quadratic
 quadratic copied to clipboard
quadratic copied to clipboard
Cell indexing counterintuitive for Pandas/Numpy users
Currently cell(a, b) refers to column a, row b.
In Pandas and Numpy df.iloc[a, b] or arrray[a, b] refer to row a, column b.
I think that changing the indexing order in the cell() and cells() functions would improve consistency for python users.
For reference, the ADDRESS function in excel and google sheets also uses (row, column) indexing like Pandas/Numpy.
Great observation.
We are also working on optional support for A1/R1C1 notation in the future.
How do you like our design for cell references overall? Is there anything you would change about it?
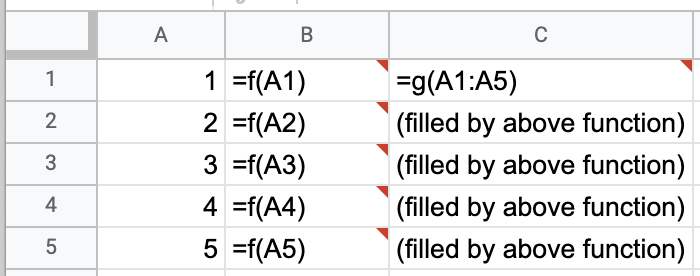
A1/R1C1 would definitely be useful if you're writing functions in an excel-like fashion mapping single cells to single cells as illustrated in column B.
If you're writing in a more pythonic fashion, mapping tables to tables as illustrated in column C, I have a couple of thoughts:
- Mirroring the array indexing in Python/Numpy might be more intuitive and flexible than
cell()andcells(). i.e. have something likegrid[row,col],grid[row_min:row_max,row_min:row_max]. - It would be useful to be able to propagate changes in the input table size to the output table size. e.g. If column A was increased to 10 rows, column C would also be increased. Specifying the top left cell of a table (
g(A1)) instead of hard-coding the range of cells (g(A1:A5)) might be an option. You'd have to think about the syntax and how to differentiate single cell inputs vs table inputs.
FYI: I experimented with implementing the numpy-like indexing. You can see what it involves here. Let me know if you're interested and I'll submit a PR. No problem either way. Honestly, I'm not really sure if it's worth adding multiple APIs at this point just to mirror Numpy, particularly given the additional complexity in passing parameters like first_row_header.
Going back to my original point, I think that just switching the indexing in cell and cells to row a, column b would make it intuitive enough for numpy/pandas users.
Thanks for the demo. Feel free to submit a pr, I would like to play around with it more.
Our goal is to make Quadratic very intuitive to use for both Pandas/Numpy/Scipy users as well as people coming from the Excel world. So it would be great to have more numpy-like cell indexing. We need to make sure the cell dependencies are still tracked properly so that when a referenced cell updates our cell pulling that data updates (like Excel).
Will need to do a bit more research on this. I think it's a great idea!
@boaarmpit, we merged your contributions a few weeks ago. I encourage you to check out Quadratic again now, we've made many improvements, including adding support for formulas.
I am going to mark this issue as closed. Please feel free to give additional feedback based on the current iteration of Quadratic we love your support and contributions.
David