quadratic
 quadratic copied to clipboard
quadratic copied to clipboard
Standardize Cell References
Standardize cell reference support across Quadratic.
Python Formulas UI/UX (Goto Menu, etc)
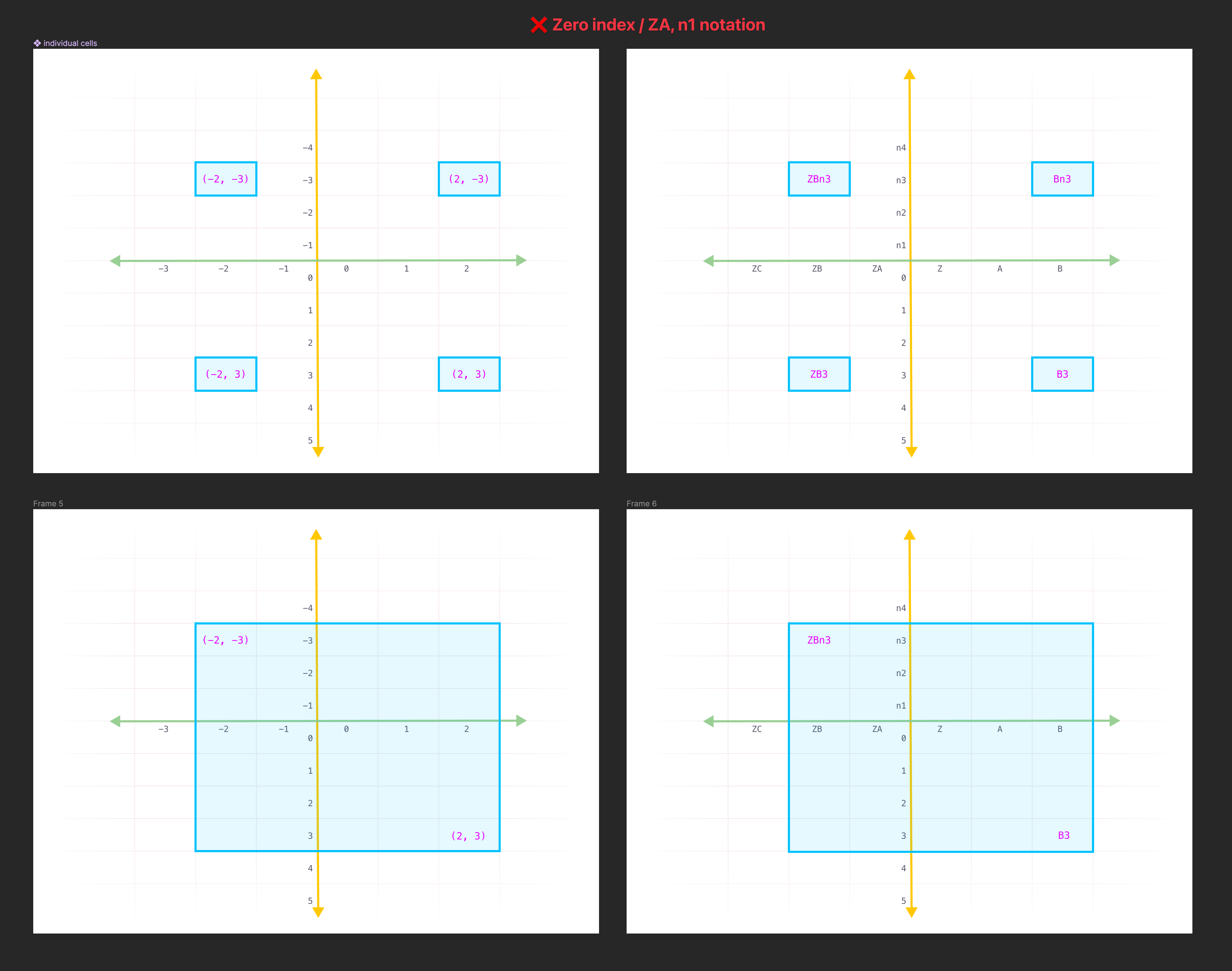
Absoulute Reference Types: (x, y) [y, x] "A1"
Relative Reference Types: ...
Starting at Z still throws me off (Z0).
I get that spreadsheets start at A1 but if we have to start at 0 on the y axis, A0 would still feel more intuitive to me than Z0. Is there a reason why we can't do this? That wouldn't really change the going backwards I don't think? You'd still just go B -> A -> ZA -> ZB
Then on the other end, rather than going X -> Y -> AA -> AB you'd just do the more natural, intuitive X -> Y -> Z -> AA -> AB

As I was working on the docs explanation, it was reinforced to me how confusing the negative values can be as you try to work with cell coordinates, especially in A1 notation.
I think there are two things going on that add layers of confusion:
- Our rows/columns start at a zero-index, which is a known thing to programmers, but confusing to people outside of that group.
- We use two different notations for negative values in the
A1notation:ZAon the x-axis,n1on the y-axis.
Because of no. 1 above, you encounter an asymmetry on the grid given identical coordinates in different quadrants of the grid.
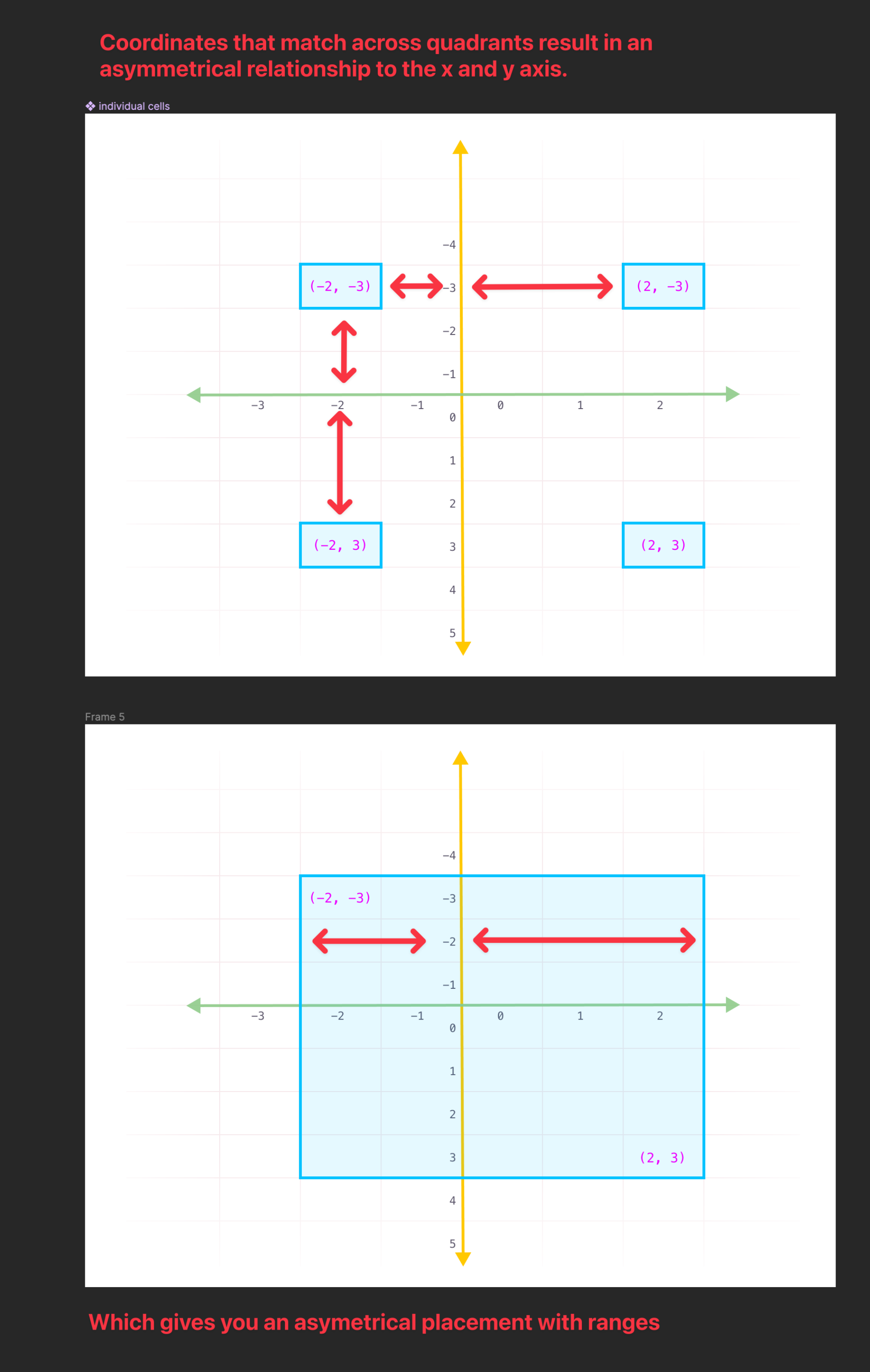
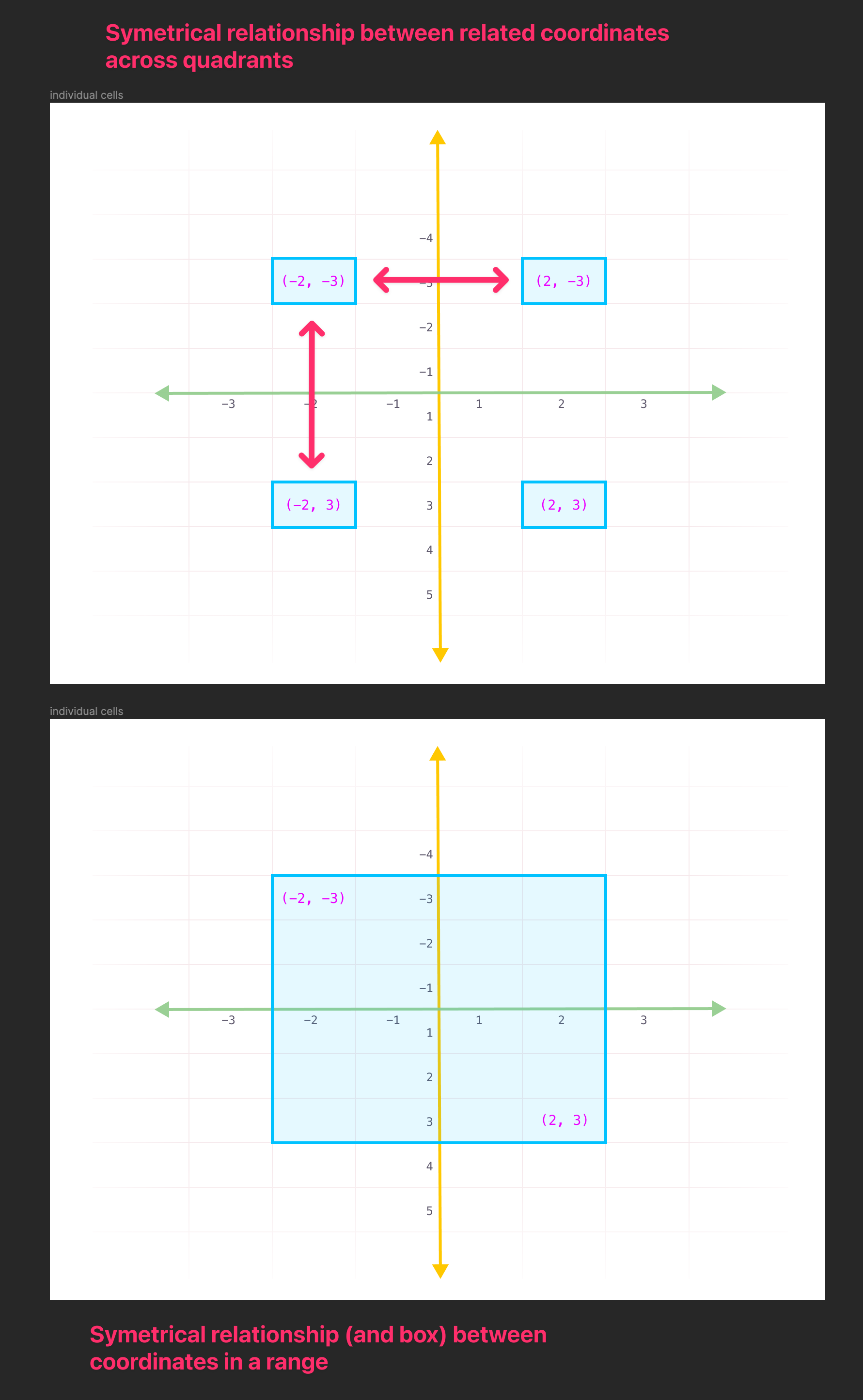
Whereas, for example, if we started our numbering the same way spreadsheets do, at (1, 1) or A1, then related coordinates across quadrants would give you a symmetry across the x and y axis.
When you extend this idea to the A1 notation you see the same results. To compound that, you have point no. 2 above which is that we use different syntax to represent the idea of a "negative" value: ZA on the x-axis, n1 on the y-axis.
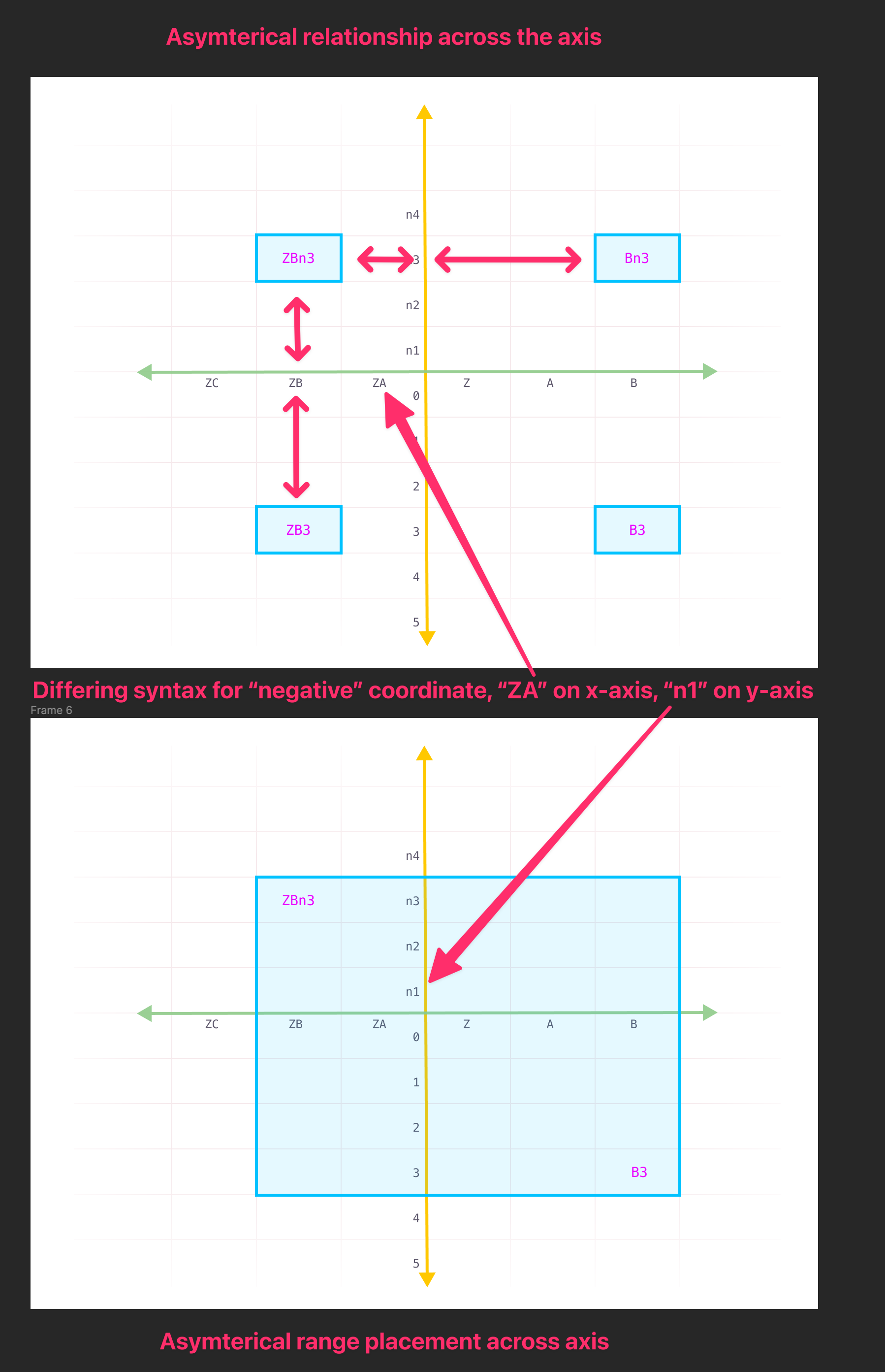
Plus we also deviate from spreadsheets by starting our origin at Z0 instead of A1 which is a common thing spreadsheets have done since...well, maybe forever.
I think this makes things really confusing to visualize when you're working with coordinates in your formulas. Can you parse the range ZDn3:D3 and visualize it in your head?
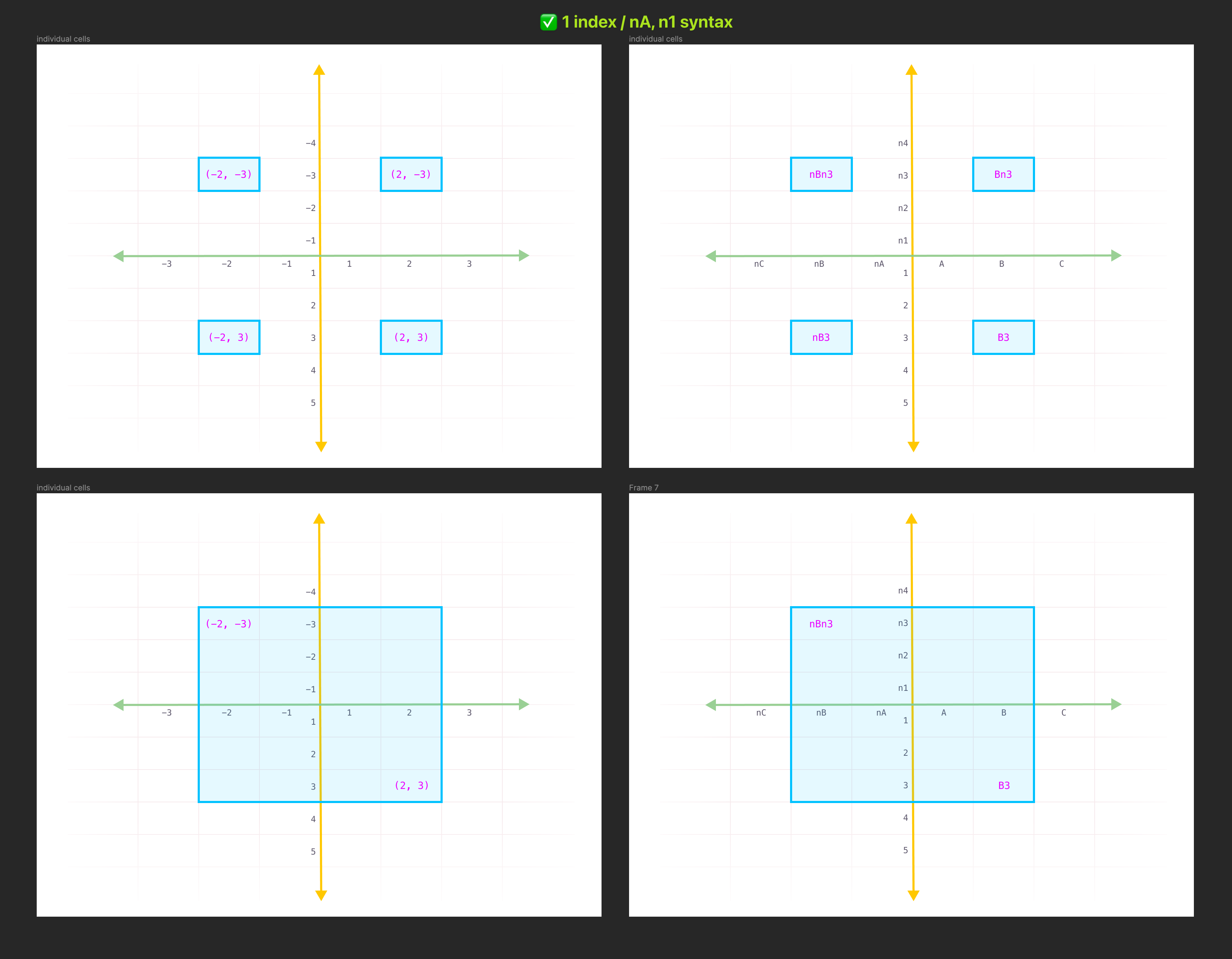
Now, what if we started our origin at (1, 1) (A1) and only used a single syntax, the n for indicating "negative values? In other words: instead of ZA you have nA. This would give you the same syntax for indicating a negative value regardless of whether you're dealing with the x or y axis. I think that greatly simplifies parsing and writing cell coordinates.
For example: which range is easier to understand at a glance: ZDn3:D3 or nDn3:D3? I would argue the later because you only have to learn one concept: n is "negative". There's a symmetry in this notation, even as you extend out into far ranges, e.g. a range like nAAAn1:AAA1.
To extend this concept even further, nAA1 and AA1 are both the exact same distance from their respective x and y axis. It's easy to visualize this concept in your head, whereas our syntax today would express it as ZAA1 and AA1. One is much easier to reason about in your head IMO.
In short, my suggestion that I'm formulating in my head is that we do two things:
- Change the origin to be
(1, 1)(A1) - Get rid of the
ZA,ZB,ZCnotation for negative x-axis values and use the samensyntax we use on the x-axis, e.g.nA,nB,nC
To contrast those two, look at these examples.
Old way:
New way:
What are the downsides to this approach?
- File schema changes?
- Do people expect, and want, to have a zero-index number system for coordinates? Certainly they don't in spreadsheets (e.g. formulas) but would people working in python be thrown off by it?
Great writeup Jim. 1 index / nA, n1 syntax is really appealing to me. It seems to make the most sense
I agree! I'm not super keen on what it'll do to the internal code (I think it'll be nicest to have A1 to be (0, 0) for modular arithmetic things like quadrants) and Python indexing (what is c(0, 0): invalid, A1, or nAn1?) but it certainly looks nicer UI-wise