
Input size
While in general sorting random data should be n log(n), the specifics might be quite different. So it's important to get a representative set of test sizes. I chose these:
let test_sizes = [
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 13, 16, 17, 19, 20, 24, 36, 50, 101, 200, 500, 1_000,
2_048, 10_000, 100_000, 1_000_000,
];
hot/cold prediction state
Modern CPUs are highly out-of-order and speculative to extract as much Instruction Level Parallelism (ILP) as possible. This is highly dependent on speculation. And while the common way to do benchmarks is good to get reliable standalone numbers, their magnitude might be misleading in programs that do more than just calling sort in a tight loop. So I run every benchmark twice once via criterion iter_batched (hot) and iter_batch PerIteration with a function in-between that attempts to flush the Branch Target Buffer (BTB) and does a syscall for good measure too. The cold benchmarks are not necessarily representative for the absolute gains in a particular application, nor are the hot results. But together they give a decent range of possible speedups.
What makes a sort algorithm fast
Talking in depth about all kinds of sort algorithm would go too deep here, especially given, that this does not change the underlying algorithm. But merely augments it with branchless code that can extract more ILP. Broadly speaking a generic sorting algorithms runtime will depend on 3 factors:
- How cheap is your type to compare?
- How expensive is your type to move?
- How well can access to your type be predicted?
For example, a u64 is very cheap to compare, very cheap to move and many of them fit into a cache line. And only that cache line is needed to compare them. A type like u64 will give you pretty close to the maximum performance of the sorting algorithm. In contrast, String is potentially expensive to compare, relatively cheap to move and access is hard to predict. And a type like f128 (just a name used for testing, not an official literal) is rather expensive to compare, it does two f64 divisions for each comparison, is cheap to move, and access is easily predicted. Given the vast freedom Rust users have, the sort algorithm can only do a best effort for common use cases and be reasonably good in others. If you decompress files with each comparison, that will be your bottleneck. Rust users can implement arbitrarily expensive is_less functions, and the key metric for such cases is how many comparisons are performed by the implementation. As I was developing the optimisations, I took great care to ensure that not only was it faster, but also not significantly slower. For example by measuring the total comparisons done for each input, type + pattern + size combination.
For non Copy types the total comparisons done are roughly equal. For Copy types and random input, it's 6% more on average. And while at first it might seem intuitive that more comparisons means higher runtime. That's not true for various reasons, mostly cache access. For example sort_unstable does on average for random input, and input size > 20 14% more comparisons. There are even some pathological inputs such as pipe_organ where the merge sort with streak analysis is vastly superior. For u64-pipe_organ-10000 the stable sort performs 20k comparisons while unstable sort does 130k. If your type is expensive to compare, unstable sort will quickly loose its advantage.
Benchmark results
Which the 4 input dimensions, we get 2.5k individual benchmarks. I ran them on 3 different microarchitectures. Comparing new_stable with std_stable, gives us 15k data points. That's a lot and requires some kind of analysis. The raw results are here, feel free to crush the numbers yourself, I probably did some mistakes.
TLDR:
- The biggest winners are Copy types, in random order. Such scenarios see 30-100% speedup.
- Non Copy types remain largely the same, with some outliers that I guess are dependent on memory layout and alignment and other factors.
- Some scenarios see slowdowns, but they are pretty contained
- Wider and deeper microarchitectures see relatively larger wins (ie. current and future designs)
Test setup:
Compiler: rustc 1.65.0-nightly (29e4a9ee0 2022-08-10)
Machines:
- AMD 5900X (Zen3)
- Intel i7-5500U (Broadwell)
- Apple M1 Pro (Firestorm)
hot-u64 (Zen3)

This plots the hot-u64 results. Everything above 0 means the new implementation was faster and everything below means the current version was faster. Check out an interactive version here, you can hover over all the values to see the relative speedup. Note, the speedup is calculated symmetrically, so it doesn't matter which 'side' you view it from.
hot-u64-random <= 20 (Firestorm)

Interactive version here you have to scroll down a bit to get to random. But the other ones are interesting too of course.
hot-u64 (Firestorm)

Here you can see what I suspect is the really wide core flexing it's ILP capabilities, speeding up sorting a slice of 16 random u64 by 2.4x.
hot-u64 (Broadwell)

Even on older hardware the results look promising.
You can explore all results here. Note, I accidentally forgot to add 16 as test size when running the benchmarks on the Zen3 machine, the other two have this included. But from what I see the difference is not too big.
Outstanding work
- Get the
is_copycheck to work within the standard library. I used specialisation in my repo, but I'm not sure what the right path forward here would be. On the surface it seems like a relatively simple property to check. - Talk about the expected behaviour when
is_lesspanics insidesort16during the final parity merge. With the current double copy, it retains the current behaviour of leavingvin a valid state and preserving all its original elements. A faster version is possible, by omitting the two copy calls, and directly writing the result ofparity_mergeintoarr_ptr, however this changes the current behaviour. Shouldis_lesspanic,vwill be left in a valid state but there might be duplicate elements, losing the original set. The question is, how many people rely on such behaviour? How big of a footgun is that? Is the price worth having everyone pay it when they don't need it? Would documentation be enough?
A note on 'uniqueness preservation'. Maybe this concept has a name, but I don't know it. I did experiments of allowing the sort16 approach for non Copy types, however I saw slowdowns for such types, even when limiting it to relatively cheap to move types. I suspect Copy is a pretty good heuristic for types that are cheap to compare, move and access. But what makes them crucially the only ones applicable, is not panic safety as I initially thought. With the two extra copy's sort16 which could be done only for non Copy types, that part is solved. However, what memory location is dereferenced and used to call is_less is the tricky part. By creating a shallow copy of type and using that address to call is_less, if this value is then not copied back, and used along the chain as 'unique' object along the progress of code, you could observe that for all intents and purposes, the type that is in your mutable slice, is the one you put in there. But if you self modify yourself inside is_less this self modification can be lost. That's exactly what parity_merge8 and parity_merge do. The way they sweep along the slice overlapping between 'iterations' might compare something from src, copy it and then use src again for a comparison, but then later dest is copied back into v, which has only seen one of the comparisons. And crucially Cell is not Copy, which means such logical foot guns are not possible with Copy types, or not to my knowledge. I wrote a test for it here.
I would love to see if this improvement has any noticeable effect on compile times. Coarse analysis showed some places where the compiler uses stable sort with suitable types.
Future work
- For input_size <20 stable and unstable sort both use insertion sort, albeit slightly different implementations. The same speedups here could be applied to unstable sort.
- If I find the time I want to investigate porting the merge part of fluxsort and see if that speeds things up. My main worry is correctness. It's quite liberal in it's use of pointers and I've already discovered memory and logic bugs in the parts that I ported. For <16 elements its somewhat possible to think about in my head. But for general situations, I fear it might require formal verification, to attain the expected level of confidence.
- Use sort16 to speedup unstable sort, or in general look into improving unstable sort.
This is my first time contributing to the standard library, my apologies if I missed or got something important wrong.
Hey! It looks like you've submitted a new PR for the library teams!
If this PR contains changes to any rust-lang/rust public library APIs then please comment with @rustbot label +T-libs-api -T-libs to tag it appropriately. If this PR contains changes to any unstable APIs please edit the PR description to add a link to the relevant API Change Proposal or create one if you haven't already. If you're unsure where your change falls no worries, just leave it as is and the reviewer will take a look and make a decision to forward on if necessary.
Examples of T-libs-api changes:
- Stabilizing library features
- Introducing insta-stable changes such as new implementations of existing stable traits on existing stable types
- Introducing new or changing existing unstable library APIs (excluding permanently unstable features / features without a tracking issue)
- Changing public documentation in ways that create new stability guarantees
- Changing observable runtime behavior of library APIs
r? @Mark-Simulacrum
(rust-highfive has picked a reviewer for you, use r? to override)
The job mingw-check failed! Check out the build log: (web) (plain)
Click to see the possible cause of the failure (guessed by this bot)
configure: rust.debug-assertions := True
configure: rust.overflow-checks := True
configure: llvm.assertions := True
configure: dist.missing-tools := True
configure: build.configure-args := ['--enable-sccache', '--disable-manage-submodu ...
configure: writing `config.toml` in current directory
configure:
configure: run `python /checkout/x.py --help`
Attempting with retry: make prepare
---
skip untracked path cpu-usage.csv during rustfmt invocations
skip untracked path src/doc/book/ during rustfmt invocations
skip untracked path src/doc/rust-by-example/ during rustfmt invocations
skip untracked path src/llvm-project/ during rustfmt invocations
Diff in /checkout/library/alloc/src/slice.rs at line 1037:
|| (n >= 3 && runs[n - 3].len <= runs[n - 2].len + runs[n - 1].len)
|| (n >= 4 && runs[n - 4].len <= runs[n - 3].len + runs[n - 2].len))
{
- if n >= 3 && runs[n - 3].len < runs[n - 1].len {
- Some(n - 3)
- Some(n - 2)
- }
- }
+ if n >= 3 && runs[n - 3].len < runs[n - 1].len { Some(n - 3) } else { Some(n - 2) }
None
}
}
Running `"/checkout/obj/build/x86_64-unknown-linux-gnu/stage0/bin/rustfmt" "--config-path" "/checkout" "--edition" "2021" "--unstable-features" "--skip-children" "--check" "/checkout/library/alloc/src/vec/spec_extend.rs" "/checkout/library/alloc/src/vec/partial_eq.rs" "/checkout/library/alloc/src/vec/splice.rs" "/checkout/library/alloc/src/vec/mod.rs" "/checkout/library/alloc/src/vec/is_zero.rs" "/checkout/library/alloc/src/vec/cow.rs" "/checkout/library/alloc/src/vec/spec_from_elem.rs" "/checkout/library/alloc/src/slice.rs"` failed.
If you're running `tidy`, try again with `--bless`. Or, if you just want to format code, run `./x.py fmt` instead.
That looks really nice. There is another PR #90545 improving std::sort, did you compare the performance of these two?
@EdorianDark I'm running some benchmarks tonight, preliminary results suggest it is slightly faster than the existing sort, but significantly slower than new_stable for copy types. From what I can tell, the discussion in the PR seems to be stuck at verification of the algorithm. One significant difference here is, that this PR does not change the core algorithm. It speeds up providing a minimum sorted slice, so it should be much easier to proof to a reasonable degree that this is as correct as the previous version. And thank you for pointing out that other PR, I was not aware of it.
Plus I just discovered UB by running my test suite with miri and the proposed wpwoodjr_stable_sort.
The job mingw-check failed! Check out the build log: (web) (plain)
Click to see the possible cause of the failure (guessed by this bot)
configure: rust.debug-assertions := True
configure: rust.overflow-checks := True
configure: llvm.assertions := True
configure: dist.missing-tools := True
configure: build.configure-args := ['--enable-sccache', '--disable-manage-submodu ...
configure: writing `config.toml` in current directory
configure:
configure: run `python /checkout/x.py --help`
Attempting with retry: make prepare
Regarding the failing test, I'm not sure what the expected behaviour should be.
// Sort using a completely random comparison function.
// This will reorder the elements *somehow*, but won't panic.
let mut v = [0; 500];
for i in 0..v.len() {
v[i] = i as i32;
}
v.sort_by(|_, _| *[Less, Equal, Greater].choose(&mut rng).unwrap());
v.sort();
for i in 0..v.len() {
assert_eq!(v[i], i as i32);
}
A simplified example:
input:
[2, 1, 8, 4, 11, 5, 5, 0, 5, 11, 0, 6, 7, 10, 9, 15, 16, 17, 18, 19]
new_stable_sort::sort_by produces:
[0, 0, 1, 2, 4, 5, 5, 5, 6, 7, 8, 9, 10, 11, 11, 15, 16, 17, 18, 19]
The implementation of sort16 assumes the user correctly implemented Ord for their type. Given that sort16 should only be called for Copy types the result is memory safe, but changes the existing behaviour. The question is, how far do we want to go to give people violating the Ord API contract 'sensible' results. Looking at the comment above, the intent of the test seems to be, to ensure that this won't panic, and or violate memory safety. If users mess up Ord their results will most likely not be what they expected anyway, the result cannot logically be considered sorted after sort completes. There is even an argument to be made, for surfacing such API violations more prominently, as for example integer overflow does for debug builds.
I don’t really like those relative speedup graphs, since they paint a skewed/biased picture of what’s happening: E.g., if the new implementation is twice as fast, it’ll say +100%, but if the old implementation is twice as fast, it’ll only say -50%. Unless I understand something wrong here. Anyways, I would prefer some non-biased statistics where both algorithms are treated the same, not one is arbitrarily chosen to always be the basis for determining what “100%” means.
Edit: Actually… I just noticed numbers below -100% on this page, so perhaps the situation already is different than what I assumed and below zero, the roles switch?
@Frank I fully agree about 'directional' speedup graphs. This one is deliberately symmetric. Which means +100% means the new one is twice as fast as the old one. -100% means the old one is twice as fast as the new one. IIRC I mentioned this property in the PR description.
On 27. Aug 2022, at 12:03, Frank Steffahn @.***> wrote:
I don’t really like those relative speedup graphs, since they paint a skewed/biased picture of what’s happening: E.g., if the new implementation is twice as fast, it’ll say +100%, but if the old implementation is twice as fast, it’ll only say -50%. Unless I understand something wrong here. Anyways, I would prefer some non-biased statistics where both algorithms are treated the same, not one is arbitrarily chosen to always be the basis for determining what “100%” means.
— Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you authored the thread.
@Voultapher Oh… right, you did mention there that it’s symmetric. Maybe it’d be easier to find if it was mentioned inside of the graph, too 😇 E.g. where it currently says “100% = 2x”, it could clarify e.g. with something like “100% = 2×, −100% = 0.5×”. Perhaps even additional data points like “50% = 1.5×, −50% = 0.667×”.
On a related note, it isn’t clear to me whether the linked results about # of comparisons is a symmetrical or an asymmetrical percentage. (I would probably assume those are asymmetrical though, looking at the numbers so far.)
[ @Voultapher by the way, you had tagged the wrong person; careful with using @-sign in e-mail ;-) – also, since you’ve responded by e-mail you might have missed my edit on my first comment where I had already noticed some values below -100% on some linked graphs ]
Indeed I currently have no access to my computer and will take a closer look on Monday. Good point about tagging, I didn't realize it turns into an actual tag, my apologies to whoever I've tagged now. Regarding the comparison diff, it's not symmetric. Back when I wrote that analysis code I hadn't yet figured out a good way to visualize difference in a symmetric way yet. If deemed important I can look at it again.
On 27. Aug 2022, at 16:10, Frank Steffahn @.***> wrote:
[ @Voultapher by the way, you had tagged the wrong person; careful with using @-sign in e-mail ;-) – also, since you’ve responded by e-mail you might have missed my edit on my first comment where I had already noticed some values below -100% on some linked graphs ]
— Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you were mentioned.
@Mark-Simulacrum I just noticed you changed the label from waiting on review to waiting on author. I'm waiting on review, regarding the failing CI, I commented about it here https://github.com/rust-lang/rust/pull/100856#issuecomment-1225999974. I could of course disable the failing test, but as I noted earlier I'm not sure what the expected behaviour ought to be.
The code sample in https://github.com/rust-lang/rust/pull/100856#issuecomment-1225999974 seems to have both a sort_by (which is random) but then follows that with a regular sort() call. I think any changes in this PR should preserve behavior; even an incorrect Ord/PartialOrd impl shouldn't cause us to end up with a different set of elements in the array, so the subsequent sort should bring it back in order. Changing the specific results of the sort_by seems OK though; we don't need to guarantee the same set of cmp(..) calls or exact same results, so long as we still end up with a stable ordering.
As an aside, it looks like this PR's diff currently is such that it replaces the main body of the implementation too, even if it doesn't actually change it (hard to tell). As-is, it would require basically a fresh review of the whole sort algorithm which won't happen soon.
even an incorrect Ord/PartialOrd impl shouldn't cause us to end up with a different set of elements in the array
Good point, it seems that items are being duplicated and others are silently leaked. With types that impl Drop this might lead to a double free.
@est31
Good point, it seems that items are being duplicated and others are silently leaked. With types that impl Drop this might lead to a double free.
Please read the comments and implementation. This would only happen for types that implement Copy, these types cannot have custom Drop implementations.
@est31
Good point, it seems that items are being duplicated and others are silently leaked. With types that impl Drop this might lead to a double free.
Please read the comments and implementation. This would only happen for types that implement
Copy, these types cannot have customDropimplementations.
I would assume that it’s a sane use-case of sort_by to run it on a Vec<*const T> with some user-defined (and hence untrusted) (&T, &T) -> Ordering callback, in the context of a data structure that manually manages the memory for the T’s which are semantically assumed to be owned by the *const T. *const T is a Copy type.
I wonder if the faster sorting could be enabled for a set of trusted types like &str, integers, etc. where we provide the Ord impl so we trust it. And only enabling it if you are not doing sort_by. I guess it wouldn't even need to be Copy at that point, although that might be too dangerous as future extensions might cause scenarios where ordering can be customized in safe user code, idk.
Yeah, just because a type is Copy doesn't mean we can ignore such a basic property of sort (entry data is the same as exit data, just reordered). Raw pointers are an example of how that can go wrong in practice, but even sorting &T would run into this. My guess is that many users calling sort_by may actually have a not-correct ordering function, and we shouldn't break entirely on that. If we panicked that would be a plausible discussion but randomly duplicating elements isn't acceptable.
I wonder if the faster sorting could be enabled for a set of trusted types like &str, integers, etc. where we provide the Ord impl so we trust it.
It’s hard to draw a line. usize or u32 could be a memory offset, too, indicating an owned memory location. Especially in a vector where u32 or even u16 might be chosen for memory efficiency, and the Vec<u16> is stored alongside some base pointer.
@Mark-Simulacrum thanks for the feedback.
As an aside, it looks like this PR's diff currently is such that it replaces the main body of the implementation too, even if it doesn't actually change it (hard to tell).
Both of them are still called merge_sort, and putting them in a diff viewer yields:
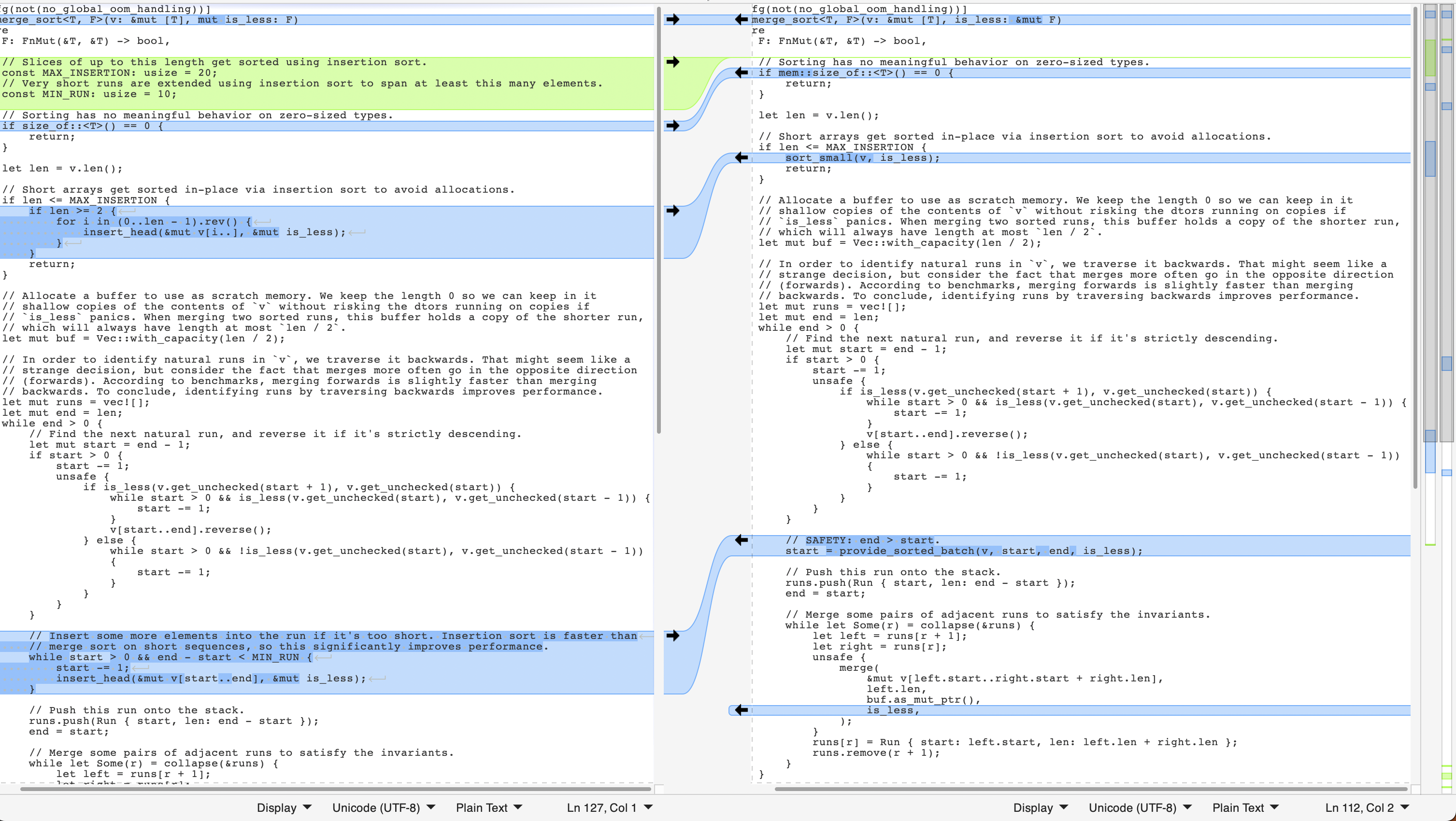
To me that seems relatively easy to review. If you think otherwise please explain why.
OK though; we don't need to guarantee the same set of cmp(..) calls or exact same results, so long as we still end up with a stable ordering.
We literally cannot end up with a stable ordering if Ord is being violated. The API contract of sort is that you give it a mutable slice and it modifies said slice in place so that it is now sorted. Comparing that to the API contract of i8:add you give it an i8 and you get back a new i8 that represents the sum of both integers. However what should happen if you provide 100i8 + 50i8? Logically the result cannot be an i8, but it must be an i8. Clearly when I add two numbers I expect back a number, and not an exception/panic. Rust realises that the operation we performed most likely represents a logic error and thus yields a panic in debug builds to inform us that what we attempted doesn't make sense. In release builds due to the performance impact of checking and panic some other implementation defined behaviour happens. In neither case UB ensues, but in both situations a logic error happened. I argue that the situation with sort is very similar. If you ask to sort something while violating Ord, that's a logic error. You will not have a sorted slice at the end. How about this idea? Mimicking integer overflow, for debug builds we add a check that tries to detect Ord violations and panics, and for release builds we document that some implementation defined behaviour happens, for example element duplication, but no UB. Rust is all about writing robust software and one way it achieves it, is by turning logic errors into errors as early as possible.
It’s hard to draw a line. usize or u32 could be a memory offset, too, indicating an owned memory location. Especially in a vector where u32 or even u16 might be chosen for memory efficiency, and the Vec
is stored alongside some base pointer.
Yeah this wouldn't technically violate Rust's safety rules, as there needs to be some unsafe code to execute drops multiple times or whatever, but it can lead to buggy behaviour of programs, and when it is combined with unsafe code that assumes the sort implementation doesn't duplicate items, then it can still lead to UB.
Anyways, I think this PR can be saved by my proposal.
This duplication only occurs with buggy sort_by/sort_by_key/Ord implementations. From my understanding, sorting an array of integers with the builtin Ord implementation is 100% safe. Speeding up just this use case is what I propose.
From my understanding, sorting an array of integers with the builtin Ord implementation is 100% safe. Speeding up just this use case is what I propose.
Ah, sorry, I missed that point on the first read. Yes, doing it for trusted Ord implementations (i.e. on trusted types, and only for .sort(), not for .sort_by()) sounds good.
@steffahn good points I hand't thought about pointers and in general unsafe code. Arguably the integer overflow comparison holds to some degree, given that offset calculation overflow could cause UB and thus unsafe code relying on logic errors to avoid UB seems like a brittle guarantee.
I'll look into detecting Ord violations for debug builds, and maybe some way to change sort16 in particular parity merge, that avoids said problem, but I'm not sure I'll find something efficient.
@est31 I'd prefer finding a solution that also works for user provided types, but if we cannot find such solution. We could fall back to implementing some unsafe marker trait for integers and tuples of integers, which see the largest speedup anyway.
for release builds we document that some implementation defined behaviour happens, for example element duplication, but no UB
I think the argument is that element duplication is UB. Even for Copy types, where it’s not technically directly UB, it’s still too dangerous; especially since it’s not something already explicitly documented, and especially since it’s only “allowed” in the first place due to specialization (i.e. a specialization-free generic implementation could never safely duplicate items; and such parametric reasoning is actually really powerful and common, at least in my experience coming from Haskell).
The only things that should be allowed in my opinion for safe implementation defined behaviour would be to leave the items in an arbitrary order, do an arbitrary number of additional comparison calls and optionally to panic (or maybe even abort or loop indefinitely). (If it wasn’t operating on a slice which can’t shrink, then dropping or leaking elements would be fine, too.)
Other weird stuff that only becomes possible with specialization should be ruled out as well. E.g. if you sort a list of u32 you would never expect to get an u32 in your output list that you didn’t put in, even though arbitrary arithmetic becomes possible with specialization. It would be too hard to put a bound at all on “implementation defined behavior” of generic functions if you weren’t able to at least reason about generic functions as if specialization wasn’t a thing (which arguably it actually isn’t anyways, in stable Rust).
I'm also not sure that we should optimize stable sort for primitives, where stability doesn't actually matter -- I would expect unstable sort to be what we encourage in that case. https://rust-lang.github.io/rust-clippy/master/index.html#stable_sort_primitive indeed suggests as such.
Our unstable sort isn't quite as good in all cases, it seems, per https://github.com/rust-lang/rust-clippy/issues/8241, but I think investing there seems like a better option than complicating stable sort with a bunch of special-case code around sorting a small subset of types. Having a performance drop when wrapping u32 in struct MyType(u32) is also a cost, and in some ways a more painful one then a consistent implementation that's maybe not quite as optimal as it could be.
@Mark-Simulacrum as a note, if we can get sort16 into a usable form here, it can also be applied to unstable sort and yield speedups there.
:umbrella: The latest upstream changes (presumably #101816) made this pull request unmergeable. Please resolve the merge conflicts.