llama_index
 llama_index copied to clipboard
llama_index copied to clipboard
How to fixed "ValueError: A single term is larger than the allowed chunk size."
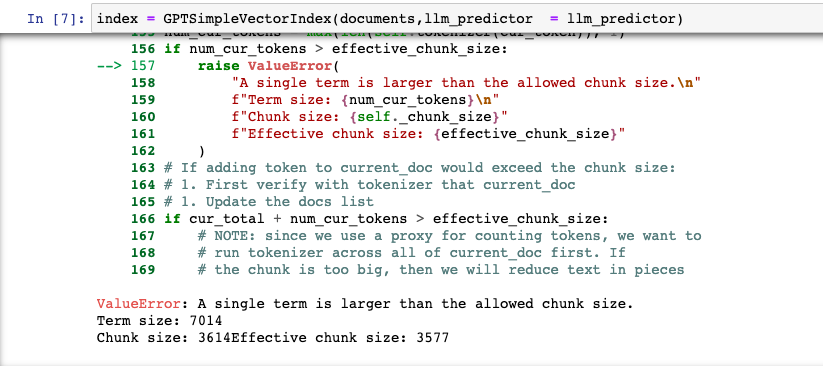
Error msg: ValueError: A single term is larger than the allowed chunk size. Term size: 510 Chunk size: 379Effective chunk size: 379

I just cloned the master branch code last night, so it should be the latest version of the code.
OK, I just use new content to replace file content in "examples/test_wiki/data/nyc_text.txt".
Attachment is my new content.
Comment " request wiki content write to nyc_text.txt" code when you run "examples/test_wiki/TestNYC.ipynb".
I have upgraded llama_index to version 0.4.21 and I am still experiencing some issues. Additionally, I was wondering if you could provide me with some guidance on which method would be best suited to load the documents?
It might be a Chinese only issue. I replaced all , as , , now it works.
One possible reason is that Chinese is NOT separated by spaces like English or other latin languages.
This should be fixed with the upcoming release! I took a stab in #628 #629 - we hard force splits if the default separator (space) doesn't work
though of course if @yirenkeji555 if you have sample data for me to repo, i can verify
though of course if @yirenkeji555 if you have sample data for me to repo, i can verify
same issue on 0.4.24. here is the sample data https://cdn.discordapp.com/attachments/899657146143232011/1083317634382180362/Bookandswordenmityrecord.txt
same issue on 0.4.24. here is the sample data
https://ethbill.s3.ap-southeast-1.amazonaws.com/1.txt @jerryjliu
same issue on 0.4.28. here is the sample data
https://mp.weixin.qq.com/s/eAP2_TUyoF9uVjUb6cUWYw
Hey all,
sorry for the delay on this. Will take a look at sample data that some of you have provided and fix soon. In the meantime you can try manually setting the chunk size through chunk_size_limit when building the index
Currently, the encoding method used by globals_helper.tokenizer will result in a much higher token count when calculating the number of tokens in Chinese text.
For example:
text = '唐高宗仪凤二年春天,六祖大师从广州法性寺来到曹溪南华山宝林寺,\
韶州刺史韦璩和他的部属入山礼请六祖到城裡的大梵寺讲堂,为大众广开佛法因缘,演说法要。\
六祖登坛陞座时,闻法的人有韦刺史和他的部属三十多人,以及当时学术界的领袖、学者等三十多人,\
暨僧、尼、道、俗一千馀人,同时向六祖大师礼座,希望听闻佛法要义。'
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
print(len(encoding.encode(text)))
# 218
encoding = tiktoken.get_encoding("gpt2")
print(len(encoding.encode(text)))
# 342
In the case of mixed Chinese , English and various symbols, the discrepancy in the calculation results can even reach several times. So, when I chandged the encoding method and reduced the size for each chunk, error was gone.
I have the same problem:
ValueError: A single term is larger than the allowed chunk size.
Term size: 673
Chunk size: 500Effective chunk size: 500
The source code is as follows, and the data is shown in the attachment
# coding=utf8
from llama_index import GPTSimpleVectorIndex, Document
import os
def main():
os.environ['OPENAI_API_KEY'] = 'sk-XX'
os.environ['CURL_CA_BUNDLE'] = ''
# Loading from strings, assuming you saved your data to strings text1, text2, ...
with open(file="wiki_kuangbiao.txt", mode="r", encoding="utf-8") as f:
text_wiki_kuangbiao = f.read()
text_list = [text_wiki_kuangbiao, ]
documents = [Document(t) for t in text_list]
# Construct a simple vector index
index = GPTSimpleVectorIndex(documents, chunk_size_limit=500)
# Save your index to a index.json file
index.save_to_disk('index_wiki_kuangbiao.json')
# Load the index from your saved index.json file
index = GPTSimpleVectorIndex.load_from_disk('index_wiki_kuangbiao.json')
# Querying the index
response = index.query("《狂飙》男一号是?")
print(response)
if __name__ == '__main__':
main()
i have to set chunk_size_limit to about 2000 to avoid this error, any better solutions?
I got same issue. And I fixed by this way. It work fine to me.
MAX_TEXT_INLINE = 100
def trim_text(text):
"""
Trim text
@param text:
@return:
"""
text = text.strip()
text = re.sub('\s+', ' ', text)
text = re.sub('\n+', '\n', text)
return text
def limit_line_length(text):
"""
Limit line length
@param text:
@return:
"""
lines = []
for line in text.split('\n'):
chunks = [line[i:i+MAX_TEXT_INLINE] for i in range(0, len(line), MAX_TEXT_INLINE)]
lines.extend(chunks)
return '\n'.join(lines)
########################
documents = SimpleDirectoryReader(folder_path).load_data()
for document in documents:
document.text = utils_service.limit_line_length(utils_service.trim_text(document.text))
The problem is that default separator for splitting text in TokenTextSplitter is " ". But in languages like Chinese, there might be long text chunks without any whitespaces. So the easiest fix is to increase the chunk_size_limit. Or you need to roll out your own text preprocessor, for example:
for doc in documents:
# replace all Chinese periods to add whitespaces
doc.text = doc.text.replace("。", ". ")
is there any update on this one please? it is related to pull request #1354 please?