Articles
 Articles copied to clipboard
Articles copied to clipboard
经验文章
# 01 引言 随着前端系统的越发复杂,前端的性能也受到越来越多的重视。Google 也不断在推进新的性能相关指标,从原先的 Performance API 中的指标逐步演进成用户性能体验相关的指标。  对于用户而言,First Paint、First Meaningful Paint 和 TTI 这几个指标可以直接影响到用户体验。关于前端性能优化有非常多的最佳实践可以参考,这篇文章会重点介绍前端渲染的方案及其优劣。 # 02 CSR vs SSR **CSR:Client Side Rendering**  浏览器(Client)渲染顾名思义就是所有的页面渲染、逻辑处理、页面路由、接口请求均是在浏览器中发生。其实,现代主流的前端框架均是这种渲染方式,这种渲染方式的好处在于实现了前后端架构分离,利于前后端职责分离,并且能够首次渲染迅速有效减少白屏时间。同时,CSR可以通过在打包编译阶段进行预渲染或者骨架屏生成,可以进一步提升首次渲染的用户体验。 但是由于和服务端会有多次交互(获取静态资源、获取数据),同时依赖浏览器进行渲染,在移动设备尤其是低配设备上,首屏时间和完全可交互时间是比较长的。 **SSR:Server Side Rendering**...
来源: [阮一峰 ](http://www.ruanyifeng.com/) https://www.ruanyifeng.com/blog/2018/01/assembly-language-primer.html 学习编程其实就是学高级语言,即那些为人类设计的计算机语言。 但是,计算机不理解高级语言,必须通过编译器转成二进制代码,才能运行。学会高级语言,并不等于理解计算机实际的运行步骤。 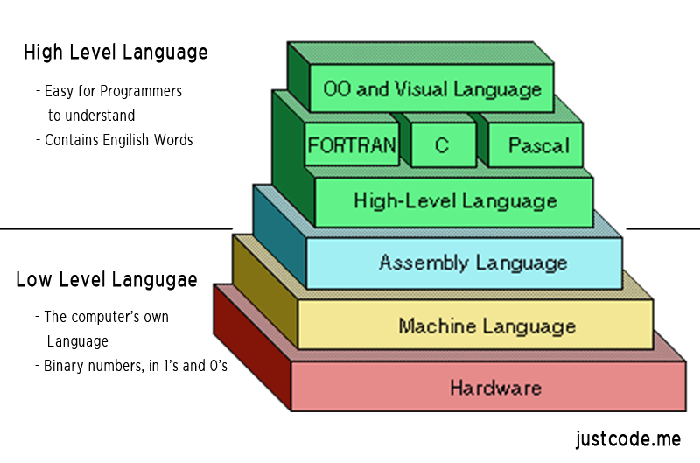 计算机真正能够理解的是低级语言,它专门用来控制硬件。汇编语言就是低级语言,直接描述/控制 CPU 的运行。如果你想了解 CPU 到底干了些什么,以及代码的运行步骤,就一定要学习汇编语言。 汇编语言不容易学习,就连简明扼要的介绍都很难找到。下面我尝试写一篇最好懂的汇编语言教程,解释 CPU 如何执行代码。  ## 一、汇编语言是什么? 我们知道,CPU 只负责计算,本身不具备智能。你输入一条指令(instruction),它就运行一次,然后停下来,等待下一条指令。 这些指令都是二进制的,称为操作码(opcode),比如加法指令就是`00000011`。[编译器(compiler)](http://www.ruanyifeng.com/blog/2014/11/compiler.html)的作用,就是将高级语言写好的程序,翻译成一条条操作码。而[解释器(Interpreter)](https://baike.baidu.com/item/%E8%A7%A3%E9%87%8A%E5%99%A8),又译为直译器,是一种电脑程序,能够把高级编程语言一行一行直接转译运行。 对于人类来说,二进制程序是不可读的,根本看不出来机器干了什么。为了解决可读性的问题,以及偶尔的编辑需求,就诞生了汇编语言。  **汇编语言是二进制指令的文本形式**,与指令是一一对应的关系。比如,加法指令`00000011`写成汇编语言就是 ADD。只要还原成二进制,汇编语言就可以被 CPU 直接执行,所以它是最底层的低级语言。 ## 二、来历 最早的时候,编写程序就是手写二进制指令,然后通过各种开关输入计算机,比如要做加法了,就按一下加法开关。后来,发明了纸带打孔机,通过在纸带上打孔,将二进制指令自动输入计算机。...
### 先从一个例子讲起 ```javascript var number1 = 10000000000000000000000000 + 11111111111111111111111111 //理论上number1的值应该是21111111111111111111111111(javascript中会表示为科学计数法:2.111111111111111e+25) var number2 = 21111111111111111111111000 console.log(number1 === number2) //true ``` 这个不用算简单看一下都知道计算结果不对,最后几位肯定应该都是1的,可是为什么会得到一个不对的值呢? ### JavaScript Number的精度丢失问题 因为`JavaScript`的`Number`类型是遵循 [IEEE 754](https://en.wikipedia.org/wiki/IEEE_floating_point) 规范表示的,这就意味着`JavaScript`能精确表示的数字是有限的,`JavaScript`可以精确到个位的最大整数是9007199254740992,也就是2的53次方,超过这个范围就会精度丢失,造成`JavaScript`无法判断大小,从而会出现下面的现象: ```js Math.pow(2, 53);...
当有两个整数 a 和 b ,在通常情况下我们有“+”运算符对其进行相加运算: ``` let sum = a + b; ``` 但是 JS 在存放整数的时候是有一个安全范围的,一旦数字超过这个范围便会损失精度。 我们不能拿精度损失的数字进行运行,因为运算结果一样是会损失精度的。 所以,我们要用字符串来表示数据!(不会丢失精度) JS 中整数的最大安全范围可以查到是:9007199254740991 假如我们要进行 9007199254740991 + 1234567899999999999 我们要先准备两个字符串变量和一个方法: ``` const a = "9007199254740991"...
Bumps [path-parse](https://github.com/jbgutierrez/path-parse) from 1.0.6 to 1.0.7. Commits See full diff in compare view [](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores) Dependabot will resolve any conflicts with this PR as long as you don't alter...
关系型数据库最难的地方,就是建模(model)。 错综复杂的数据,需要建立模型,才能储存在数据库。**所谓"模型"就是两样东西:实体(entity)+ 关系(relationship)。** 实体指的是那些实际的对象,带有自己的属性,可以理解成一组相关属性的容器。关系就是实体之间的联系,通常可以分成"一对一"、"一对多"和"多对多"等类型。  在关系型数据库里面,每个实体有自己的一张表(table),所有属性都是这张表的字段(field),表与表之间根据关联字段"连接"(join)在一起。所以,表的连接是关系型数据库的核心问题。 表的连接分成好几种类型。 > - 内连接(inner join) > - 外连接(outer join) > - 左连接(left join) > - 右连接(right join) > - 全连接(full join) 以前,很多文章采用[维恩图](https://blog.codinghorror.com/a-visual-explanation-of-sql-joins/)(两个圆的集合运算),解释不同连接的差异。 ...
所有应用软件之中,数据库可能是最复杂的。 MySQL的手册有3000多页,PostgreSQL的手册有2000多页,Oracle的手册更是比它们相加还要厚。  但是,自己写一个最简单的数据库,做起来并不难。Reddit上面有一个[帖子](https://www.reddit.com/r/Database/comments/27u6dy/how_do_you_build_a_database/ciggal8),只用了几百个字,就把原理讲清楚了。下面是我根据这个帖子整理的内容。 ## 一、数据以文本形式保存 第一步,就是将所要保存的数据,写入文本文件。这个文本文件就是你的数据库。 为了方便读取,数据必须分成记录,每一条记录的长度规定为等长。比如,假定每条记录的长度是800字节,那么第5条记录的开始位置就在3200字节。 大多数时候,我们不知道某一条记录在第几个位置,只知道[主键](https://zh.wikipedia.org/zh/关系键)(primary key)的值。这时为了读取数据,可以一条条比对记录。但是这样做效率太低,实际应用中,数据库往往采用[B树](https://en.wikipedia.org/wiki/B-tree)(B-tree)格式储存数据。 ## 二、什么是B树? 要理解B树,必须从[二叉查找树](https://zh.wikipedia.org/wiki/二元搜尋樹)(Binary search tree)讲起。 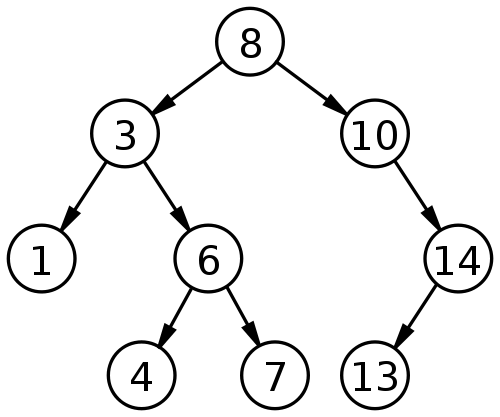 二叉查找树是一种查找效率非常高的数据结构,它有三个特点。 > (1)每个节点最多只有两个子树。 > > (2)左子树都为小于父节点的值,右子树都为大于父节点的值。 > > (3)在n个节点中找到目标值,一般只需要log(n)次比较。 二叉查找树的结构不适合数据库,因为它的查找效率与层数相关。越处在下层的数据,就需要越多次比较。极端情况下,n个数据需要n次比较才能找到目标值。对于数据库来说,每进入一层,就要从硬盘读取一次数据,这非常致命,因为硬盘的读取时间远远大于数据处理时间,数据库读取硬盘的次数越少越好。 B树是对二叉查找树的改进。它的设计思想是,将相关数据尽量集中在一起,以便一次读取多个数据,减少硬盘操作次数。 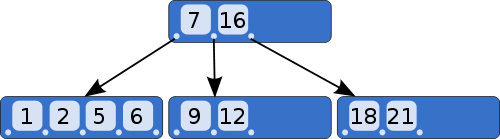 B树的特点也有三个。 >...
React :元素构成组件,组件又构成应用。 React 核心思想是组件化,其中**组件**通过属性 (props) 和 状态 (state) 传递数据。 ## State 与 Props 区别 props 是组件对外的接口,state 是组件对内的接口。组件内可以引用其他组件,组件之间的引用形成了一个树状结构(组件树),如果下层组件需要使用上层组件的数据或方法,上层组件就可以通过下层组件的 props 属性进行传递,因此 props 是组件对外的接口。组件除了使用上层组件传递的数据外,自身也可能需要维护管理数据,这就是组件对内的接口 state。根据对外接口 props 和对内接口state,组件计算出对应界面的 UI。 主要区别: - State 是可变的,是一组用于反映组件UI变化的状态集合; -...
# iOS 模拟器调试 `Hybrid App`(混合模式移动应用)`iOS` 应用使用 `WKWebView` 进行 `weapp` 页面渲染, 如何多机型调试 `WKWebView` 渲染的 `weapp` 页面呢?可以通过 `iOS` 模拟器模拟多机型进行调试。 ## **一. 安装 & 启动** ### 安装 Xcode - 通过 [苹果开发者网站](https://developer.apple.com/xcode/) 下载 `Xcode`...
## 前言 无论高级语言,还是低级语言。内存的管理都是: 1. 内存分配:申明变量、函数、对象,系统会自动分配内存 2. 内存使用:读写内存,使用变量、函数等 3. 内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存 释放内存处理方式,各种语言都有自己的垃圾回收(garbage collection, 简称GC)机制。做GC的第一步是判断堆中存的是数据还是指针,是指针的话,说明它被指向活跃的对象。有3种判断方法: 1. `Conservative`:存储格式是地址,`C/C++`有用到这种算法。 2. `Compiler hints`:对于静态语言,比如`Java`,编译器是知道它是不是指针的,所以可以用这种。 3. `Tagged pointers`:`JavaScript`用的是这种,在字末位进行标识,1为指针。 ## JavaScript 内存问题 ### 内存泄漏 什么情况下会内存泄漏 `memory leak ` ?可以这么理解,就是有些代码本来应该要被回收的,但是没有被回收,所以一直占用着操作系统的内存,从而越积越多。一般的内存泄漏其实无关紧要,可怕的是内存泄漏引起的堆积,导致GC一直没办法使用所占用的内存给其他程序使用。...