pyannote-audio
 pyannote-audio copied to clipboard
pyannote-audio copied to clipboard
Using Noise-reduce before infernce increases DER
Hi,
Thanks for the repo.
I was trying to remove noise and background clutter from audio before putting it into the Speaker Diarization pipeline so that VAD can easily get speaker turns. But i think due to the difference in rttm ground truth file an hypothesis generated different timestamps, the DER seems to increase. Any idea why this happens and how to go about removing noise?
If not this, any pre processing step to improve DER?
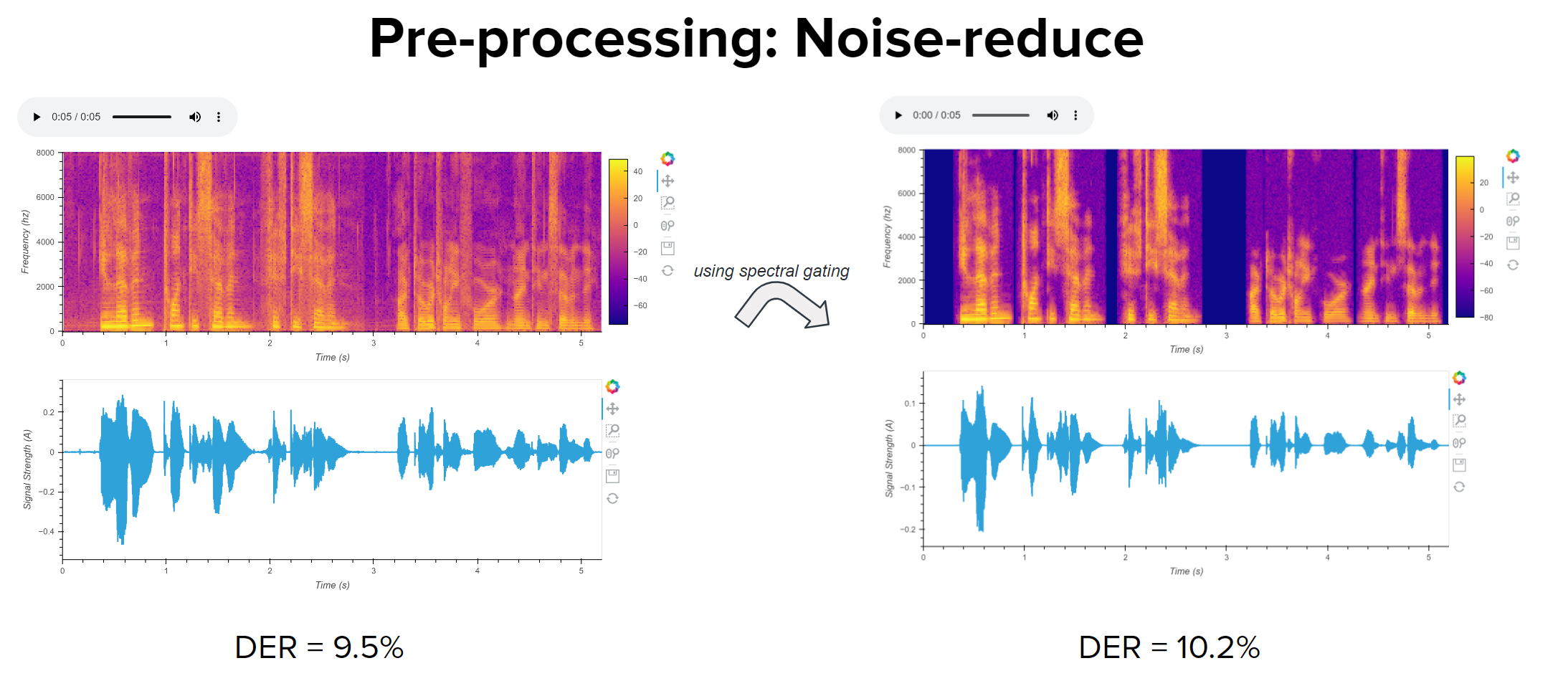
Any idea why this happens and how to go about removing noise?
It most likely happens because of a mismatch between (original) training data and (denoised) test data. Denoising will inevitably generate artifacts that have never been seen during training -- resulting in a larger mismatch between training and test data.
If not this, any pre processing step to improve DER?
Any pre-processing will most likely have the same issue. I usually recommend to fine-tune the model to the target domain instead.
Thanks for the clarification! Also Fine tuning the model would mean fine tune all the three models seperately right and then using in the pipeline? Or is there some way to fine tune on my dataset the entire pipeline in one go?
Closing as I think the original question has been answered. Please open a new issue for other questions (but please read existing open & closed issues beforehand, and also read the FAQ section of the main README)