voxelnet
 voxelnet copied to clipboard
voxelnet copied to clipboard
should we remove reflectance <= 0 points in data preprocess?
 Left keeps reflectance <= 0 points and right drop them, yellow is positive voxels and purple is negative. we can find that some important points are dropped.
Left keeps reflectance <= 0 points and right drop them, yellow is positive voxels and purple is negative. we can find that some important points are dropped.
Nice observation. I am investigating how this impacts the performances. Will update in next commit if necessary.
actually I can get 83/75/74 3d AP in my own implemention with your hyper parameters when keep reflectance==0 points, but my implemention has bad performance when drop reflectance==0 points.
I have solved the bug(not limit angles to pi/2) and train 20 epochs with reflectance==0 points, and get result: bv: 88.273483 86.023048 78.579391 3d: 87.182213 83.288345 76.851006 3d performance can greatly benefit from reflectance==0 points.
in the VFE layer, the reflectance is only part of the feature representation, XYZ coordination may contribute more in the entire architecture, checking the Loss Function, you may get the same conclusion.
reflection and other original feature, such as normal vector can promote the performance, but not necessary, same thing in other direct point cloud consuming architecture, e.g pointnet(++)...
@brb-chen this implemention currently remove all reflectance==0 points(not drop reflectance in feature encoding) in data preprocess so lots of positive voxels of hard examples are dropped, and leads to bad performance in moderate/hard eval. I have tested the network that use a single linear+norm layer instead of all VFE and get almost same performance(only train 5 epochs). you are right, XYZ coordination is the most important feature of all features.
@traveller59 keeping points with negative reflectance does also improve the performances in my case. It will be updated in next commit.
@qianguih there is a problem in your eval code, you should change overlap threshold {0.5, 0.25, 0.25} to official {0.7, 0.5, 0.5}
@haotians not now. due to a bug in eval code, the performance of my implemention is greatly decreased after fix that bug(3d 87,83,76->60,50,50), and greatly worse than official performance. I need to tune the model.
@traveller59 This implementation also has serious performance drop in 3d detection after the metrics are fixed. One potential bug is here. I am working on it and will update in next commit.
@qianguih you can try my eval code(pure python, takes only 10 seconds, need Anaconda) to do fast performance analysis. When training, you can remove all unknown examples and its points and use point cloud range: [0, -32.0, -3, 52.8, 32.0, 1] (xyzxyz in lidar) to increase training speed, after remove unknown examples, almost all examples are in [0, -32.0, -3, 52.8, 32.0, 1] I still have no idea that where the performance problem come from.
@traveller59 Thanks for sharing your code. It looks quite interesting. My implementation was able to achieve similar performances in bird view detection but failed to produce nice 3d detection results. I am still looking for bugs. if you have any, please feel free to share or create a pull request. : )
@qianguih I can get 70/59/58 3d mAP(30 epochs) with some changes(still under tuning):
- remove all empty anchors(contain no voxel, using summed-area algorithm), then every example has 5k-20k anchors
- balanced sample 512 anchors in every example(this may be the most important change)
- classification loss normed by num of positives + negatives, localization loss normed by num of positives
- positive class weight and negative class weight all equal to one, localization loss weight is 2
- score threshold=0.5
- use another iou calculation method(get nearest 'standing' or 'lying' bbox then calculate iou)
@traveller59
impressive result with 30 epochs, do you plan on sharing your code in the future ? the changes sound interesting but i think i don't understand all of them from just a few sentences.
- example = gt_object or frame? what is an empty voxel in the feature plane ? in my approach i filter all anchors that do not point into a (scaled) ground truth box, is it similar ?
- you randomly look at and evaluate 512 anchors per gt_object/frame or do you use something like a grid around a gt_center and limit the the anchors to evaluate by distance?
- here examples must be gt_objects right ?
@6. i think one could also compensate for the direction of the center offset relative to the object direction. an offset along the length axis of the object is better than an offset along the width axis of an object. it should be a bit more accurate this way for gt_objects with near diagonal orientations.
blue = ground truth, red anchor prediction without rotation
- image: ground truth (40° yaw) and anchor with perfect size estimation
- image: without compensation rotating ground truth to nearest orthogonal position.
- image: additionally rotate the anchor offset around the gt_center with -yaw gt. (all in range -45 to 45 °)
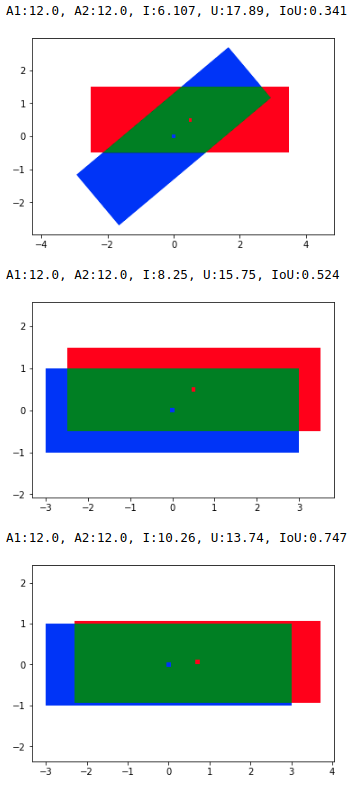
@johleh I remove all data augmentation but random flip to make network converge faster, so I can get good result in 30 epoch.
- 'example' means one data/image/pointcloud, do you have a better name because 'example' also means positive + negative in detection?
- sample 512 anchors in training, keep all in inference.
- number of examples means number of positives + negatives
- 6 is converted from avod. the most accurate way to calculate IoU is using rotate iou (official implementation, my numba.cuda version). but this will lead to too little positives. The avod approach looks better than the 'standup' in this implementation.
- code share: my implementation contains too much code relate to my own research, so I prepare to release code after reproduce official result successfully because arrange my code also takes time.
@johleh sorry I can't understand the compensate method, where do you do compensate, in anchor generation/preprocess or in postprocess?
@johleh I filter empty anchors by following step:
- get voxels, coors from a point cloud
- convert coors to a dense tensor
- sum the dense tensor in height axis
- get integral image of the dense tensor by cumsum
- convert anchors to integral image coordinate system
- use summed-area algorithm to determine whether the area of a anchor is zero. code:
def image_box_region_area(img_cumsum, bbox):
"""check a 2d voxel is contained by a box. used to filter empty
anchors.
Summed-area table algorithm:
==> W
------------------
| | |
|------A---------B
| | |
| | |
|----- C---------D
Iabcd = ID-IB-IC+IA
Args:
img_cumsum: [M, H, W](yx) cumsumed image.
bbox: [N, 4](xyxy) bounding box,
"""
N = bbox.shape[0]
M = img_cumsum.shape[0]
ret = np.zeros([N, M], dtype=img_cumsum.dtype)
ID = img_cumsum[:, bbox[:, 3], bbox[:, 2]]
IA = img_cumsum[:, bbox[:, 1], bbox[:, 0]]
IB = img_cumsum[:, bbox[:, 3], bbox[:, 0]]
IC = img_cumsum[:, bbox[:, 1], bbox[:, 2]]
ret = ID - IB - IC + IA
return ret
coors = coordinates
dense_voxel_map = np.zeros(grid_size[::-1])
dense_voxel_map[coors[:, 0], coors[:, 1], coors[:, 2]] = 1.0
dense_voxel_map = dense_voxel_map.sum(0)
dense_voxel_map = dense_voxel_map.cumsum(0)
dense_voxel_map = dense_voxel_map.cumsum(1)
vsize_bv = np.tile(voxel_size[:2], 2)
anchors_bv[..., [1, 3]] -= coors_range[1]
anchors_bv_coors = np.floor(anchors_bv / vsize_bv).astype(np.int64)
anchors_bv_coors[..., [0, 2]] = np.clip(
anchors_bv_coors[..., [0, 2]], a_max=grid_size[0] - 1, a_min=0)
anchors_bv_coors[..., [1, 3]] = np.clip(
anchors_bv_coors[..., [1, 3]], a_max=grid_size[1] - 1, a_min=0)
anchors_bv_coors = anchors_bv_coors.reshape([-1, 4])
anchors_mask = box_np_ops.image_box_region_area(
dense_voxel_map[np.newaxis, ...], anchors_bv_coors).reshape(-1) > 0
I don't know what does 'point into a (scaled) ground truth box' mean.
@traveller59 thank you for the quick reply, i still have some questions, i work on a pytorch implementation and it doesn't work nearly as well yet, so each answer you can share is very helpful to me.
- pointcloud/frame/image are all good :). the removal of empty anchors seems very important and makes a lot of sense with the cropped pointclouds, edit : thanks for the explanation/code!
- balanced sampling like avod mini batch sampling ? 1:1 neg:pos?
- interpretation a. unlike in the paper you divide both pos/neg loss by the sum of pos and neg examples, right ? images with many labels will have higher positive error than those with only a few, which makes sense to me because they contain more information about positive objects too. interpretation b. just like the paper states and i misunderstood.
- iou calculation + compensation: i recognized the avod method and i use it myself too. my approach is more centered on ground truth objects, for each ground truth object i only evaluate anchors that point into a ground truth box. (if their predicted center is not within the ground truth box, the anchor can't reach good iou anyways. eg. gt_box * 1.2 for 45% iou threshold) and then modify their centers relative to the angle that is used to rotate the ground truth in an orthogonal orientation. the overall number of positives should not change, it just accepts a few more where the offset is mainly along the longer axis (and therefore lower relative offset) and rejects a few more where the offset is mainly along the shorter axis of an object with near diagonal angle. in this implementation it would mean to take a label, modify all anchors, perform iou between anchors and only this label and repeat for all labels. But it should be only a small improvement for near diagonal labels and shouldn't have any effect if use no rotation-augmentation, because most labels are near the orthogonal axis in the kitti dataset.
- compensation step (or correction maybe better): correction angle = angle between ground truth and 0°/90° axis // difference to get orthogonal ground truth modified anchor_pred_ center_xy = rotate by negative correction angle( anchor_pred_center_xy - gt_center_xy ) + center_gt_xy // works for correction angles between -45° and 45°
- when using the avod iou-method i have a large disparity between the 2 anchor types. in the kitti set there are only about 1/6th ground truth labels that are lying down and these anchor boxes only see few positive examples for regression, learn slower and perform much worse for me. how did you solve that imbalance ?
@johleh actually my implementation contains both pytorch and tensorflow version that share same config and much code. all results in this issue are produced by pytorch code. After a night of training, I get following performance(best result, with all data aug, 136k step, batch_size=3):
Car [email protected], 0.70, 0.70:
bbox mAP:89.38, 82.90, 78.01
bev mAP:89.09, 83.14, 78.20
3d mAP:79.90, 64.82, 61.08
Car [email protected], 0.50, 0.50:
bbox mAP:89.38, 82.90, 78.01
bev mAP:96.83, 88.91, 88.03
3d mAP:90.15, 88.14, 86.66
aug steps:
gt_boxes, points = prep.random_flip(gt_boxes, points)
gt_boxes, points = prep.apply_noise_per_groundtruth(gt_boxes, points)
gt_boxes, points = prep.global_rotation(gt_boxes, points)
gt_boxes, points = prep.global_scaling(gt_boxes, points)
gt_boxes = prep.filter_gt_box_outside_range(gt_boxes, bv_range)
# limit rad to [-pi, pi]
gt_boxes[:, 6] = box_np_ops.limit_period(gt_boxes[:, 6], offset=0.5, period=2*np.pi)
if without data aug, network will overfit after 30 epochs.
- remove empty anchors doesn't have benefit if without sample in my case.
- yes, but number of positives is not enough to do 1:1 sampling.
- the norm method only affect pos/neg weights, 2d detectors in tensorflow use this norm approach. norm by number of pos/neg may change the score threshold but I guess it don't matter.
- The most important thing is you can't do compensation when inference, your compensation seems want to make anchors has more iou with groundtruth, but when inference, which anchors should the box predictions be linked to?
- I don't deal with this imbalance. the problem should come from other places.
thanks a lot for all these tips. it is good to know that the model works and that i just have to find the errors in my implementation
-
@4. yes it is just for training, and maybe it is not beneficial anyways (it should be good for detection, but maybe it is detrimental for regression). in inference i simply generate all anchor boxes and perform non maximum suppression.
-
@5. the imbalance is in the dataset there are mostly ground truth labels with the same orientation as the kitti car, maybe i do something wrong. do you regress both anchor types for each ground truth ? because one of the anchor boxes has very low iou when comparing to lying standing ground truth and i only choose the best anchor type and ignore the other one.
would it be possible to use 2 types of positive examples, one iou threshold to learn detection (could be higher, and even the exact 3D iou) and one iou threshold to choose the samples from which the model learns the bounding box regression (could be lower to start out with more examples) ?
@johleh 4. I'm not sure the compensation is beneficial for classification because this may force network learn a strange pattern, the approach in avod seems can make network pay more attention to centers in classification but I haven't observed significant error change in angles and centers. you can plot a pos/neg map to determine whether this approach can generate appropriate map. 5. each point in feature map will regress two offsets (0, pi/2). There is a imbalance for lying anchors in classification but this seems don't impact on network performance. I will try to assign weights for them later. In addition, I have tried to remove one anchor per localization by score in postprocess several weeks ago but had no benefit. so just regardless of this imbalance for now.
use different iou threshold between classification and regression should work but will force backbone network learn more features which may isn't beneficial to classification. you can add a sub-network for regression after reproduce official performance.
@traveller59
-
i think i understand the deleting empty voxels step. it is a sanity check that deletes all anchor proposals, where the proposed 2D box doesn't contain a single lidar point (summed up over height) . and is useful for both training and inference. in a trained model these deleted proposals shouldn't pass the detection threshold i guess or would be an indicator for heavy overfitting right ?
-
i overstated the imbalance, after looking again it is only about 3:1. standing : lying nevertheless how do you regress both anchor box types for one ground truth, would not a lying anchor_type have very low iou for a standing ground truth ? this is something i don't understand yet. As i understand it one takes the axis aligned anchor box proposals and compares them to the axis aligned ground truth box. This results in one type with perfect alignment and the other will be perpendicular. i only regress the aligned type because the other one is far below the threshold.
@johleh
- empty anchors should be completely removed. they indicate very easy examples that will dilute grads produced by important examples. if don't remove them when do balanced sampling, your sampled minibatch will contain too much empty and useless examples. In addition, if you train with all data aug, overfitting is not significant.
- iou between 'lying' or 'standing' is low, but you can't label a localization with 'lying' or 'standing' in inference, when training, network need to use negatives produced by 'wrong posture' anchors to do classification when inference.
@traveller59
- sorry i didn't want to suggest that you do it because of overfitting and i understand it greatly improves the quality of negative samples during training. i just tried to imagine how a trained model in inference mode would produce empty anchor proposals with higher confidence than the threshold, and overfitting was the first that came to my mind.
- yes i also use the results of both anchor types for the detection map, but for the regression/localisation/box error only one of the anchor types has a chance to generate positive samples. if one uses positive samples only for box regression, the lying anchor is trained with much less data in my case.
- when looking at the heatmaps i often observe the situation where 2 objects are close and object 1 is recognized well and object 2 is not. most of the anchors in that area learn to focus (predict centers) on the well recognized object 1, which leaves fewer anchors for the other one. with frame-wide balanced sampling one will get lots of positives for object 1 and only a few for object 2 (fewer anchors that focus, and those that do do not perform that well yet), but the model has to learn a lot more about object 2 to improve performance. i thought about additional balancing in a way that from every object a minimum share of positives is sampled.
- i might have a bug in my feature encoding, can you overfit the model on training data without augmentation ? i can't even do that.
@johleh What's your current performance in val kittiset? I have upload my result. but get worse performance than official, especially 3d: eval:
Car [email protected], 0.70, 0.70:
bbox mAP:90.46, 86.20, 79.58
bev mAP:89.87, 85.77, 79.25
3d mAP:82.75, 67.29, 64.46
test:
Car (Detection) | 89.50 % | 79.55 % | 77.81 %
Car (3D Detection) | 69.04 % | 59.75 % | 52.93 %
Car (Bird's Eye View) | 84.57 % | 78.02 % | 75.77 %
official test:
Car (Detection) | 90.30 % | 85.95 % | 79.21 %
Car (3D Detection) | 77.47 % | 65.11 % | 57.73 %
Car (Bird's Eye View) | 89.35 % | 79.26 % | 77.39 %
There are still some problems in my implementation. 2. you want 'wrong posture' anchors also do regression backward in training? This may beneficial for faster regression converge but your performance problem should from other place. 3. I don't have heatmap functions but I have a qt-based viewer to view anchors, 3d results, etc, and I haven't observed that phenomenon. The balanced sampling will keep almost all positives because of too little positives, so I can't understand why your object 1 has more anchors than object 2. I am using sampling method modified from FAIR Detectron 4. I have deleted that training log which is overfitting, could you provide something about your eval performance?
@traveller59 Did you preprocess the angle in other way? or you just disabled the angle limit function?
@LinHungShi I only limit angles to -pi~pi in preprocessing, you can try angle vector encoding described in AVOD.
@traveller59 thanks for your swift reply. According to readme file in development kit, it seems the angle is set within [-pi, pi] by default. Do you do anything else or just modify the function to limit it within [-pi, pi] ? Thanks~
@LinHungShi data augmentation such as global rotation and noise per object may cause angles out of range, so need to limit them after augmentation if directly predict radian offset.